- The paper introduces DSAIN, which explicitly models situational context through advanced behavior denoising and feature encoding to improve CTR predictions.
- It employs a multi-stage pipeline integrating behavior denoising, situational feature encoding, and tri-directional correlation fusion to capture complex user behavior dependencies.
- Empirical results on Taobao, Eleme, and Meituan datasets demonstrate significant performance gains, including improved AUC and increased CTR, validating its industrial applicability.
Deep Situation-Aware Interaction Network for CTR Prediction
Introduction and Motivation
Modeling user behavior sequences is central to high-accuracy Click-Through Rate (CTR) prediction for recommender systems and online advertising. State-of-the-art approaches have leveraged deep networks, RNNs, CNNs, and Transformer variants to exploit such behavioral histories, incorporating increasingly rich side information (e.g., item metadata, temporal data, and behavior types). However, prior literature largely fails to concurrently exploit the full context of behavior—namely, the situation in which the behavior occurs, comprising behavior type, temporal, and (virtual/physical) spatial features, and complex correlations among these factors.
The Deep Situation-Aware Interaction Network (DSAIN) addresses this gap via explicit situation modeling, novel noise reduction in behavior sequences, advanced feature parameterization, tri-directional correlation fusion, and situation-aware sequence aggregation.
DSAIN Architecture Overview
DSAIN formalizes the situation as a multi-feature context for each behavior, then learns embeddings through a multi-stage pipeline emphasizing both expressivity and denoising:
- Behavior Denoising Module (BDM) employs Gumbel-Softmax reparameterization to probabilistically sample historical interactions by correlation, attenuating noise from irrelevant exposures while retaining gradients for end-to-end learning.
- Situational Feature Encoder (SFE) parameterizes both generic and specific representations for each situational feature, fusing these adaptively and mapping them through micro-MLPs conditioned on item embeddings.
- Correlation Fusion Module (CFM) captures tri-directional dependencies by applying behavior-mixer, channel-mixer, and feature-mixer structures in stacked, parameter-shared fashion (Figure 1).
- Situation Aggregation Module (SAM) aggregates refined sequence embeddings, applying target-aware attention and channel-adaptive weighting for precise representation prior to final CTR scoring.
This architecture allows DSAIN to coherently encode cross-behavioral, cross-feature, and cross-channel dependencies while selectively retaining signal-supporting historical actions.
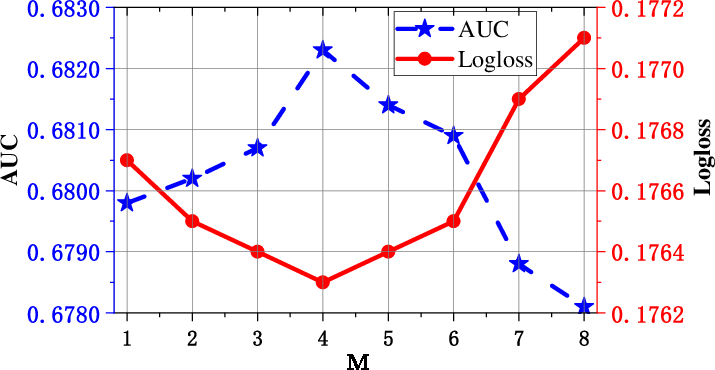
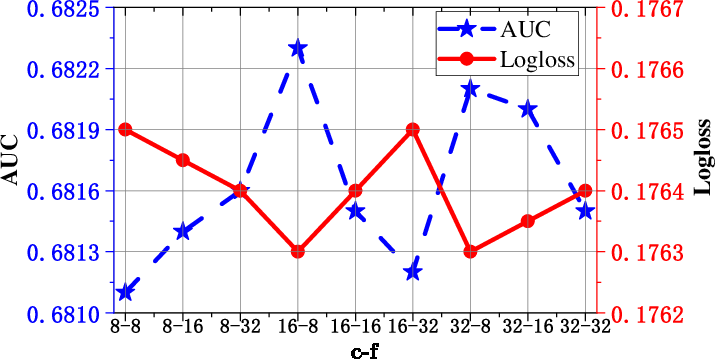
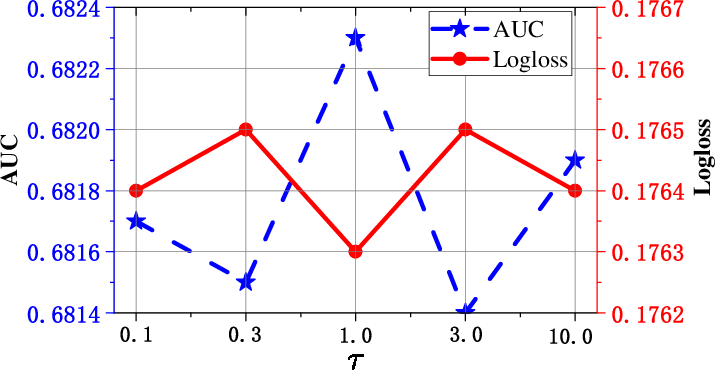
Figure 1: Layer depth M in CFM. Varying M reveals optimal fusion depth for tri-directional correlation modeling before overfitting/noise degrades results.
