- The paper introduces the CoUR framework to decompose and refine reward functions in RL by quantifying uncertainty in generated reward components.
- The paper employs a three-stage process—LLM-based generation, Code Uncertainty Quantification, and Bayesian Decoupling Optimization—to reduce computational costs and improve convergence.
- The paper demonstrates notable performance gains on IsaacGym and Bidexterous Manipulation tasks, underscoring the benefits of uncertainty-aware, modular reward design.
Chain of Uncertain Rewards with LLMs for Reinforcement Learning
Motivation and Challenges in Reward Design
Designing reward functions in RL remains a bottleneck, primarily due to the manual and trial-and-error nature of the process, which yields redundancy, inconsistency, and high computational costs. Traditional methods treat reward functions as monolithic structures, rarely addressing local uncertainties at intermediate decision points or decomposing complex objectives. Recent LLM-driven approaches (L2R, Eureka, Text2Reward) enable automated and interpretable reward design but fail to mitigate local ambiguities and component redundancy, leading to suboptimal task performance and inefficient computation.
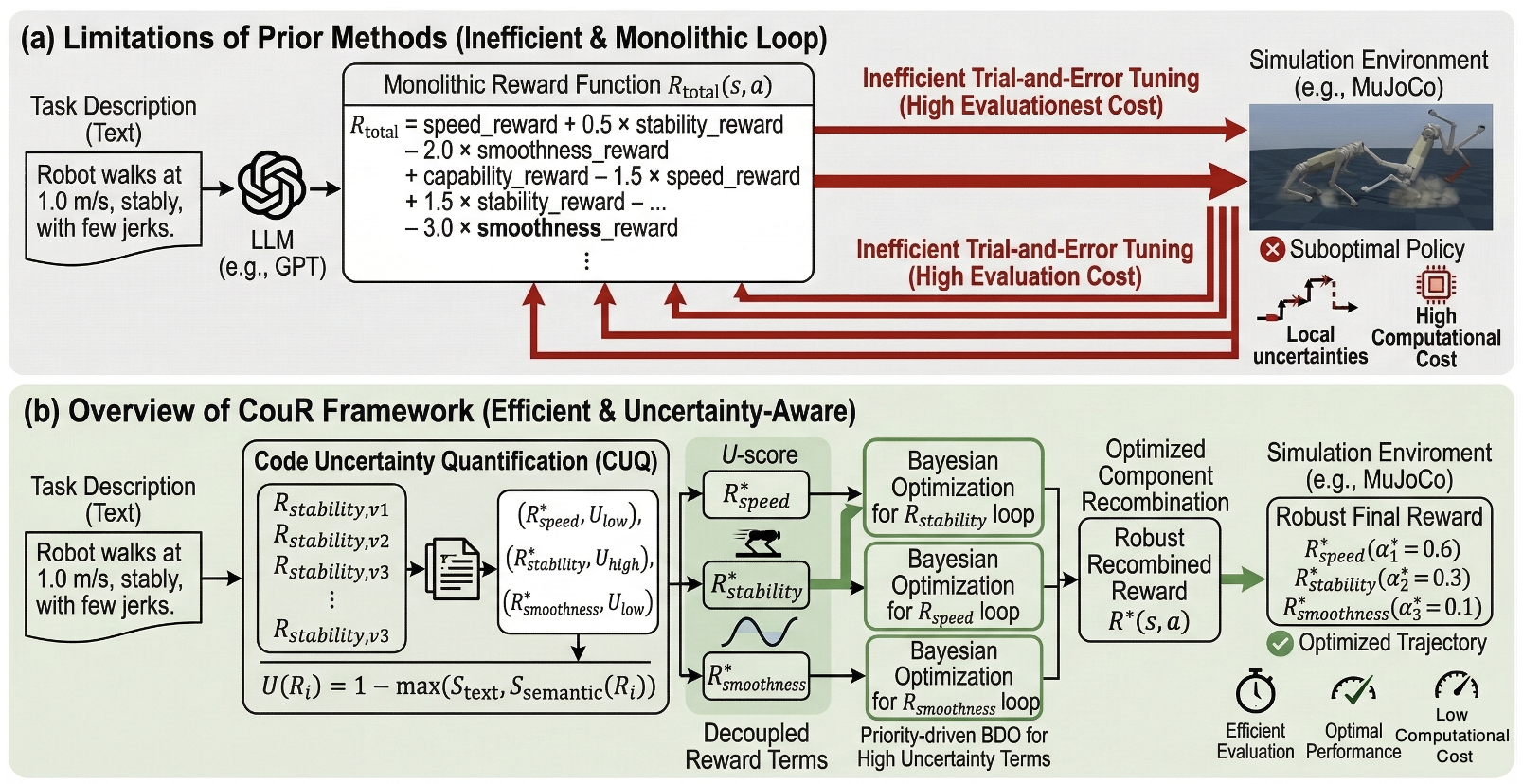
Figure 1: LLM-based reward function optimization suffers from local uncertainties, redundancy, and computational inefficiency that the Chain of Uncertain Rewards framework aims to resolve.
