- The paper proposes a novel architecture that learns the time derivative via a Volterra integral, ensuring exact enforcement of initial conditions.
- It mitigates spectral bias by optimizing a differentiated PDE residual that amplifies high-frequency errors, thereby enhancing accuracy across time-dependent PDEs.
- Empirical results on advection, Burgers', and Klein-Gordon equations demonstrate orders-of-magnitude error reductions compared to standard PINNs.
Introduction and Motivation
Physics-Informed Neural Networks (PINNs) offer a mesh-free approach for solving time-dependent partial differential equations (PDEs) by embedding the residuals of PDEs into neural network loss objectives. While PINNs have demonstrated effectiveness across a range of scientific and engineering domains, their standard formulation—directly approximating the solution u(x,t)—suffers from prominent challenges: spectral bias, where high-frequency components are underrepresented, and causality violations, as temporal coordinates are treated as mere input features, ignoring the sequence of physical evolution. These limitations result in suboptimal performance, especially for problems with sharp gradients (e.g., shocks) or extended simulation times.
“Learning on the Temporal Tangent Bundle for Physics-Informed Neural Networks” (2604.11829) introduces a rigorous geometric and functional-analytic reformulation of the PINN methodology. Rather than targeting the solution manifold u(x,t) directly, the authors propose lifting the learning task to the tangent bundle by parameterizing the temporal derivative ∂tu(x,t) via a neural network and reconstructing the solution using an integral (Volterra) operator. This architectural change enforces initial conditions exactly, localizes optimization gradients to physical constraints, and systematically addresses spectral bias, yielding demonstrable performance improvements on hyperbolic, parabolic, and dispersive PDE benchmarks.
Methodological Framework
Geometric Shift: From Primal Manifold to Tangent Bundle
Traditional PINNs simultaneously attempt to minimize the PDE residual, boundary condition, and initial condition losses by directly regressing uθ(x,t). This approach is fundamentally a multi-objective non-convex optimization. The competing objectives can create sharp local minima and stiff gradients, with network solutions biased toward low-frequency modes due to the “F-principle”.
The proposed Physics-Informed Time Derivative Network (PITDN) architecture reparameterizes the problem: a neural network vθ(x,t) is trained to approximate the time derivative ∂tu(x,t); the state variable is then reconstructed via a Volterra integral operator:
