- The paper presents a collaborative multi-agent framework that enhances multimodal emotion recognition through targeted retrieval and adaptive evidence fusion.
- It utilizes multi-agent reinforcement learning with dedicated modules—Query Planner, Evidence Filter, and Emotion Generator—to address static memory limitations.
- Empirical results show significant performance gains and robustness with improvements up to +6.79 points even under missing modality conditions.
AffectAgent: Collaborative Multi-Agent Reasoning for Retrieval-Augmented Multimodal Emotion Recognition
Introduction and Motivation
Multimodal Emotion Recognition (MER) presents persistent challenges due to the intricate and implicit affective cues expressed through language, vision, and audio. While current Multimodal LLMs (MLLMs) achieve notable success via feature alignment in a unified semantic space, they remain fundamentally restricted by static parametric memory, often defaulting to language priors in ambiguous or conflicting multimodal scenarios—resulting in affect hallucinations. Although retrieval-augmented generation (RAG) seeks to address this limitation by incorporating external grounding evidence, conventional single-pass RAG pipelines lack capacity for nuanced, cross-modal and affect-oriented reasoning.
AffectAgent is introduced as an affect-centric, collaborative multi-agent framework for retrieval-augmented multimodal emotion understanding, precisely formulated to address these deficits. The design draws from multi-agent reinforcement learning and extends beyond traditional supervised or fact-driven RAG approaches, explicitly optimizing the retrieval, adjudication, and fusion of external affective evidence.
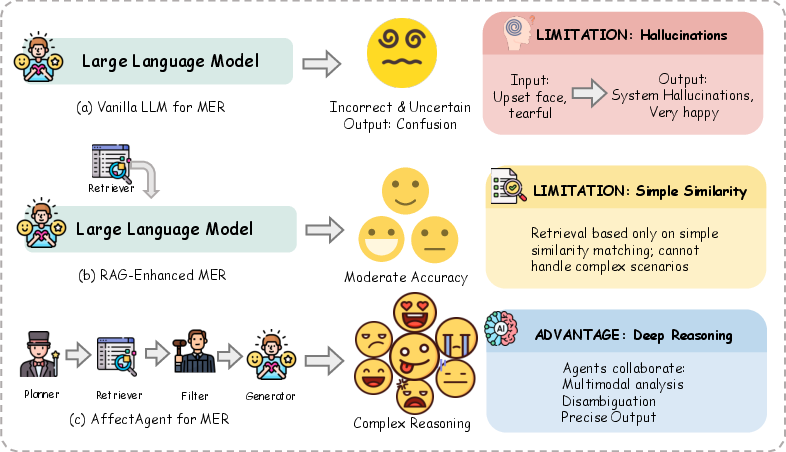
Figure 1: (a) Vanilla LLMs rely solely on static parametric memory, leading to challenges with nuanced emotion reasoning; (b) Traditional RAG follows a linear pipeline, failing on complex affective dependencies; (c) AffectAgent employs collaborative multi-agent reasoning for robust emotion recognition.
Framework Overview
AffectAgent integrates three agentic modules—a Query Planner, an Evidence Filter, and an Emotion Generator—made operational via collaborative multi-agent reinforcement learning. Each agent is implemented atop a shared MLLM (for computational efficiency), and is optimized using Multi-Agent Proximal Policy Optimization (MAPPO) with a shared affective reward functional on final emotion prediction quality.
The system operates as a sequence of orchestrated actions:
- Query Planning: The agent generates three targeted hypothetical queries—supportive, confusing, and countering—based on latent affective inferences from the input, promoting robust cross-modal comparison.
- External Retrieval: An external corpus is searched (using both cognitive and perceptual hypotheses) to obtain cross-modal evidence.
- Evidence Filtering: Retrieved items are adjudicated for affective alignment and discriminative relevance, extracting a concise, robust support set.
- Cross-Modal Fusion: Two modules further process the evidence and base modalities:
- Modality-Balancing Mixture of Experts (MB-MoE): Dynamically reweights contributions of audio and video, mitigating cross-modal representation mismatch.
- Retrieval-Augmented Adaptive Fusion (RAAF): Injects missing modality information or weak modality cues using retrieved embeddings for semantic completion.
- Emotion Generation: The refined evidence and fused multimodal representation are consumed by the agent to generate both an emotion label and rational explanatory text.