Chain of Uncertain Rewards Framework
The Chain of Uncertain Rewards (CoUR) framework introduces a structured pipeline to streamline reward design and optimization in RL. The pipeline actively quantifies uncertainty in reward code and decouples reward components for independent optimization. The framework operates in three stages:
- LLM-Based Reward Generation: Given a task description, an LLM synthesizes a multi-term reward function, leveraging language understanding and code generation capabilities.
- Code Uncertainty Quantification (CUQ): CUQ analyzes generated reward components through textual and semantic similarity (employing string matching and CodeBERT-style embeddings), assigning uncertainty scores (U-scores) to ambiguous or redundant terms. Components with high U-scores are prioritized for alternative generation and clarification, ensuring robustness and interpretability.
- Bayesian Decoupling Optimization (BDO): Reward terms are decoupled, and their hyperparameters are optimized independently using Bayesian optimization. BDO exploits U-scores to guide global search, prioritizing highly uncertain components for exploration, thus accelerating convergence and reducing computational, rollout, and evaluation overhead.
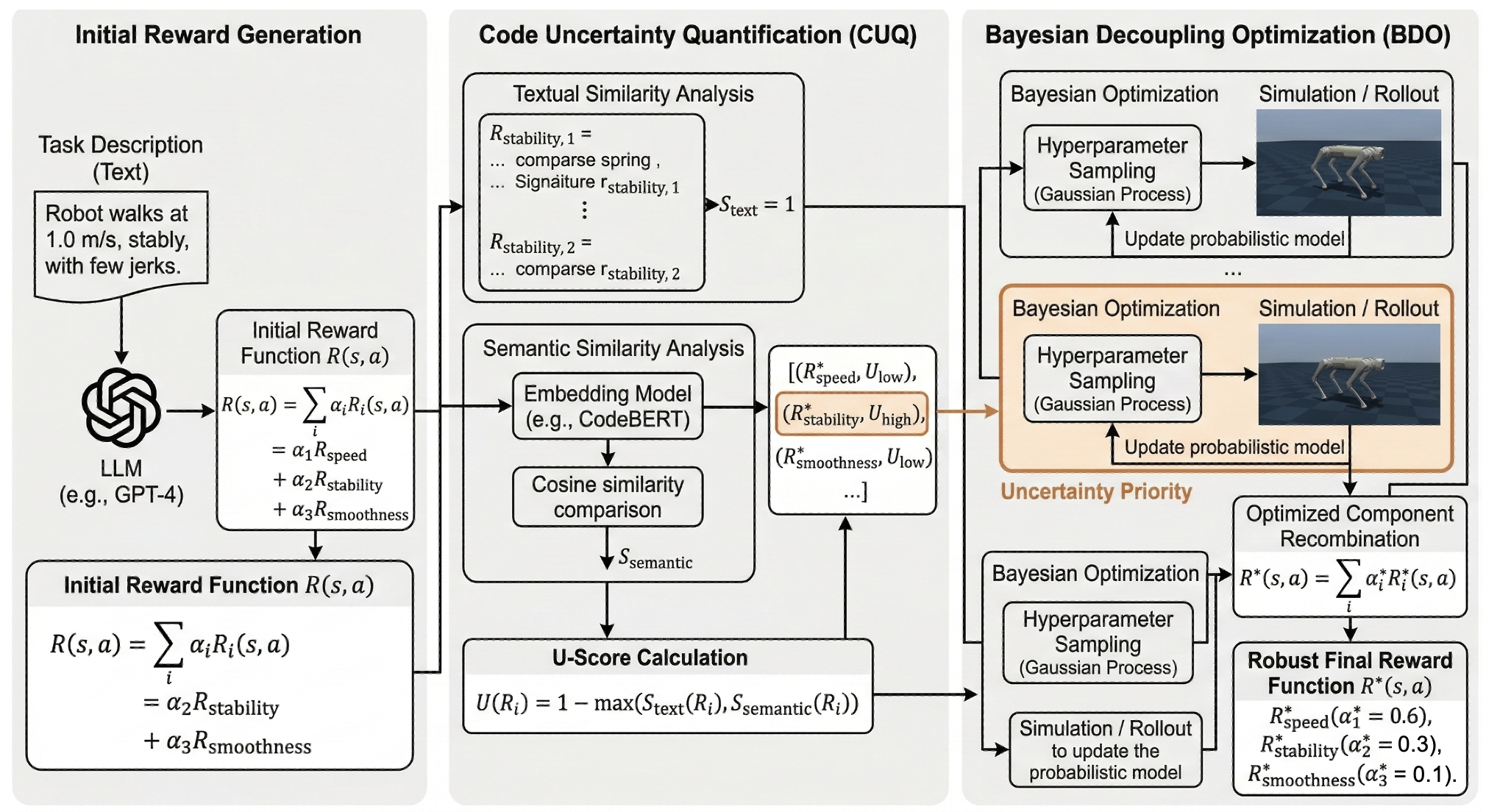
Figure 2: The CoUR pipeline integrates LLM-based reward generation, CUQ-driven component refinement, and decoupled Bayesian optimization for robust RL reward design.