u~θ(x,t)=u0(x)+∫0tvθ(x,s)ds
The initial condition is thus satisfied exactly for any network parameters.
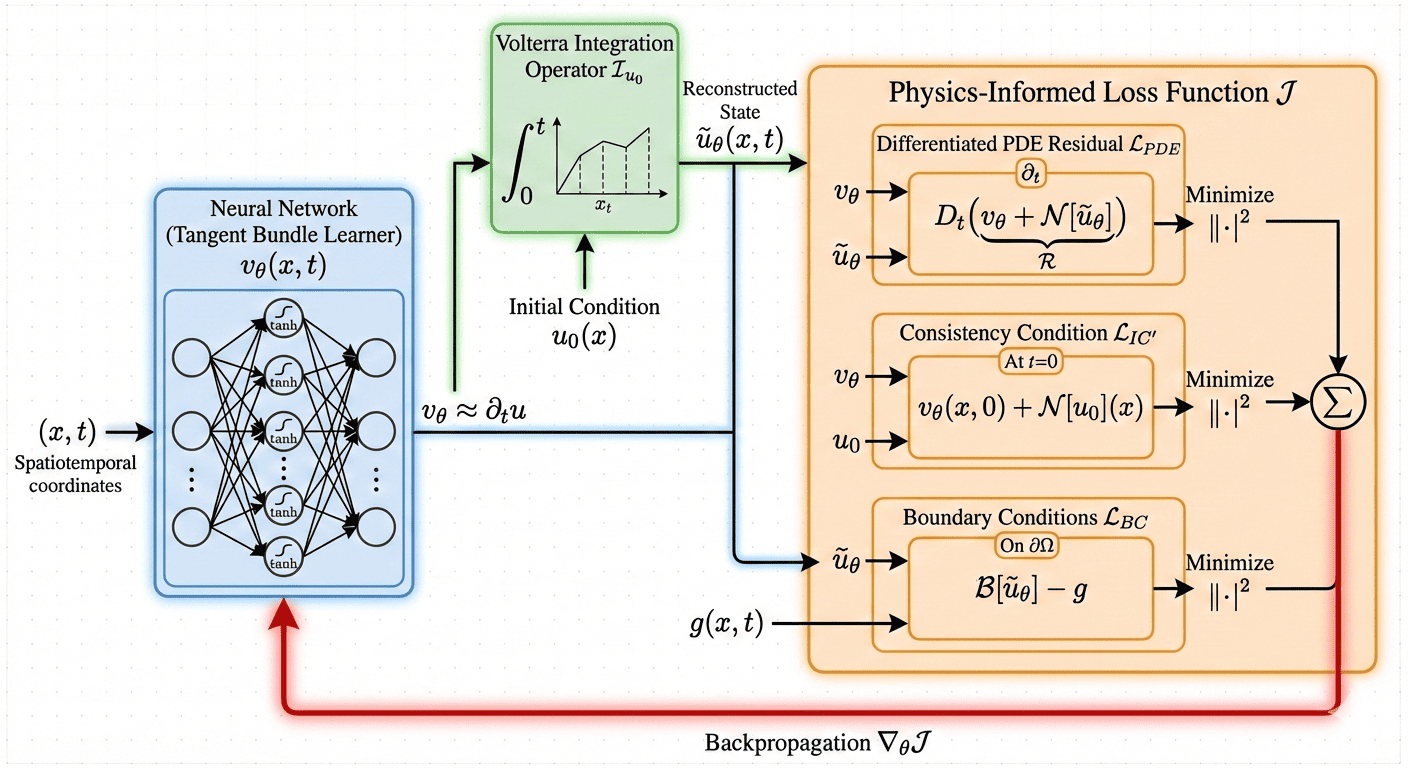
Figure 1: Structural architecture of the Physics-Informed Time Derivative Network (PITDN) where a neural network models ∂tu in the tangent bundle, and the solution is reconstructed via a Volterra operator, ensuring hard satisfaction of initial conditions.
The mathematical structure leverages functional analytic principles. The Volterra operator is shown to be continuous, compact, and injective, mapping L2 velocity fields uniquely to absolutely continuous solution trajectories—thus embedding causality at the architectural level.
Instead of minimizing the squared PDE residual ∥∂tu+N[u]∥L2, PITDN targets its temporal derivative:
u(x,t)0
The loss functional aggregates the squared norm of this differentiated residual with hard initial consistency and boundary constraints. Notably, theoretical results prove:
- The differentiated and primal formulations are mathematically equivalent under well-posedness and a specific initial consistency condition.
- Differentiated residual minimization acts as a high-pass filter: high-frequency errors in the solution residual receive amplified gradients, addressing neural spectral bias.
Discretization and Optimization
To compute the Volterra integral reconstruction in practice, the authors use composite trapezoidal quadrature, which is stable, differentiable, and enables efficient backpropagation. The neural network is a modest fully connected architecture (MLP with three layers, 10 neurons each, tanh activation), optimized using Adam and L-BFGS in sequence.
Theoretical Analysis
The paper offers rigorous analysis spanning several axes:
- Existence and Uniqueness: The strong solution to the original PDE is mapped smoothly from the learned velocity field via the Volterra operator, under standard Sobolev and Bochner space regularity.
- Error Propagation: Errors in the velocity field propagate only as u(x,t)1 in the solution, compared to linear or exponential amplification in explicit schemes. The reconstruction thus stabilizes training and prevents long-time error blowup.
- Spectral Amplification: Differentiating the residual leads to a frequency-dependent amplification in the optimization gradient, boosting learnability of stiff, high-frequency solution components.
The analysis is extended to high-order-in-time PDEs (e.g., Klein-Gordon equation) by repeated integration, employing Cauchy’s formula to express higher-order antiderivatives as Volterra operators with polynomial kernels.
