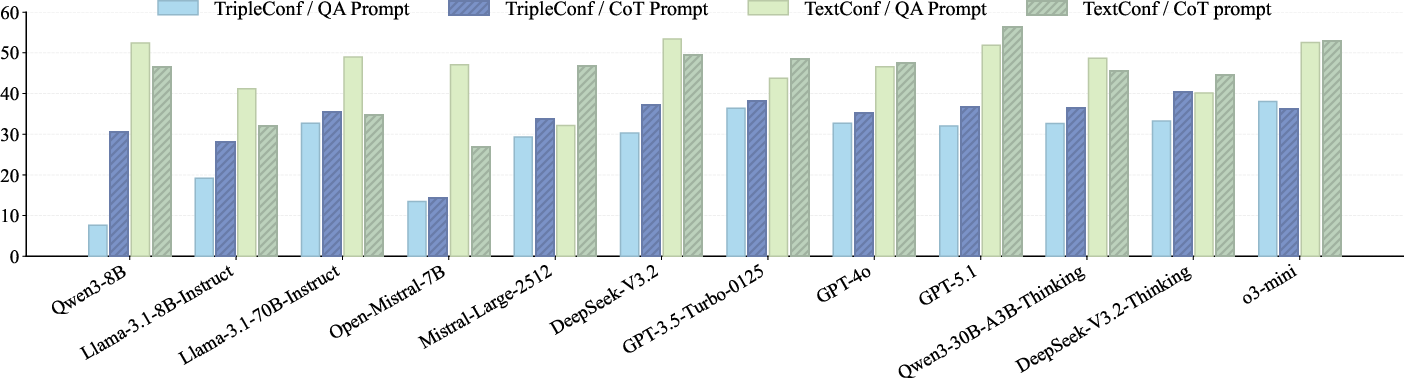
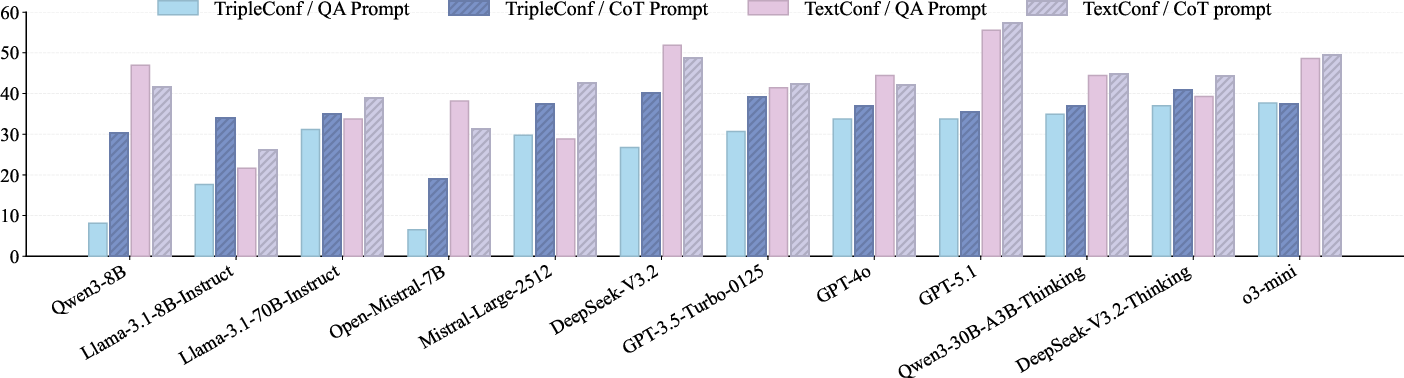
- The paper introduces a novel ConflictQA benchmark and XoT framework to assess and improve LLM reasoning under conflicting evidence.
- Quantitative results reveal up to 79% decline in exact match scores when LLMs face adversarial KG and textual cues.
- Experimental analysis underscores the significance of evidence ordering and explanation-based prompting for robust, multi-source reasoning.
Faithful LLM Reasoning under Cross-Source Knowledge Conflicts: The ConflictQA Benchmark and XoT Framework
Introduction
The reliability of LLM reasoning with RAG is increasingly critical as real-world deployments integrate heterogeneous external knowledge sources—primarily unstructured text and (semi-)structured KGs. However, conflicts between such sources are inevitable, as updates, errors, or adversarial manipulations in knowledge repositories proliferate. Existing research has mainly focused on conflicts between parametric (internal) LLM knowledge and evidence retrieved from one source. Cross-source evidence conflicts, especially between text and KGs, are not addressed with the same rigor, leaving a notable blind spot in the evaluation and improvement of LLM faithfulness.
