- The paper introduces GazeVaLM, a benchmark leveraging radiologist eye-tracking data to assess the clinical realism of AI-generated chest X-rays.
- It details task-driven differences in gaze behavior and pupillary responses, revealing diagnostic and visual Turing test insights.
- The study highlights a performance gap between expert radiologists and state-of-the-art LLMs, advocating for gaze-supervised training to improve alignment.
GazeVaLM: A Multi-Observer Eye-Tracking Benchmark for Evaluating Clinical Realism in AI-Generated X-Rays
Introduction and Motivation
The robust evaluation of AI-synthesized medical images remains a critical, unsolved problem in clinical AI. While generative models—especially diffusion models—are capable of producing chest X-rays of high visual fidelity, standard computational evaluation metrics (e.g., FID, IS) are agnostic to nuanced clinical anomalies or artifacts that are salient to expert radiologists. There is an unmet need for empirical benchmarks that directly measure clinical realism and interpretability. GazeVaLM addresses this by providing a novel, large-scale, multi-observer eye-tracking dataset capturing radiologist perception of both authentic and synthetic chest radiographs, with a focus on authenticating images and understanding the effect of generative artifacts on visual strategies.
Dataset Construction and Experimental Protocol
GazeVaLM systematically pairs synthetic and real chest X-rays, each corresponding to identical radiology reports, generated using the RoentGen vision-language diffusion model. After quality assurance by board-certified radiologists, the final test set comprises 30 real and 30 synthetic frontal chest X-rays evenly spanning five pathology categories, ensuring content diversity and controlled clinical matching.
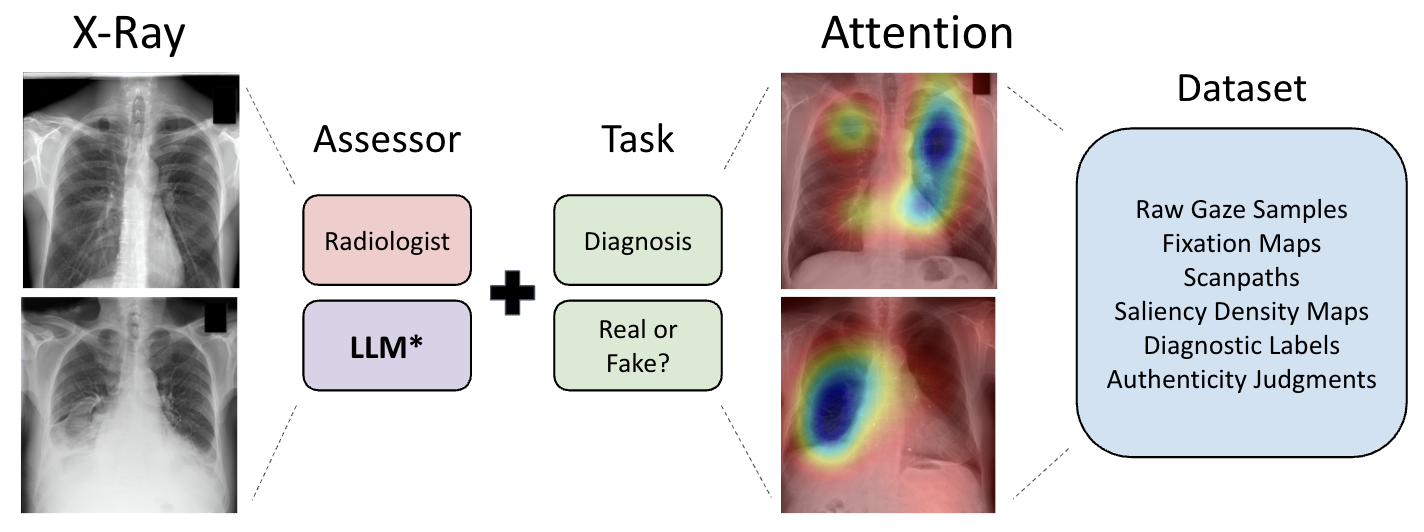
Figure 1: The dataset pipeline organizes two tasks (diagnostic assessment, visual Turing test) and involves separate assessors to generate a rich set of gaze data and clinical labels.
The eye-tracking experiment was conducted with 16 board-certified radiologists representing diverse subspecialties and experience levels. Each participant interpreted all 60 images under two paradigms:
- Diagnosis Task: Pathology detection and description, blind to image authenticity, capturing natural diagnostic strategies.
- Visual Turing Test (VTT): Real/fake classification, with justification of visual cues underlying judgments.
