- The paper shows that hate speech is minimally enforced, with only 20% of hateful tweets removed even five months after posting.
- It employs a 24-hour, 540,000 tweet multilingual audit combined with a simulation of an AI-human triage pipeline for moderation.
- Findings indicate notable disparities across languages and engagement levels, suggesting institutional resource allocation drives moderation gaps.
The Enforcement and Feasibility of Hate Speech Moderation on Twitter
Overview and Study Design
This paper presents an unprecedented, large-scale, multilingual audit of hate speech moderation enforcement and feasibility on Twitter (now X), utilizing a globally representative 24-hour snapshot amounting to 540,000 manually annotated tweets. The analysis targets two foundational questions for platform governance: the real enforcement rate of hate speech policies, and the empirical limitations and resource requirements for large-scale hate speech moderation, especially through algorithmic and human–AI hybrid approaches.
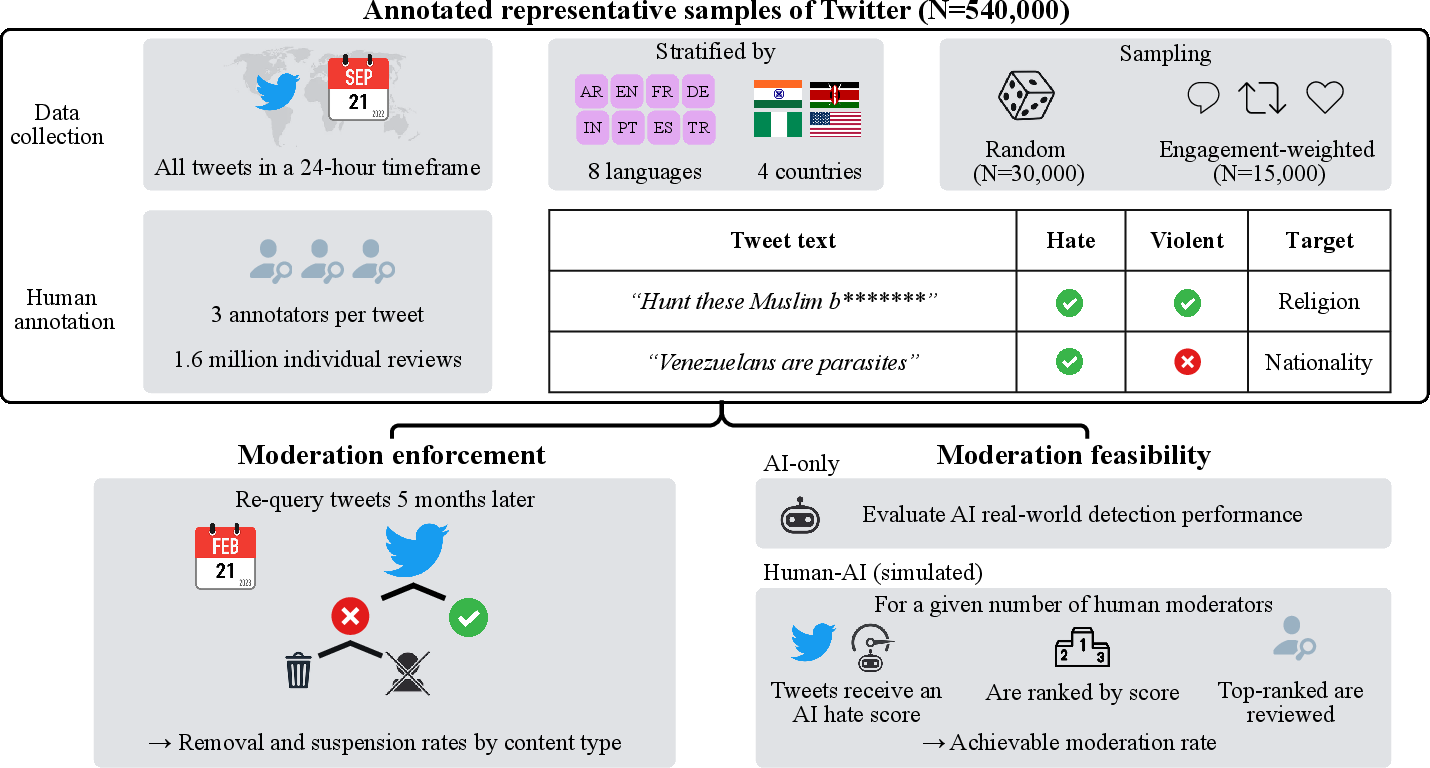
Figure 1: Study design for auditing hate speech moderation, encompassing global sampling, large-scale annotation, longitudinal enforcement assessment, and feasibility simulation of moderation pipelines.