Technical Methodology
RL tasks are formalized as MDPs; reward generation maps task descriptions to mathematical expressions controlling agent behavior. The CoUR pipeline decomposes reward functions as R(s,a)=∑iαiRi(s,a), with αi as component weights. CUQ utilizes string and embedding-based metrics to determine U(Ri)=1−max(Stext,Ssemantic), refining high-U components via LLMs.
BDO separately optimizes each reward term's hyperparameters using Gaussian Process-based Bayesian search, tracing objective functions J(Ri) and recombining optimized terms for final reward synthesis. The integration of CUQ and BDO allows guided exploration and global search efficiency, as ambiguity-driven prioritization reduces redundant code evaluation.
Empirical Evaluation
CoUR is validated across nine IsaacGym environments and twenty Bidexterous Manipulation benchmark tasks. Metrics include human normalized scores and binary success rates. CoUR delivers strong numerical improvements, outperforming Text2Reward, Eureka, L2R, sparse and human-engineered baselines:
- IsaacGym: CoUR achieves a normalized score of 5.62, compared to 2.78 (Text2Reward), 2.66 (Eureka), and 1.00 (human baseline).
- Bidexterous Manipulation: CoUR scores a 65.63% success rate versus 56.87% (Text2Reward) and 45.90% (human baseline).
Ablation studies address three critical questions:
- Decoupling and Optimization: Decoupled BDO improves normalized score and success rate up to 12.4% and 8.7% respectively over monolithic optimization.
- Efficiency of CUQ: CUQ reduces training iterations by 20%, focusing evaluation on high-uncertainty reward terms.
- BO vs. LLM-only: Bayesian Optimization converges 35% faster and requires 25% less computation than direct LLM-based hyperparameter tuning.
Sampling step analysis in BDO shows performance saturation at 5 steps, balancing computational cost and reward effectiveness.
Practical and Theoretical Implications
CoUR demonstrates that modular, uncertainty-aware reward design is scalable and generalizable across diverse robotic morphologies and manipulation scenarios. The decomposition and prioritization strategy allow RL researchers to automate complex reward specification, minimize redundant evaluation, and systematically refine ambiguous or conflicting reward terms. The incorporation of uncertainty quantification in reward design sets a precedent for interpretable RL pipeline engineering, potentially advancing safe deployment in high-stakes environments and accelerating experimentation cycles.
On a theoretical front, CoUR highlights the synergy between LLMs, uncertainty quantification, and Bayesian optimization, opening new avenues in hierarchical RL reward construction and automated RL pipeline design. It suggests future integration of advanced LLM reasoning (e.g., Chain-of-Thought, semantic deliberation), structured hyperparameter search, and, potentially, self-adaptive reward shaping via continuous uncertainty tracking.
Conclusion
The Chain of Uncertain Rewards delivers a systematic, robust framework for automated reward function design in RL, combining LLM-based synthesis, uncertainty quantification, and decoupled Bayesian optimization. Its state-of-the-art empirical performance, efficiency improvements, and modular methodology hold broad implications for scalable and interpretable RL solutions. The approach provides a foundation for further research in uncertainty-aware reward shaping, component-level optimization, and automatic pipeline design in reinforcement learning.