- The paper presents BinomGBML, which leverages a truncated binomial expansion to compute meta-gradients with reduced computational cost.
- It achieves super-exponential error decay, enabling faster convergence and improved estimation accuracy over methods like TruncMAML.
- Empirical results on sinusoid regression and few-shot image classification demonstrate enhanced performance with lower memory and time requirements.
Overview
The paper "Binomial Gradient-Based Meta-Learning for Enhanced Meta-Gradient Estimation" (2604.13263) addresses the computational limitations of gradient-based meta-learning (GBML) algorithms, particularly Model-Agnostic Meta-Learning (MAML). The authors introduce Binomial Gradient-Based Meta-Learning (BinomGBML), a meta-gradient estimator leveraging a truncated binomial expansion to enhance both parallelism and accuracy in meta-gradient computation, promising improved error rates and scalability.
Background and Problem Motivation
GBML frameworks, such as MAML, adapt a shared task-invariant initialization by running gradient descent (GD) on new tasks, aiming to enable rapid adaptation under scarce data regimes. However, the full backpropagation required to compute meta-gradients incurs high computational costs, scaling linearly in both memory and time with the number of inner optimization steps. First-order approximations (e.g., FOMAML, Reptile) and truncated backpropagation (TruncMAML) alleviate this burden, but often at the expense of sharply increased meta-gradient estimation errors, resulting in slower meta-training convergence and reduced downstream efficacy. Implicit approaches (iMAML) further introduce numerical instability stemming from the nontrivial approximation of Hessian-vector products.
To address the aforementioned trade-offs, BinomGBML reformulates the meta-gradient computation using a truncated binomial expansion:
k=0∏K−1[Id−αHtk]≈Id+l=1∑L0≤k1:l↑<K∑i=1∏l(−αHtki)
Here, Htk denotes the Hessian at adaptation step k, and gtK is the validation gradient after K GD steps. Truncating the expansion at L yields a parallelizable estimator that retains more information per computational unit than TruncMAML. Each vector operator arising in the expansion, as formalized in Proposition 3.1 and Theorem 3.2, encapsulates a set of Hessian-vector products (HVPs) that can be independently computed, enabling efficient GPU utilization.
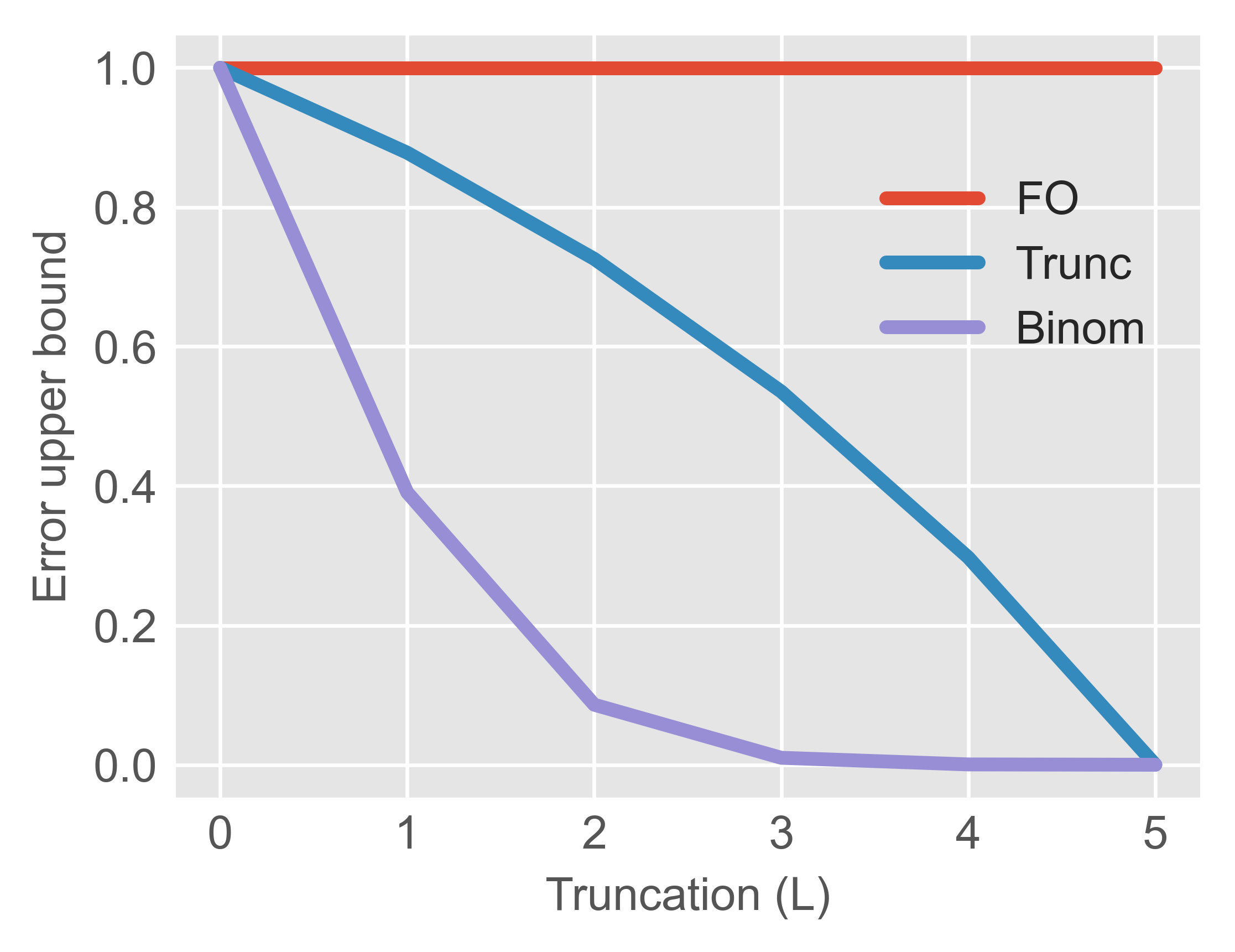
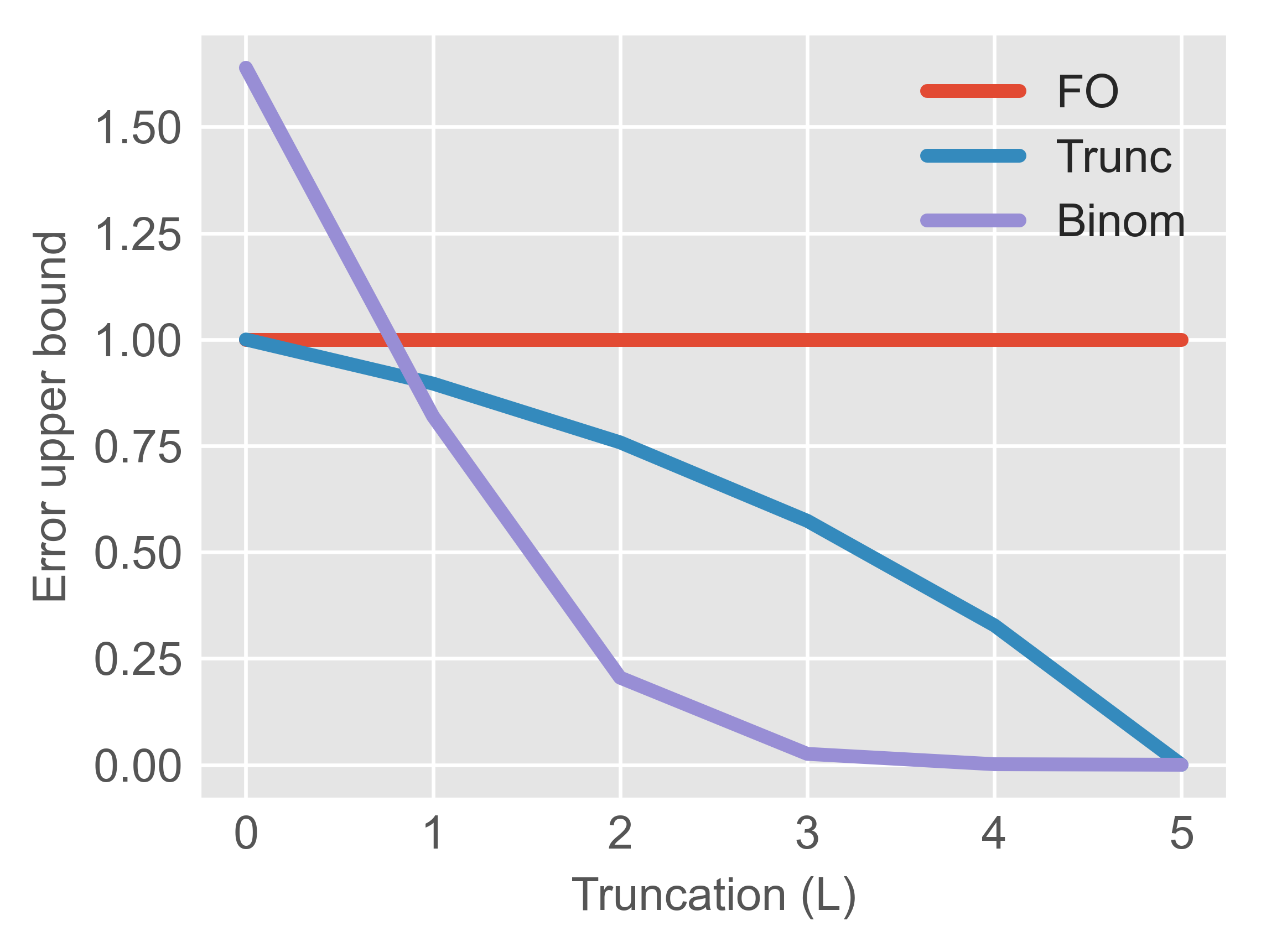
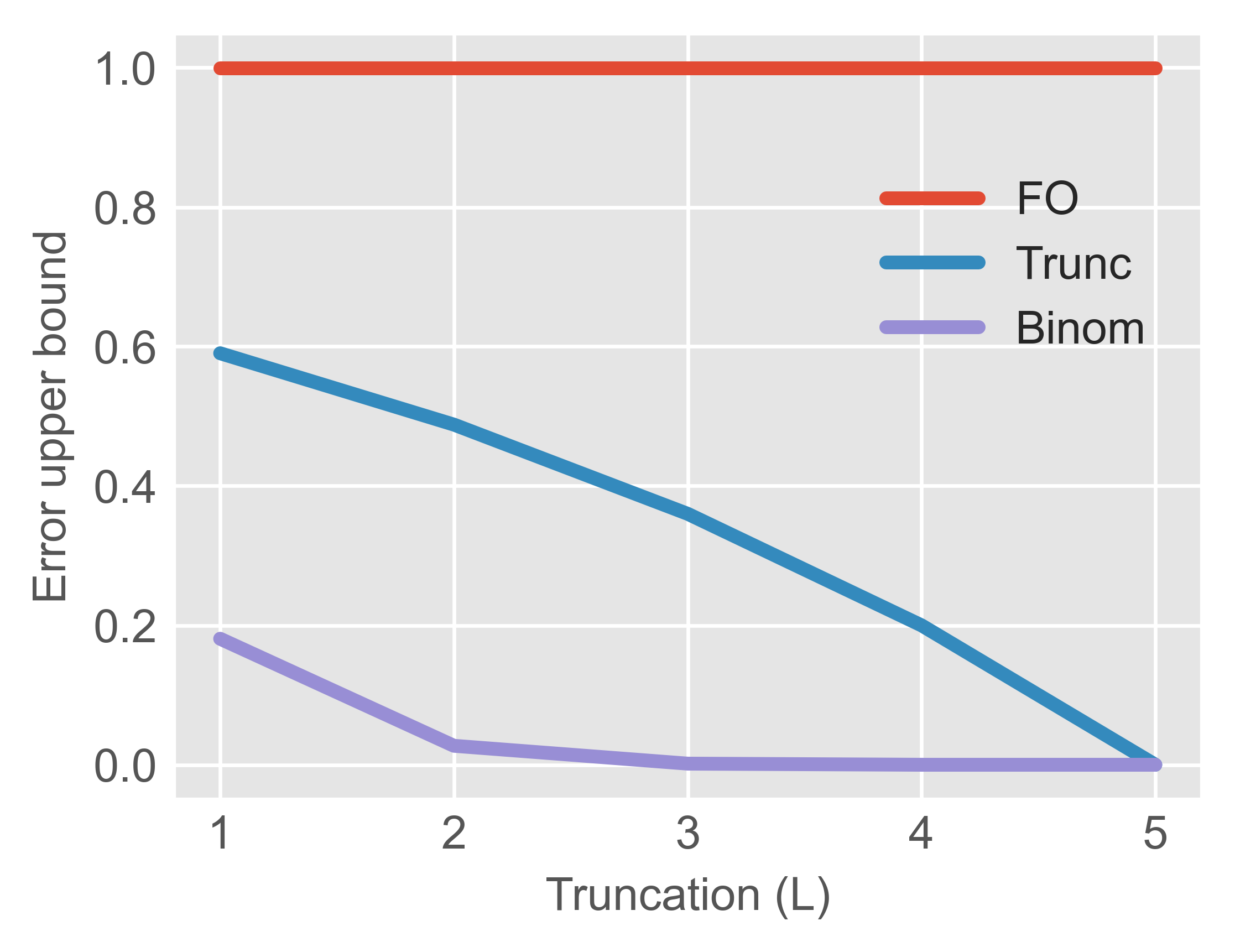
Figure 1: Operator diagram for the BtgtK,L−l binomial vector operator, illustrating GPU-parallelizable HVP structure.
The algorithm trades a marginal increase in parallel compute (requiring K−L+1 parallel HVPs per operator) for super-exponential error reduction as L increases, as established by the derived theoretical bounds.