Empirical Characterization of Hate Speech and its Moderation
Prevalence and Exposure
Hate speech is quantitatively rare (0.42% of tweets labeled hateful; 0.03% violent hate speech), but the absolute scale is non-trivial: this translates into approximately 225,000 hateful and 11,000 violent hateful tweets per day globally. The average user, under a chronological feed, is likely to encounter one hateful tweet daily and one violent hateful tweet every 17 days, with higher exposure probable in algorithmically curated feeds.
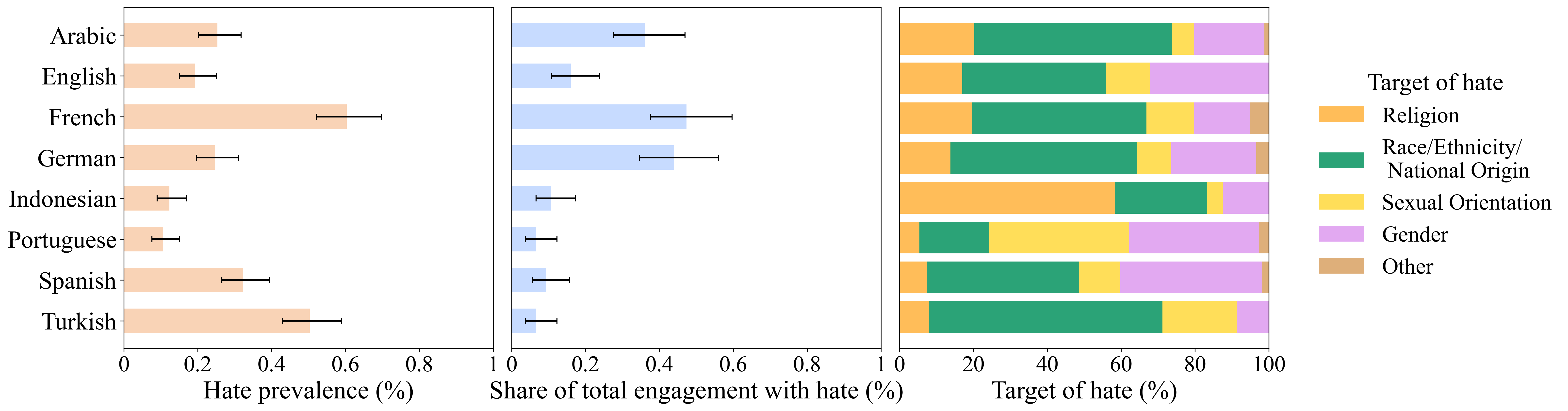
Figure 2: Language-level prevalence, engagement share, and target composition of hate speech across sampled languages.

Figure 3: Country-level prevalence, engagement share, and target composition of hate speech.
Removal and Enforcement Patterns
Post-hoc querying revealed the remarkable persistence of hate speech: five months after posting, 80% of hateful tweets were still accessible, including those with explicit violent content. The aggregate tweet removal rate for hate speech was only ~20%, but, critically, this encompasses removals for any reason (including voluntary deletion or deactivation). Platform-attributable removals (i.e., user suspensions) occur in only 9.2% of cases, with 9.0% of users posting hate being suspended.