Numerical Experiments
The empirical performance of PITDN is validated on three canonical PDEs:
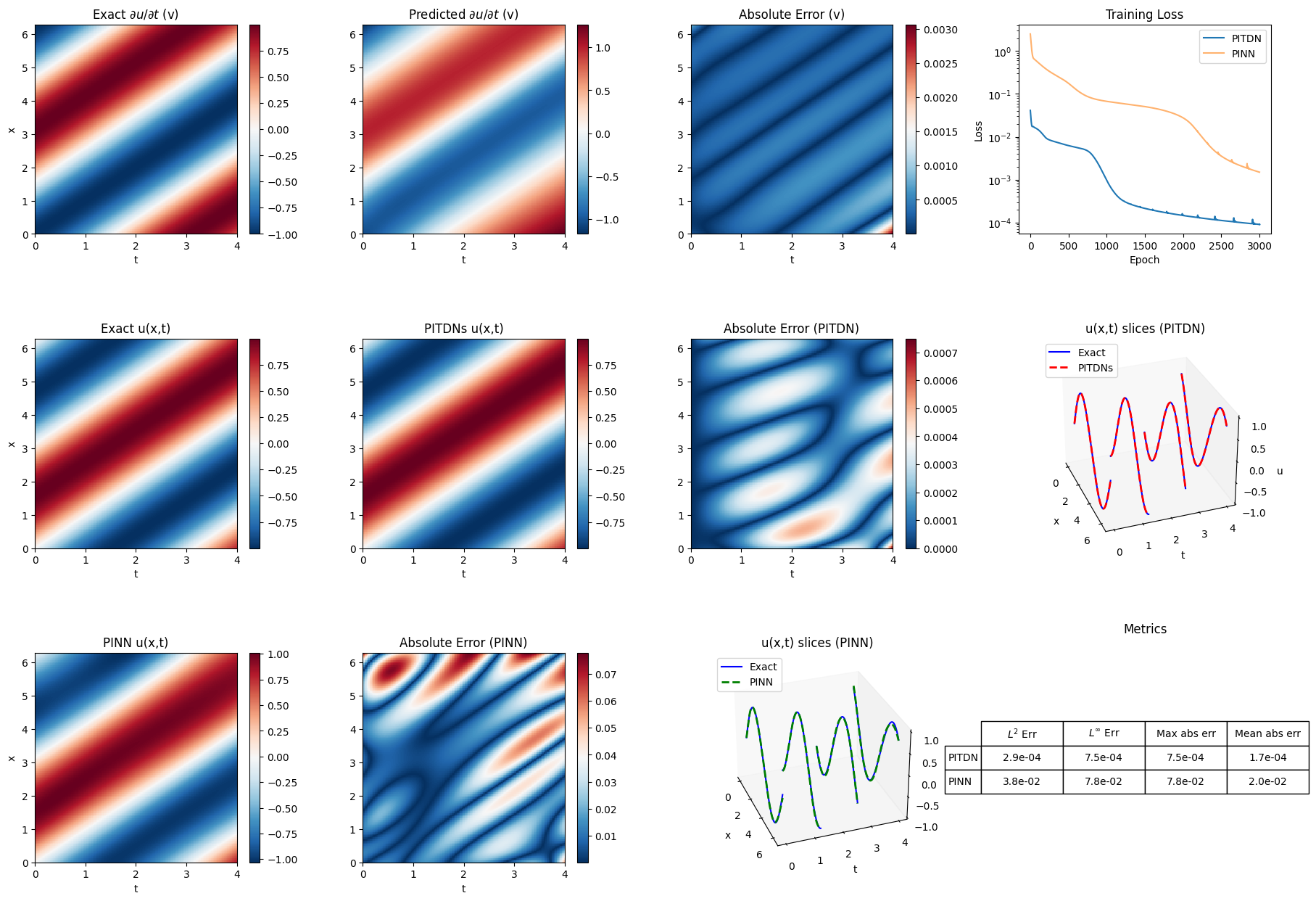
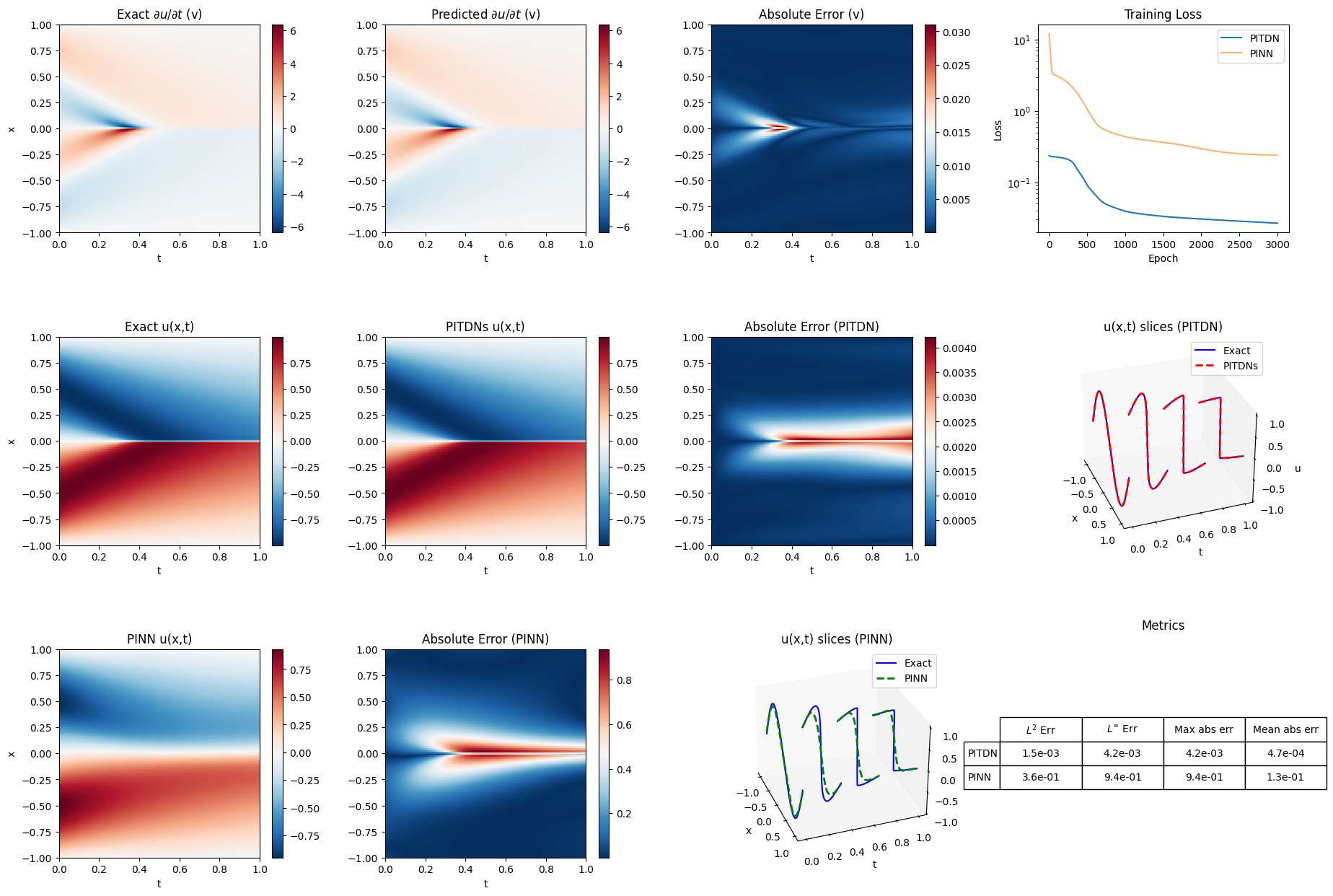
Linear Advection Equation
Viscous Burgers' Equation
Nonlinear Klein-Gordon Equation
- Setup: Second-order dispersive PDE with constructed analytic solution; both initial position and velocity given.
- Results: PITDN models the acceleration field u(x,t)8 and, via double integration, produces a standing wave solution with u(x,t)9 relative error. Standard PINNs show phase and amplitude artefacts even with similar training loss.