Core Methodological Contributions
Behavior Denoising via Gumbel-Softmax
DSAIN identifies non-click exposures—prevalent in e-commerce logs but frequently noise-inducing for sequence models. It computes a learnable correlation score between each historical interaction and the candidate item, then uses Gumbel-Softmax sampling for differentiable behavior selection. This probabilistic selection modulates each interaction’s embedding, allowing the network to attenuate or ignore less relevant behavioral contexts dynamically.
Hierarchical and Parameterized Situation Embeddings
Situational features are not monolithically embedded. SFE learns both commonality (generic) and specificity (value-level) vectors for each feature (e.g., hour-of-day, page type), enables adaptive gating between them, and utilizes parameter estimation as the weights/biases of micro-MLPs to model interactions with item embeddings. This structure multiplies the network’s capacity for fine-grained context modeling, surpassing mere concatenation or pooling.
Tri-Directional Correlation Fusion
CFM operates via three MLP-based mixers:
- Behavior-mixer: models long- and short-range dependencies among sequential behaviors using standard, adjacent, dilated, and shifted sampling partitions. Weighted aggregation of these features enables DSAIN to capture both local and global interest patterns.
- Channel-mixer: encodes dependencies among latent semantic dimensions (channels) in the situational feature embeddings.
- Feature-mixer: learns relationships among different situational features for each behavior, enabling joint context modeling at each interaction timestep.
Stacked layers (with shared parameters for regularization and computational efficiency) enable hierarchical abstraction and information propagation across behaviors, features, and embedding channels.
Situation-Aware Aggregation
SAM employs position-wise and channel-wise adaptivity:
- For the target (candidate) behavior, a weighted sum attends to the importance of each situational feature.
- For historical behaviors, a dynamic attention-weighted sum (modulated by candidate-situation similarity) governs feature aggregation.
- Dimensional (channel-level) gating enables highly granular adjustment of the final behavioral embedding, enhancing discriminative power for CTR predictions.
Empirical Validation
DSAIN achieves consistent performance gains across multiple metrics and datasets:
- Taobao, Eleme, Meituan: Outperforms baselines—including DIN, DIEN, CAN, FeedRec, CARCA, and DIF-SR—on both AUC and Logloss, with improvements generally exceeding 1,000 AUC points over the strongest prior methods. The network is robust across both public and large-scale industrial datasets.
- Online A/B Testing (Meituan): DSAIN boosts CTR by 2.70%, CPM by 2.62%, and GMV by 2.16%—all significant improvements in an industry production context.
Ablation studies demonstrate DSAIN’s reliance on all core components: BDM (vs. heuristic filtering), SFE (vs. naive pooling), all three directional mixers in CFM (removal of any yields measurable performance drops), and SAM’s channel adaptivity.
Hyperparameter Sensitivity
Optimal model performance requires careful tuning of correlation fusion depth (optimal layer depth M is empirically found to be 4; see Figure 1), mixer hidden dimensions, and Gumbel-Softmax temperature (for sampling sharpness in BDM). Excessive stacking and overly large mixer sizes degrade performance due to noise propagation and overfitting.
Implications and Future Directions
Practically, DSAIN’s design demonstrates the business-critical impact of comprehensive situational modeling and effective behavioral denoising for CTR prediction at industrial scale. It also provides theoretical confirmation that fine-grained, parameterized context modeling and multi-axis correlation fusion enable greater abstraction and pattern discovery than prior architectures relying on simple concatenation or attention over a limited set of features.
Future research may focus on:
- Extending situation modeling: Incorporating external knowledge or graph-based relational context as additional situational signals.
- Generalizing CFM: Exploring alternatives such as cross-attention, graph mixers, or more expressive architectures for multi-directional fusion.
- Efficiency and deployment: Further compressing the network (e.g., parameter sharing, quantization) without sacrificing modeling capacity, and evaluating transfer to other CTR-like domains beyond food delivery.
- Interpretable AI: Analyzing which situation-channel axes most influence predictions, facilitating actionable insights for content selection and ad placement.
Conclusion
DSAIN formalizes and efficiently exploits the unified concept of situation in user behavior modeling, offering a tractable, denoised, and correlation-rich embedding of user sequences for CTR prediction. The architecture, validated both offline and at scale in live production, delivers measurable gains across core business metrics. Its modular pipeline and strong empirical results foreground adaptive, context-aware, and interpretable sequence models as best practices for future recommender and advertising system design.