Notably, hateful tweets are not statistically more likely to be removed compared to non-hateful tweets (β=−0.02, p=0.84), and there is no observed increase in enforcement for content classified as violent hate speech. The effect sizes are trivial and lack statistical significance, diverging sharply from policy-mandated harm prioritization. Conversely, other violation categories such as scams and adult content saw substantially higher removal rates.
Enforcement showed systematic variation across language and geography, with lower rates for Arabic (–12 percentage points) and Nigerian users (p=0.03), and higher rates for Indonesian users (+11 percentage points, p=0.037), relative to a US English baseline.
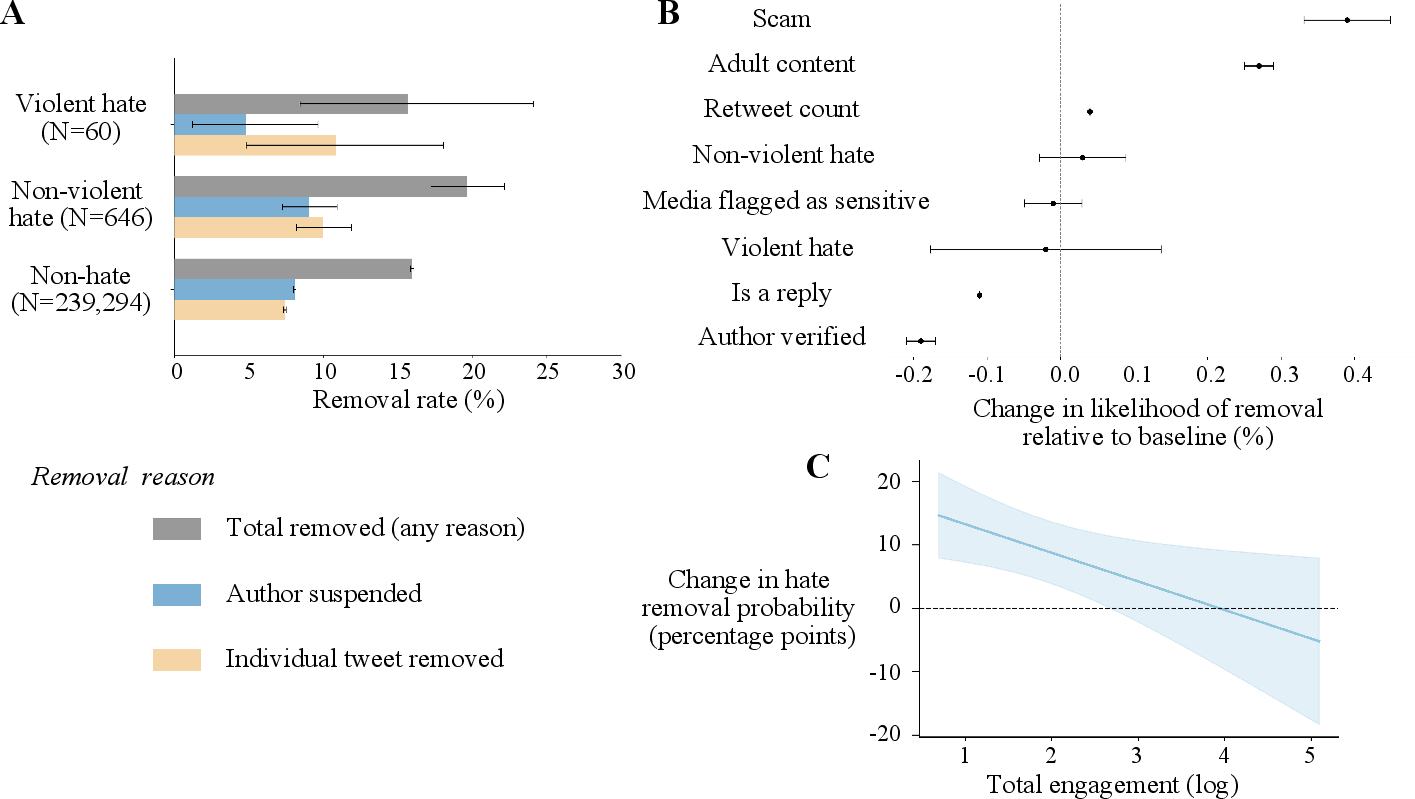
Figure 4: Low, severity-unresponsive hate speech enforcement and removal likelihood across content categories, with negative/insignificant correlation between engagement and removal probability.