This paradigm separation enables direct investigation of how explicit authenticity questioning alters perceptual strategies and scanpaths. A 10-day washout interval mitigated task contamination. All gaze data acquisition adhered to high-precision standards with the EyeLink 1000 Plus, employing rigorous calibration and preprocessing for scanpath and saliency map extraction.
Data Modalities and Dataset Structure
The released dataset provides fine-grained, multi-modal supervision for each (observer, image, task) trial:
- Raw gaze time series (x, y, t, pupil size)
- Fixation maps (duration-weighted Gaussian heatmaps)
- Scanpaths (ordered sequences of fixations)
- Aggregate saliency maps
- Structured diagnostic labels and authenticity judgments
- Stimulus images (real/synthetic) and matched radiology reports
Additionally, the dataset comprehensively benchmarks six state-of-the-art multimodal LLMs (GPT 5.2 Thinking, Gemini 3 Pro, Claude Sonnet 4.5, Grok 4.1, Llama 4, DeepSeek 3.2), collecting both VTT/classification outputs and structured diagnostic findings under identical presentation protocols.
Analyses and Key Findings
Gaze Behavior and Task Modulation
Quantitative analysis reveals strong task-driven modulation of visual exploration. Diagnostic tasks elicit approximately 3× longer viewing durations and corresponding increases in scanpath length, driven by a more detailed and comprehensive search pattern. However, mean fixation duration remains invariant across tasks (~273 ms), indicating consistent micro-level processing time per foveal fixation, irrespective of higher-level task demands.
Notably, pupillometric measures emerge as robust implicit markers of perceived realism. Across both tasks, real images consistently induce greater pupil dilation and variance compared to synthetic images, suggesting higher cognitive or affective engagement with authentic data. This distinction is maximized in the diagnosis task, manifesting as a mean pupil size difference exceeding 45 arbitrary units (EyeLink scale) between real and synthetic stimuli.
Diagnosis Versus Visual Turing Test: Saliency and Scanpaths
Figure 2: Gaze overlays for both tasks demonstrate pathology- and authenticity-contingent differences in attention allocation, with rows corresponding to discrete diagnostic categories and columns alternating between saliency and scanpath visualizations.
Diagnosis task scanpaths are more extensive with denser saliency in pathology-specific regions, reflecting targeted clinical reasoning. VTT tasks prompt more global and rapid exploration, as evidenced by increased saccade amplitude and velocity, and shorter cumulative scanpaths, indicating a search for global “artificiality cues” rather than local pathological features.
Human experts in the VTT achieved an average authenticity classification accuracy of 80.1%. All LLMs underperformed relative to human experts, with the highest LLM (GPT 5.2 Thinking) at 71.7%; the poorest model (DeepSeek 3.2) achieved chance-level performance. Importantly, LLMs exhibited systematic overconfidence—reporting high average confidence (>3/4) across models—regardless of true accuracy, highlighting a miscalibration in uncertainty estimation for synthetic image identification.
Implications for Clinical and AI Research
GazeVaLM's findings reinforce that computational realism metrics are insufficient proxies for clinical perception. The coupling of gaze data and authenticity judgments provides a new empirical substrate for:
- Gaze-supervised model training (e.g., using radiologist fixations as attention supervision for VQA or segmentation)
- Human–AI alignment studies, quantifying the perceptual gap between clinical experts and state-of-the-art LLMs
- Development of implicit authenticity detectors based on physiological correlates (e.g., pupillometry)
- Fine-grained benchmarking: Future generative models can be evaluated not only on diagnostic fidelity but on their ability to elicit naturalistic, expert-like visual search strategies.
Limitations and Future Directions
GazeVaLM is currently restricted to frontal chest X-rays synthesized by a single diffusion model and evaluated by experts from a single institution. Expansion to other imaging modalities, pathologies, generative frameworks, and geographies is needed for broad generalization. Furthermore, integration of these data with gaze-aware deep networks is an anticipated next step toward closing the gap in AI-human interpretability and trust.
Conclusion
GazeVaLM establishes a rigorous, reproducible benchmark for the evaluation of clinical realism in AI-synthesized radiology, supplying the community with a comprehensive multi-observer gaze dataset, detailed clinical benchmarks, and a systematic comparison to multimodal LLMs. The dataset enables new research in gaze-guided evaluation, authenticity detection, and uncertainty calibration. As synthetic data proliferates in medical workflows, such resources are essential for guaranteeing safety, trust, and clinical utility.