A holistic RL optimization aligns intermediate retrieval, filtering, and fusion with the ultimate outcome metric (emotion recognition F1), with local incremental rewards further guiding agent-specific policies.

Figure 2: Overview of AffectAgent, detailing collaborative query planning, evidence adjudication, emotion generation, and the role of RAAF and MB-MoE modules in robust, adaptive cross-modal fusion.
Methodological Innovations
Multi-Agent RL Coordination
AffectAgent formulates the MER task as a sequential, partially-observed multi-agent decision process. Each agent possesses local state and observation spaces (e.g., multimodal input, candidate set, evidence pool), acts in a shared vocabulary, and is assigned both a global shared reward and local incremental signals according to its policy's effect on the terminal outcome. This framework ensures that the retrieval, selection, and fusion stages are reward-aligned not to superficial semantic similarity, but directly with fine-grained affective reasoning performance.
Query Hypothesis Diversification
Unlike naive or linear RAG, the query planner's explicit separation of supportive, confusing, and countering queries encourages robust evidence triangulation. Supportive queries reinforce ground-truth cues, confusing queries surface near-miss ambiguities critical for fine-grained label separation, and countering queries introduce contrastive samples to penalize incorrect priors.
Modality-Aware Fusion
MB-MoE adaptively balances transformation experts for each modality based on the global context, robustly addressing heterogeneity between visual and audio domains. RAAF leverages gated cross-attention to supplement and harmonize missing or weak modalities, improving robustness under incomplete input regimes—a persistent issue in practical MER deployments.
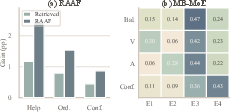
Figure 3: Visualization of RAAF and MB-MoE: (a) RAAF provides consistent performance gains across evidence retrieval conditions; (b) MB-MoE dynamically routes expert weights in response to input state, indicating adaptive fusion.
Empirical Evaluation
AffectAgent is extensively evaluated on MER-UniBench, spanning three core settings: Basic Emotion Recognition, Sentiment Analysis, and Fine-grained Emotion Recognition. Tests employ both affect-specific MLLMs (e.g., AffectGPT, Emotion-LLaMA) and general-purpose MLLMs (e.g., Video-LLaMA, PandaGPT), assessing full-modality and missing-modality variants.
Main Results
- Consistent Performance Improvements: AffectAgent delivers improved mean accuracy across all tested MLLMs relative to their baselines—yielding +6.38 to +6.79 points mean improvement on general models and up to +2.01 on strong affect-selective models.
- Robustness to Missing Modalities: Substantial performance gains persist when one modality (audio, video, or text) is absent, confirming RAAF efficacy in evidence completion and semantic alignment.
- Superiority over RAG Baselines: AffectAgent surpasses competitive multimodal RAG frameworks (Rewrite-Retrieve-Read, BGM, RAG-DDR) on all datasets, demonstrating the necessity of affect-oriented rather than fact- or semantic-oriented RAG.
Model Analysis and Ablations
Ablation studies confirm that both multi-agent coordination and explicit evidence structure (inclusion of confusion and countering evidence) are critical; omitting either reduces HIT scores by 0.7–2.2. The greatest drop is observed when both the planner and filter agents are excluded, revealing the necessity of agentic collaborative reasoning. Case studies further validate that the architecture is robust to minor query deviations but can still fail when evidence chains are excessively derailed.