Theoretical Analysis
The paper presents non-asymptotic upper bounds on the meta-gradient estimation error for FOMAML, TruncMAML, and BinomMAML, under three common conditions: Lipschitz smoothness, (global) convexity, and local strong convexity. For the smooth case (Theorem 3.3), the error bound for BinomMAML scales as:
∥∇Lt(θ)−BiLt(θ)∥≤l=L+1∑K(lK)(αH)l∥gtK∥
This decays super-exponentially with respect to Htk0, in contrast with TruncMAML, whose error decreases only polynomially. Analogous results for the convex and locally strongly convex regimes confirm that BinomGBML achieves strictly tighter bounds, justifying lower Htk1 values for comparable accuracy.
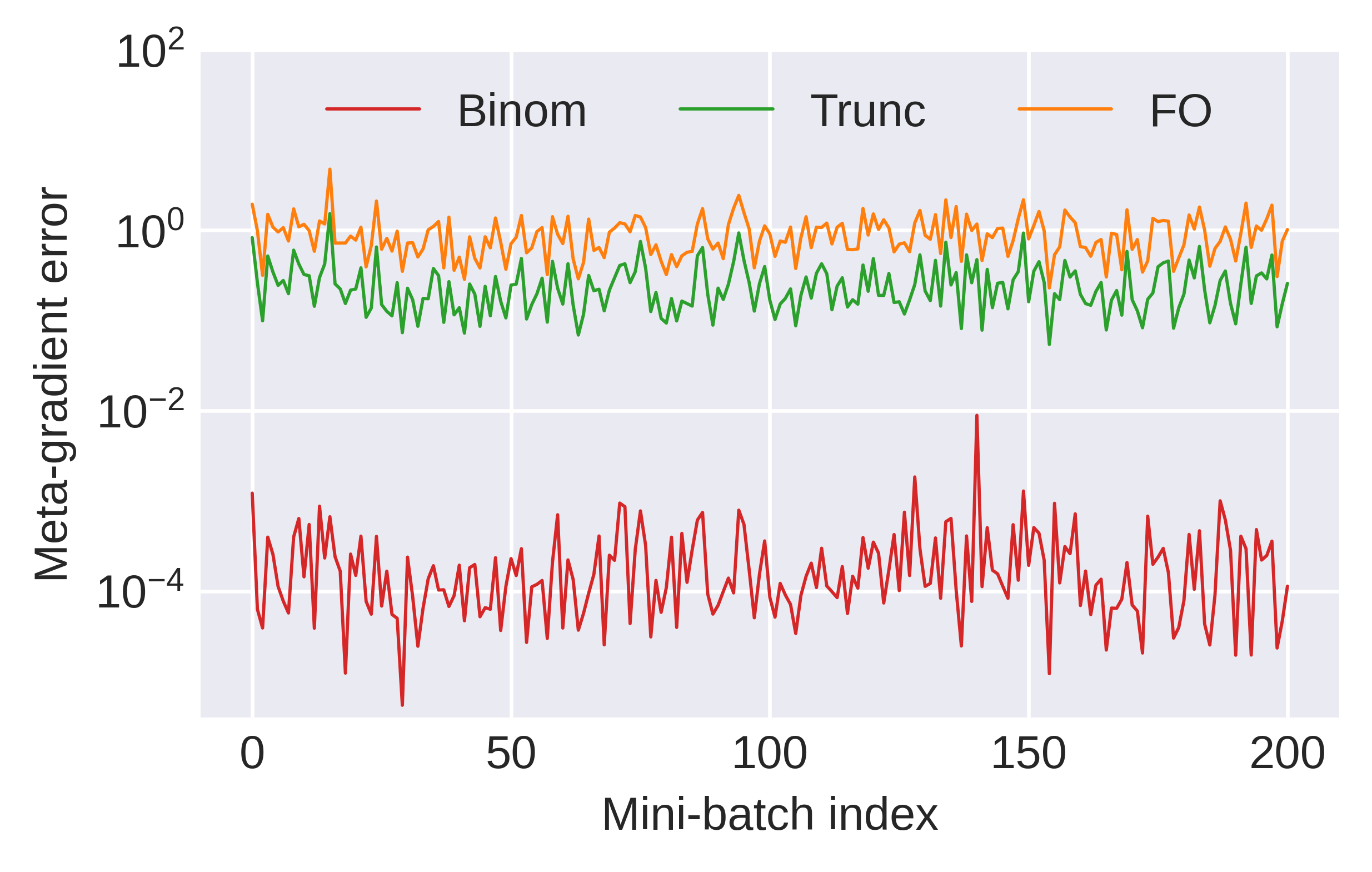
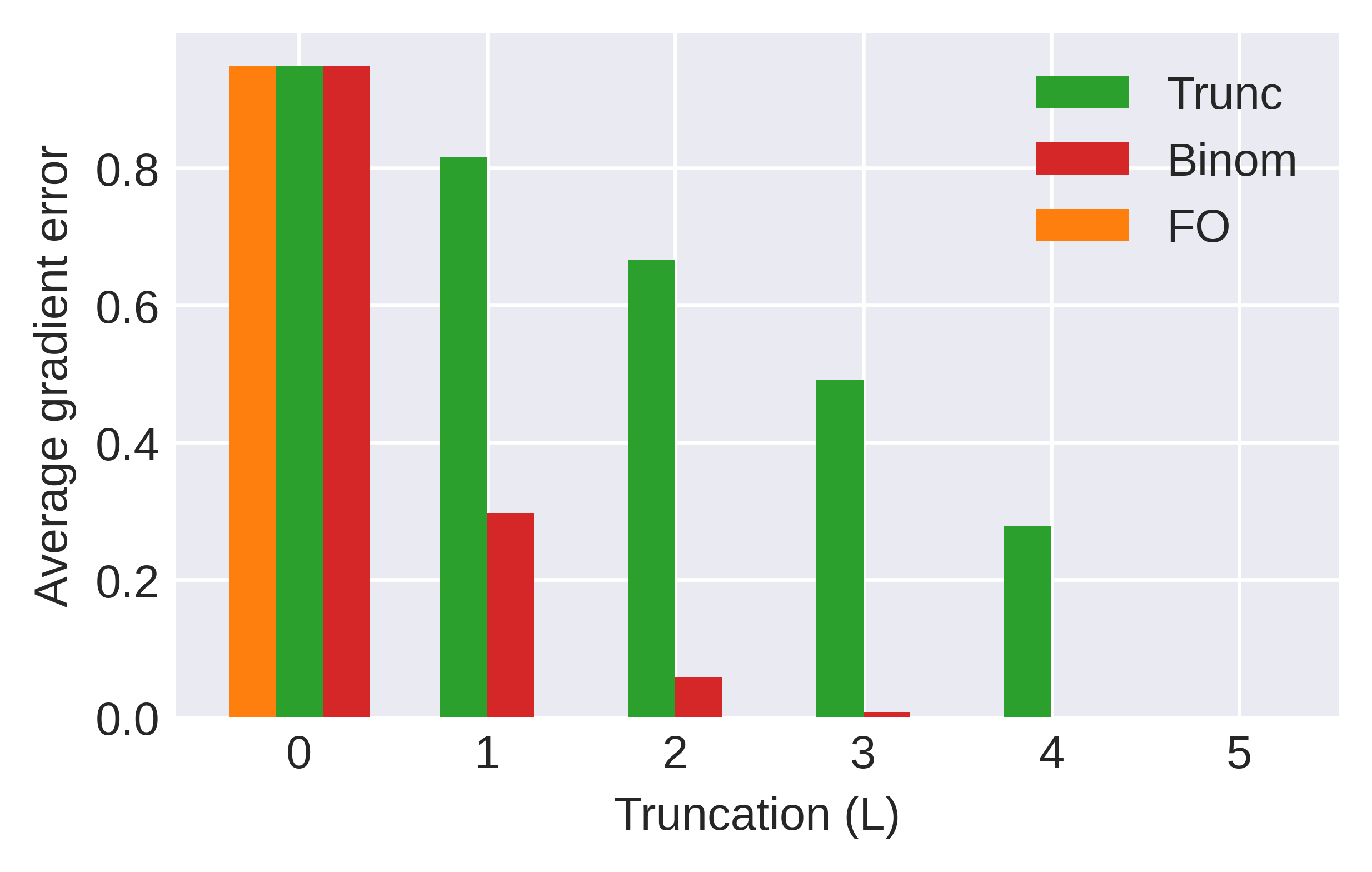
Figure 2: Analytical error bounds for FOMAML, TruncMAML, and BinomMAML as Htk2 varies, revealing super-exponential decay for BinomMAML.