Further, enforcement rates decrease with tweet engagement; more widely seen (higher engagement) hateful tweets are less likely to be removed (β=−0.05, p=0.01). No evidence supports systematic deployment of algorithmic visibility reduction ("downranking"), as measured by post-engagement metrics.
Technical Feasibility and Automation Constraints
AI Detection Capability
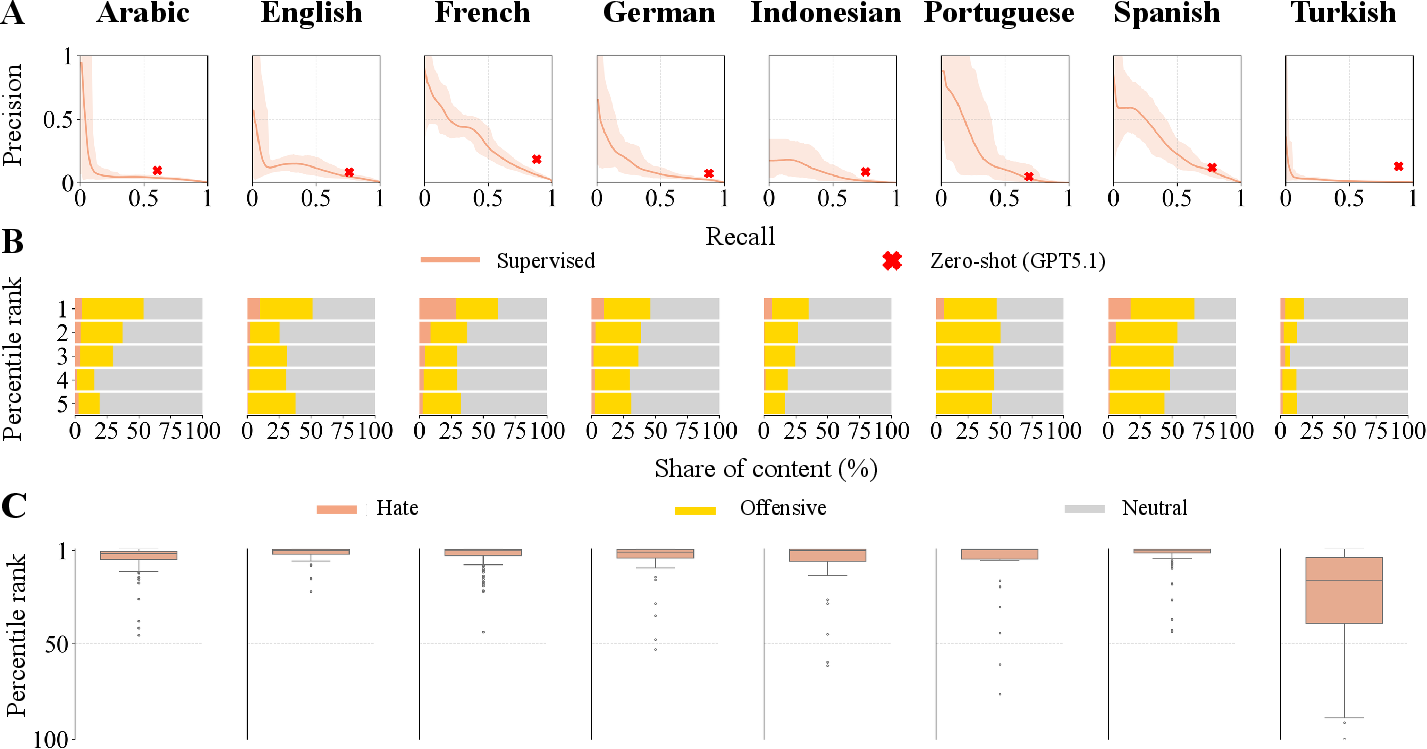
The study extensively benchmarks both traditional supervised models (including state-of-the-art transformers) and GPT-5.1 in a multilingual setting. All models were evaluated out-of-sample using the representative annotated dataset.