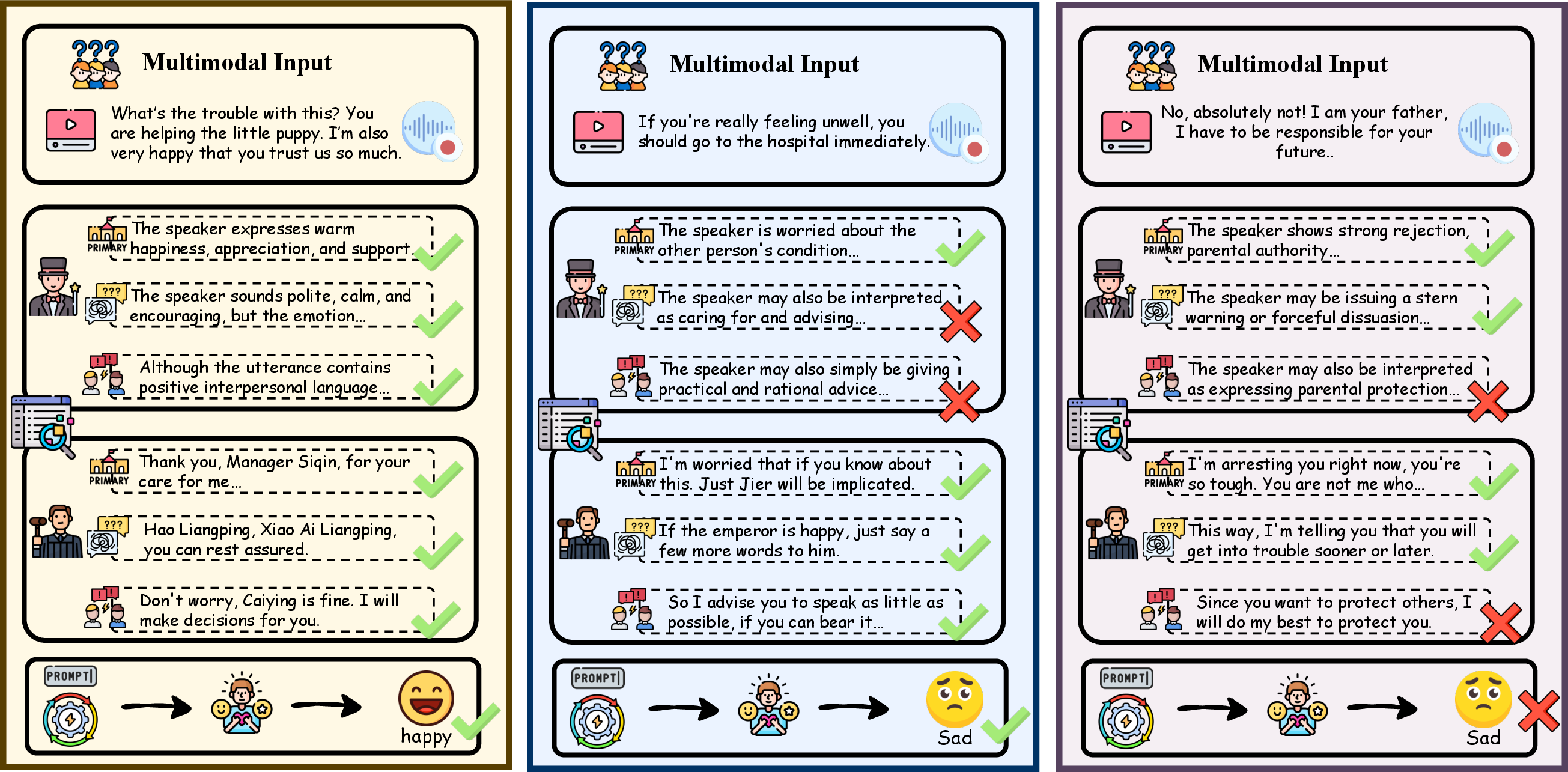
Figure 4: Representative case studies highlight both the robustness of collaborative query reasoning when evidence is aligned and the failure modes under severe query drift.
Practical and Theoretical Implications
AffectAgent demonstrates that collaborative, reinforcement-learned agentic RAG is highly effective for multimodal tasks where superficial semantic alignment fails to capture complex signal interplay—an insight likely extensible to other affective and cognitive AI domains. The modular architecture allows direct integration atop general or task-optimized MLLMs, yielding reliable gains with minimal base model changes.
From a theoretical perspective, the move from single-agent to collaborative multi-agent RAG, reward-aligned with an affective objective, opens avenues for further research in interpretable, controllable retrieval and reasoning, particularly for domains with ambiguous or weakly-labeled concepts.
Future Directions
Potential future work includes scaling AffectAgent to emergent multimodal datasets with higher label ambiguity, extending agent specialization (e.g., adding context memory to agents), incorporating user feedback in reward shaping, and adapting the collaborative agentic protocol to other subtle perceptual tasks beyond emotion recognition.
Conclusion
AffectAgent constitutes a significant advance in retrieval-augmented multimodal emotion recognition: its collaborative agentic design, combined with adaptive modality fusion, yields robust, state-of-the-art performance across diverse MLLMs and input conditions. The framework establishes a compelling blueprint for future research in affect-oriented, reinforcement-learned retrieval and reasoning architectures.