This paper presents a comprehensive study into LLM reasoning under explicit cross-source evidence conflicts, operationalized through the ConflictQA benchmark. The paper also introduces XoT, a two-stage explanation-based thinking prompting framework, to mitigate conflict sensitivity and improve faithfulness.

Figure 1: Example depicting cross-source (text vs. KG) conflict during LLM RAG reasoning.
The ConflictQA Benchmark: Construction and Structure
ConflictQA is constructed on top of the WebQSP and ComplexWebQuestions datasets. Its design systematically instantiates scenario-based conflicts across two orthogonal axes: evidence sufficiency (non-complementary vs. complementary) and conflict localization (negative evidence in text vs. KG).
Two settings are defined:
- Non-complementary (Non-COMP): Either text or KG suffices to answer.
- Complementary (COMP): Both evidence types are required for correct reasoning.
Each setting is further split into:
- TripleConf: Conflict (incorrect cue) in KG evidence.
- TextConf: Conflict (incorrect cue) in textual evidence.
Benchmark construction proceeds in two stages:
- Positive Evidence Collection: Human-verified extraction of answer-supportive triples and textual passages.
- Conflict Instantiation: For each instance, plausible but incorrect answers are auto-generated. KG triples or texts are manipulated via entity substitution and LLM rewriting to introduce semantic but incorrect cues, creating adversarial evidence intentionally designed to conflict with the positive counterpart.
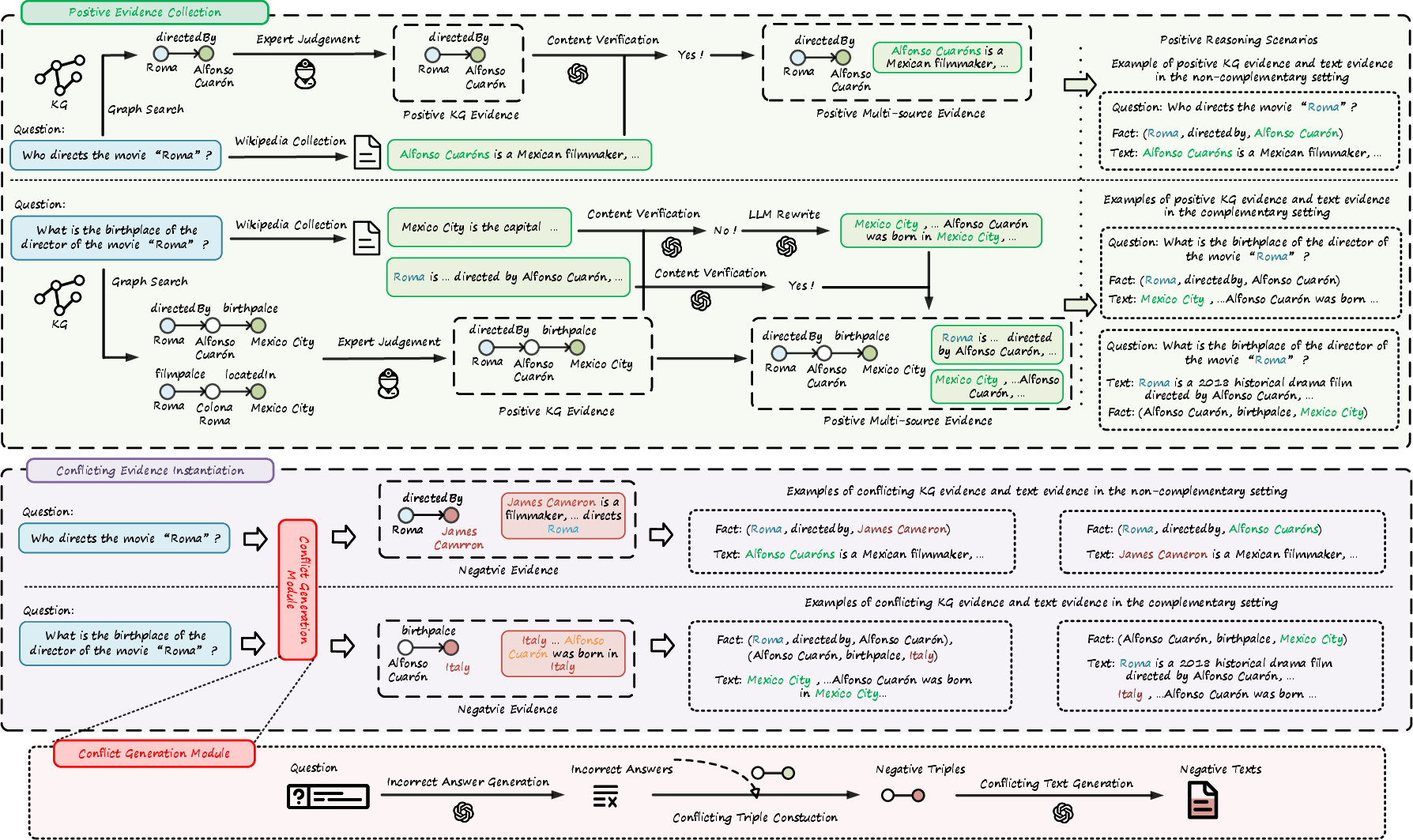
Figure 2: Construction pipeline for ConflictQA: evidence collection, conflict generation, and the resulting structuring in Non-COMP and COMP settings.