Empirical Results
Synthetic Data: Sinusoid Regression
The first benchmark considers sinusoid regression, a standard few-shot meta-learning testbed. With a fixed truncation Htk3, BinomMAML's meta-gradient error remains orders of magnitude smaller than TruncMAML across random task batches.
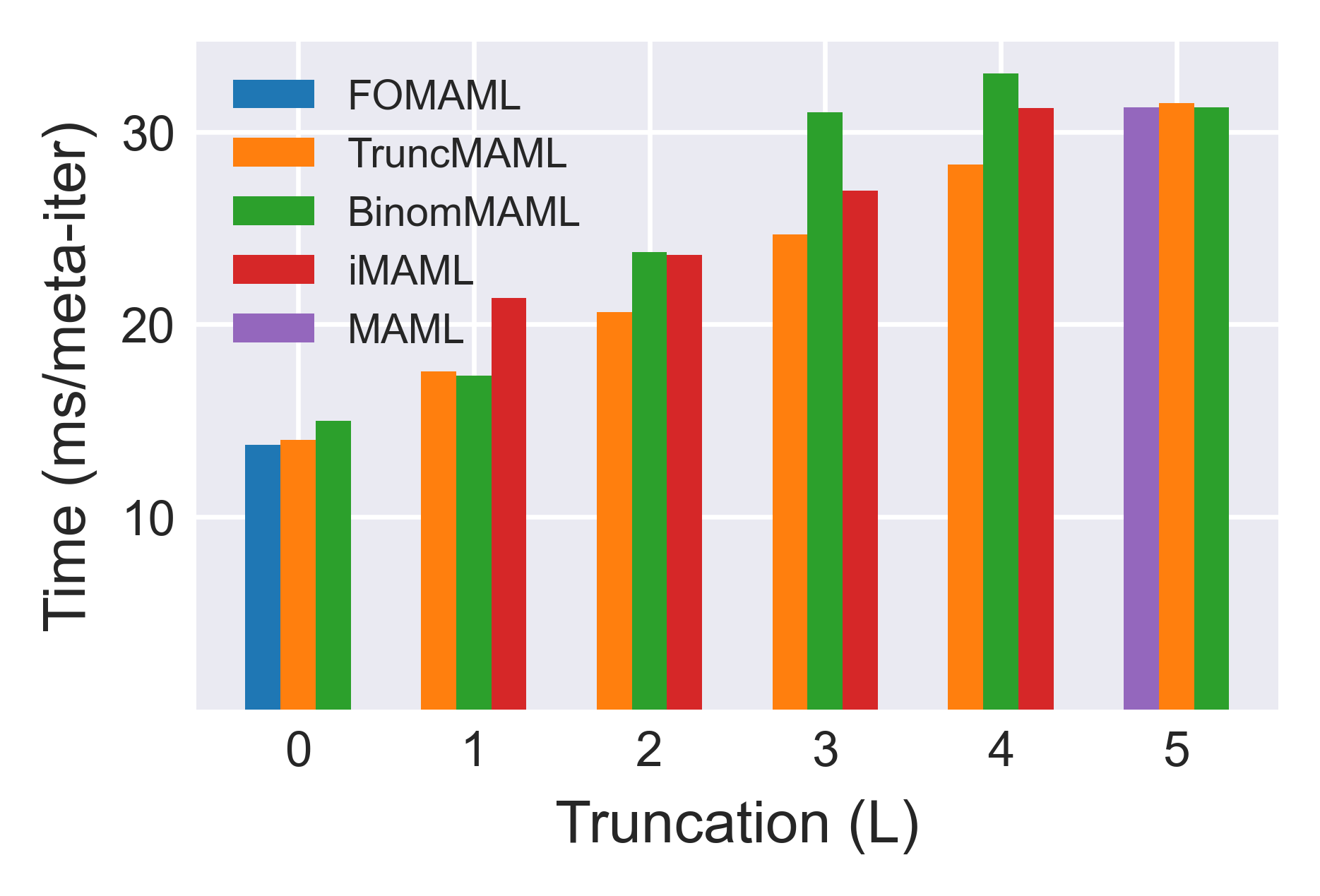
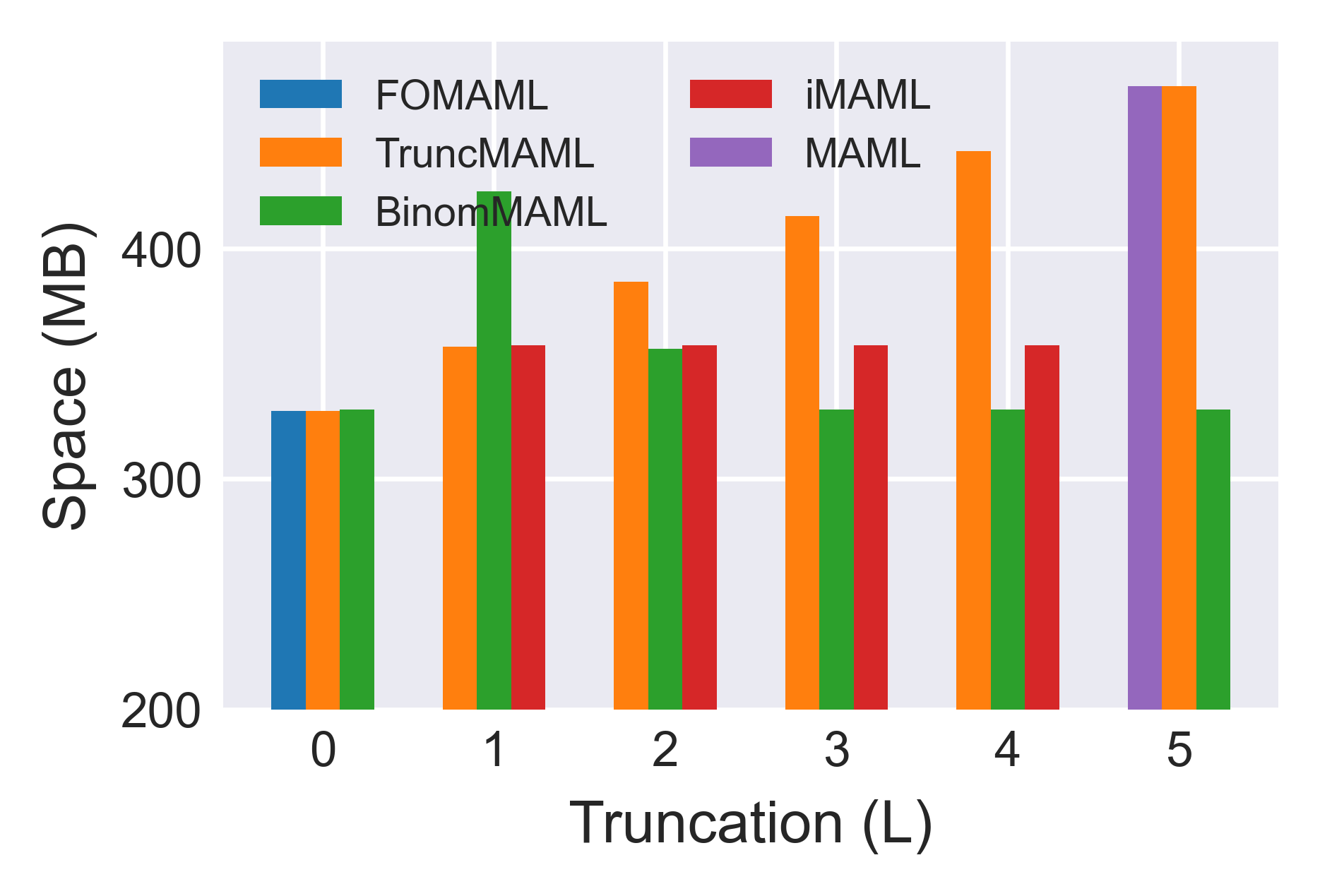
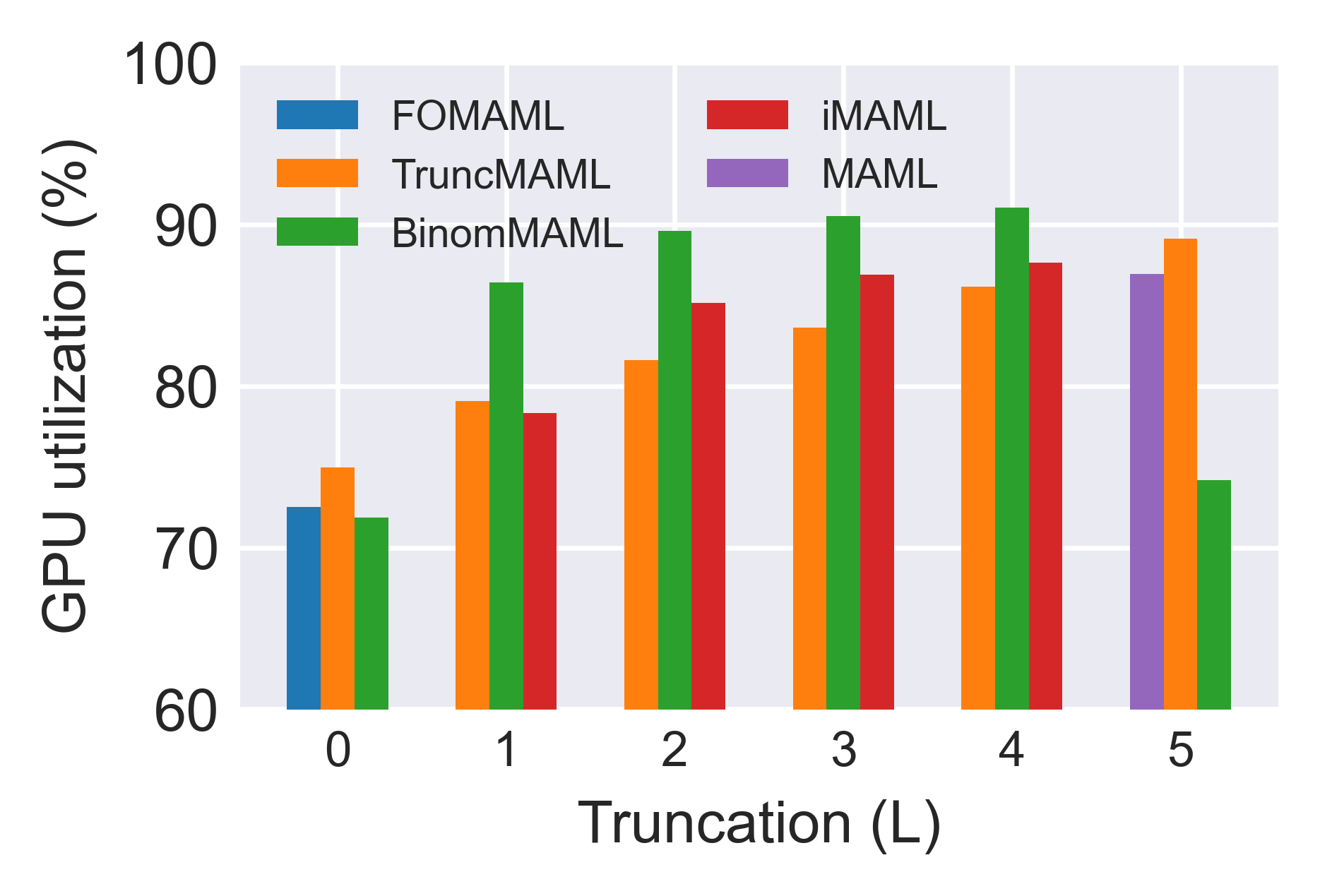
Figure 3: Meta-gradient estimation errors across a batch of tasks; BinomMAML sharply outperforms TruncMAML with matching truncation Htk4.