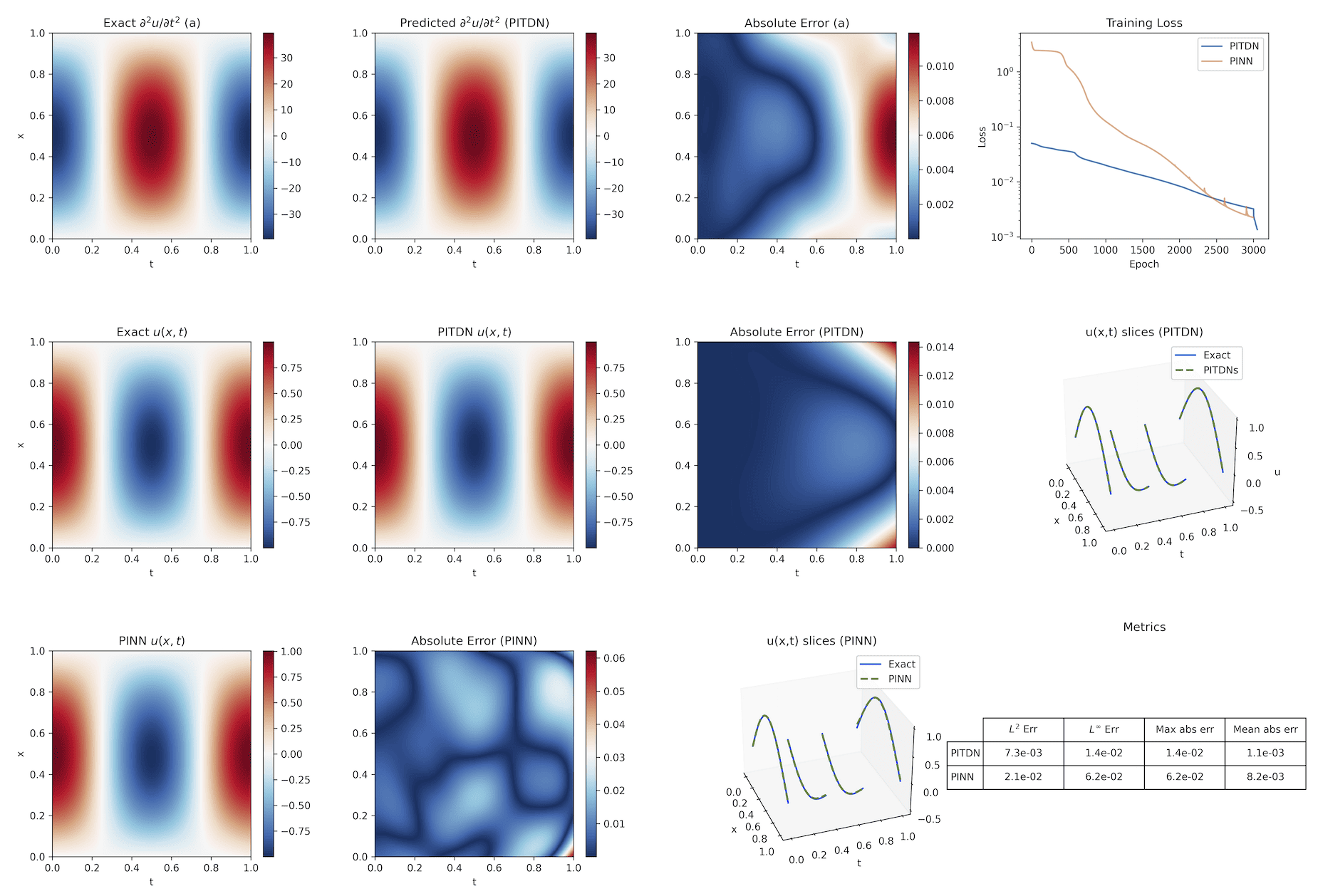
Figure 4: PITDN accurately reconstructs the standing wave in the nonlinear Klein-Gordon problem, outperforming direct-solution PINN in phase and amplitude accuracy, even for second-order-in-time dynamics.
Implications and Future Directions
The PITDN paradigm presents a significant advance in the theoretical and practical treatment of time-dependent PINNs:
- Practical Impact: Hard enforcement of initial conditions, improved training stability, and orders-of-magnitude error reduction using compact MLP architectures. The approach is robust to problem stiffness, discontinuities (shocks), and extended timescales.
- Theoretical Significance: Connects PINNs to differential geometric constructs (tangent bundles), extends variational methods, and justifies frequency-amplifying loss design via rigorous operator analysis.
- Limitations and Open Problems: The present formulation assumes known initial data and regular solutions. Extensions to inverse problems, discontinuous solutions, high-dimensional domains, and conservation properties (symplectic or Hamiltonian systems) remain open challenges.
- Connections: This approach is compatible with operator-learning frameworks (e.g., DeepONet, FNO), Neural ODE methods, and could be synergistically combined for parametric, multi-instance, or uncertainty-quantified PDE solvers.
- Future Developments: Adaptive time-resolved integration, weak formulation generalization, structure-preserving integration, and scalable implementations for high-dimensional PDEs.
Conclusion
“Learning on the Temporal Tangent Bundle for Physics-Informed Neural Networks” (2604.11829) provides a theoretically principled and empirically validated advance in PINNs for time-dependent PDEs. By architecturally and functionally shifting learning to the tangent bundle and optimizing a differentiated PDE residual, PITDN enforces causality, amplifies high-frequency errors to mitigate spectral bias, and substantially outperforms standard methods in accuracy, convergence, and stability. This work establishes new mathematical foundations for physics-informed SciML and opens promising pathways for further advances in neural PDE solvers.