Human–AI Pipeline Simulation
Given the limitations of full automation, the study simulates a triage pipeline: AI surfaces top-scoring tweets for human moderator review, prioritizing by predicted hatefulness × engagement.
With current reported moderator staffing (from Twitter’s DSA filings) and best-in-class models, only 24.5% of engagement with hate speech could be avoided. Substantial disparities appear across languages, reflecting not only detection bottlenecks but also allocation misalignments—Indonesian and Arabic are especially under-resourced.
Cost modeling establishes that preventing 80% of engagement with hate speech is feasible at 2.9% of global revenue—well below statutory fine maxima (6–10% of revenue) under the EU DSA and UK Online Safety Act. Achieving 80% coverage of all hate content (as opposed to engagement-weighted) would be prohibitively expensive (19–61% of revenue) due to the extreme class imbalance and model errors.
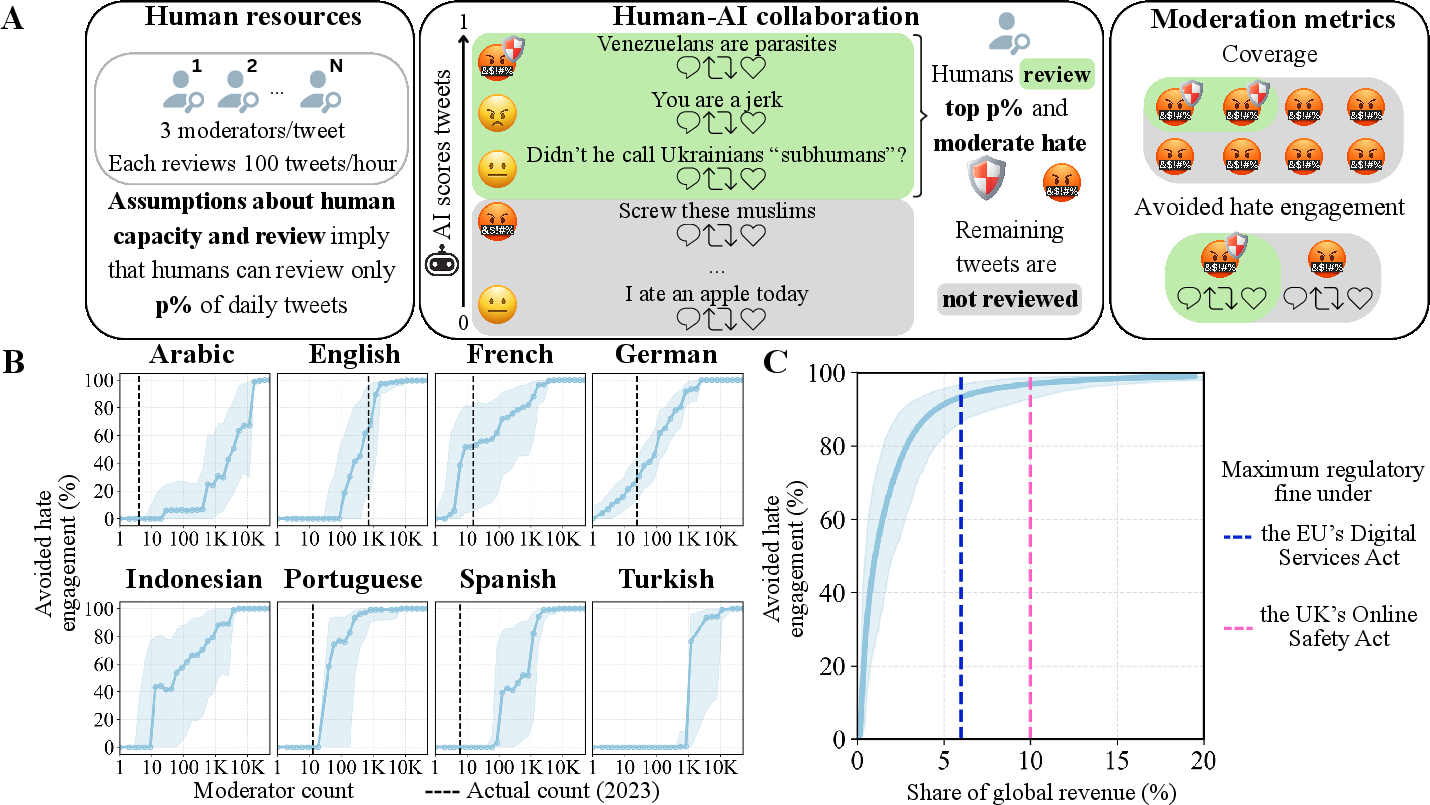
Figure 6: (A) Pipeline schematic showing AI-driven triage for human review; (B) Avoided engagement with hate as a function of moderator count (log-scale) per language; (C) Avoided hate engagement versus moderation cost as a share of Twitter global revenue, compared to regulatory fine ceilings.