When sweeping Htk5, BinomMAML attains near-zero error with Htk6, while TruncMAML converges much slower, confirming the theoretical predictions regarding estimation efficiency.
Real Data: Few-Shot Image Classification
Evaluations on miniImageNet and tieredImageNet, using the standard 5-way, 1 or 5-shot protocol, validate BinomMAML's advantages in both data-scarce and moderate-data regimes. Early-stopped training reveals BinomMAML achieves higher accuracy than TruncMAML and iMAML for the same Htk7; in the low-data cases (1-shot), the advantage is more pronounced. As Htk8 increases, BinomMAML rapidly approaches MAML's performance with less computational and memory overhead.
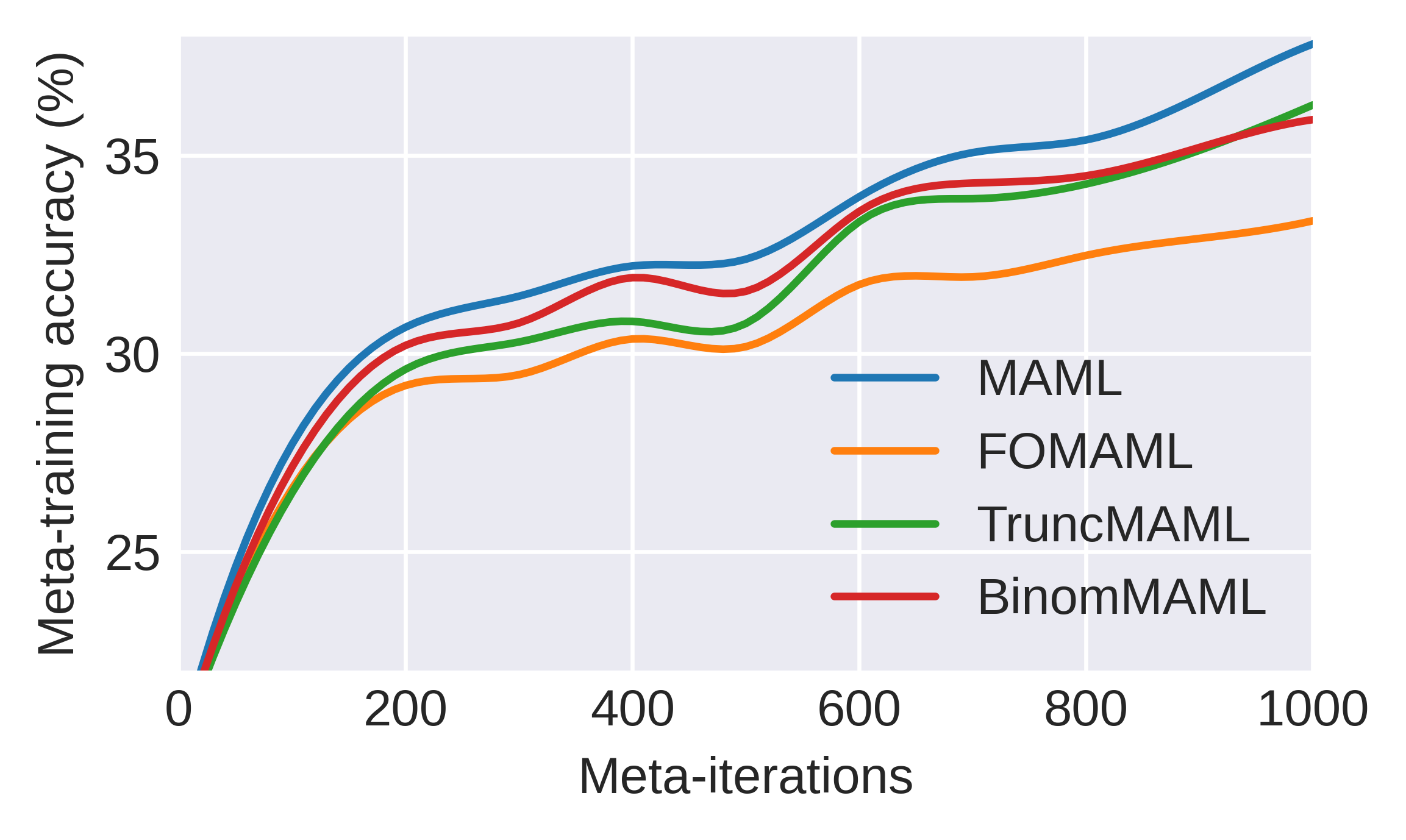
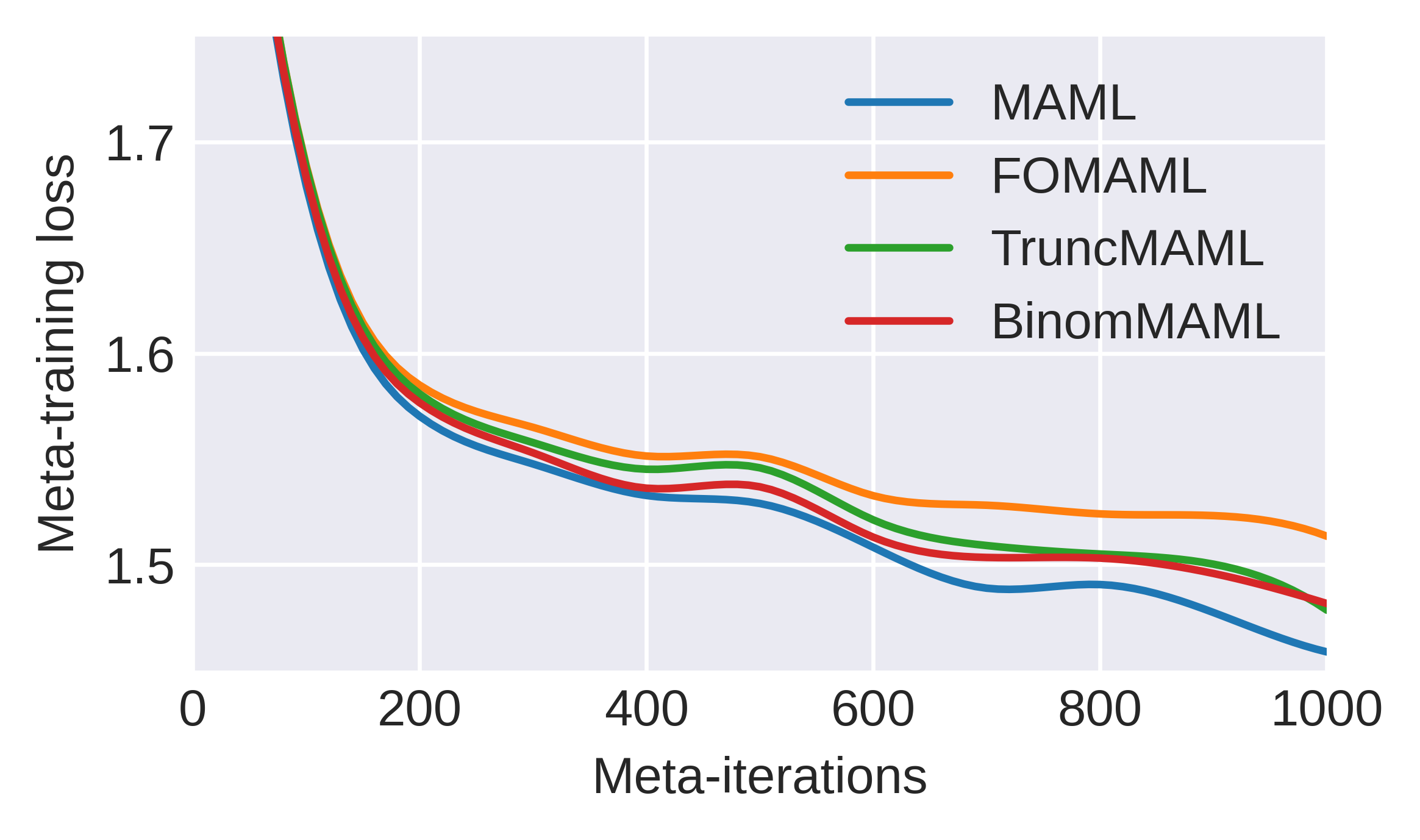
Figure 4: Training time, memory usage, and GPU utilization per meta-iteration across different Htk9. BinomMAML markedly reduces both time and memory relative to MAML, benefiting more from parallelism as k0 grows.
Model convergence curves on miniImageNet further demonstrate that BinomMAML aligns more closely with the strong baseline (full MAML) than alternatives of comparable complexity.
Algorithmic and Practical Implications
- Superior Error-Complexity Trade-off: BinomMAML's super-exponential error decay enables accurate meta-gradient estimation with shallow expansion (k1), reducing the number of serial operations and circumventing memory scaling issues of truncated or full backpropagation.
- Parallelization: The estimator is well-suited to contemporary parallel architectures (multi-core CPUs, GPUs), since all required HVPs within a given operator can be processed in parallel, a property not shared by TruncMAML.
- Memory Efficiency: Beyond reduced time-to-solution, BinomMAML releases memory associated with computational graphs on-the-fly, addressing MAML's explosive memory growth with k2.
- Robustness Across Data Regimes: Particularly in severely underdetermined (few-shot) settings, the improved estimation accuracy translates to tangible advances in both convergence speed and final classification/regression performance.
Theoretical and Practical Implications for AI
This work expands the admissible complexity of inner-loop optimization for GBML, allowing the use of longer adaptation steps without incurring prohibitive meta-gradient errors. This broadens the practical deployment of meta-learning, notably in contexts with extreme data scarcity, limited hardware, or stringent latency/memory constraints (e.g., edge computing, federated meta-learning, continual learning under resource budgets). The method is orthogonal and readily combinable with layer-wise adaptation strategies like ANIL, as well as hybrid estimators balancing truncation and binomial expansion for further flexibility.
Theoretically, the super-exponential error bounds suggest that deeper inner-loop adaptation horizons can be accurately meta-learned, enabling investigations into “deeper meta-adaptation” and stronger amortization of optimization experience across tasks.
Conclusion
The binomial gradient-based meta-learning estimator (BinomGBML) provides an efficient, parallelizable, and theoretically justified approach to meta-gradient estimation in GBML. By exploiting the binomial theorem’s structure for meta-gradient expansion, the method achieves rapid and controllable error decay with minimal increases in parallel compute usage and modest—often reduced—memory. Its empirical and analytical superiority over prior meta-gradient estimators positions BinomGBML as the foundation for next-generation scalable and accurate meta-learning algorithms across a broad range of practical and theoretical AI settings.