Implications, Limitations, and Future Directions
Theoretical and Practical Ramifications
The research empirically invalidates the hypothesis that platform-scale hate speech persistence can be explained by technical infeasibility alone. Instead, it evidences that institutional priorities and the allocation of moderation resources drive enforcement gaps. The data-driven audit illuminates, with statistical rigor, the limitations of both standalone AI moderation and current organizational configurations for multilingual, global platforms.
The robust finding that current models are incapable of high-fidelity discrimination between hate and mere offense in realistic, imbalanced, and linguistically diverse settings has direct consequences for the design of algorithmic content moderation systems, reinforcing the necessity for human-in-the-loop review for all but the most clear-cut violations.
Disparities in moderation allocation by language and geography raise serious governance and regulatory equity concerns, especially given evidence of underinvestment in high-need language contexts, corroborated by recent external studies [tonneau2025language, elswah2023does].
On the financial and regulatory compliance side, the demonstrated tractability (sub-3% revenue) of achieving policy-relevant hate speech exposure reduction with hybrid workflows directly informs platform risk modeling and provides actionable benchmarks for regulatory bodies calibrating fines or compliance metrics.
Methodological and Scope Limitations
- Analysis is restricted to textual hate speech, excluding images, video, or multimodal contexts that may require distinct models and operational flows.
- The sample represents a single day, and may not capture temporal variation due to evolving platform policies or external events.
- Cost-benefit simulation assumes upper-bound resource allocation; practical requirements may fall lower due to moderator expertise, workflow optimization, or improved AI in the future.
Speculation on Future Developments
Continued advances in detection model architecture and pre-trained representation quality may gradually reduce (but not eliminate) the error floor observed in real-world hate/offense boundary detection, especially for under-resourced languages. Enhanced explainability and context modeling (e.g., multi-message thread context, user-level modeling) could marginally improve precision without a concomitant collapse in recall.
Policy and organizational changes that more closely align moderator allocation with exposure risk—potentially supported by real-time engagement-driven triage—could substantially improve real-world outcomes at sustainable cost. However, resolving governance and equity issues surrounding disparate resource allocation is likely to require regulatory intervention rather than technical advances alone.
Conclusion
This global audit substantiates that hate speech policies on Twitter are minimally and inconsistently enforced, with removals unresponsive to content severity, reach, or platform-stated priorities. Current AI systems are inadequate for reliable automated moderation, although their ranking capacity enables cost-effective human–AI triage capable of major exposure reductions within existing revenue constraints. Persistent hate speech exposure is thus a function of institutional choices rather than technical necessity; effective mitigation requires both investment in human oversight and organizational commitment to aligning resource allocation with harm reduction goals. Regulatory pressure, backed by cost-aware benchmarks such as those developed in this study, will be pivotal in correcting these systemic misalignments.
(2604.12289)