Evaluation Protocols and LLM Robustness Analysis
Twelve LLMs, spanning general instruction-following and reasoning-specialized architectures, serve as evaluation targets. All are tested under zero-shot, conflict-aware prompting. Each serves as a probe for evidence reliability discernment and bias under cross-source conflicts.
Quantitative Results
ConflictQA results expose profound limitations of SOTA LLMs in robustly reasoning under cross-source conflicts:
Evidence Ordering and Prompt Sensitivity
Models display significant ordering effects: placing correct evidence before contradicting evidence can improve performance in some LLMs that are otherwise susceptible to spurious cues. Reasoning-specialized models are less affected by such ordering, indicating implicit evidence aggregation strategies.
Chain-of-thought (CoT) prompting increases robustness in settings with negative KG evidence but can exacerbate error rates under adversarial text, as the narrative-rich style biases LLMs toward the misleading text.
The XoT Framework: Two-Stage Explanation-Based Reasoning
The paper proposes XoT (Explanation-Over-Thought), a two-stage method for conflict mitigation:
- Candidate Enumeration: The LLM is tasked with listing all plausible answers derivable from any evidence type, accompanied by brief, evidence-grounded explanations (without explicit source attribution).
- Explanation Aggregation: The LLM then reflects on these explanations, compares conflicts, and selects the final answer(s) based on aggregated justification.
XoT aims to force explicit conflict exposure and defers evidence arbitration to a dedicated, explanation-focused stage. This mitigates implicit evidence bias and enables more balanced reasoning under heterogeneity.

Figure 5: Case study showing GPT-4o predictions under different prompts—XoT uniquely yields the correct answer by explicitly structuring evidence and explanations.
Experimental Results with XoT
Across six representative LLMs, XoT delivers:
- Incremental and, in many cases, dramatic improvements in F1 and EM under TripleConf (KG conflict) and COMP settings—up to a 183% relative gain in F1 for Open-Mistral-7B in COMP; 111% F1 gain with Qwen3-8B in Non-COMP.
- Consistent performance across settings for stronger models (e.g., GPT-4o, GPT-3.5-Turbo-0125), with performance sometimes outstripping reasoning-specialized LLMs, indicating XoT’s alignment with high-capacity architectures.
- Variable gains under TextConf: While XoT helps for some models, LLMs with poor reliability assessment of textual evidence can still be misled—no prompting strategy fully eradicates this bias if the model’s internal heuristics dominate.
These results underscore both the challenge and partial effectiveness of methodical, explanation-structured prompting for faithful cross-source reasoning.
Theoretical and Practical Implications
ConflictQA exposes the brittleness of LLMs faced with heterogeneous, adversarial, or inconsistent knowledge—a practical risk in domains such as legal, medical, and scientific QA, where text and structured facts cannot be assumed consistent. The findings directly inform the design of RAG systems: simply aggregating evidence from multiple external sources does not guarantee reliability, and may systematically mislead even SOTA LLMs.
The XoT framework demonstrates a viable path for mitigating (but not eliminating) such risks without supervision or model-specific fine-tuning. It also provides a modular testbed for the development of more sophisticated arbitration (e.g., model-based source trust estimation or iterative evidence pruning).
Future Directions
The ConflictQA benchmark and XoT framework open avenues for:
- Extending cross-source conflict benchmarks across more modalities (tables, semi-structured data, image-text, etc.).
- Developing architectures and prompt-composition strategies capable of evidence reliability estimation, adversarial evidence detection, and context-sensitive arbitration.
- Investigating interventions at retrieval, ranking, and reranking layers to reduce the prevalence of adversarial evidence at the point of prompting.
Conclusion
This study establishes the first systematic evaluation paradigm for LLM reasoning under cross-source knowledge conflicts. ConflictQA reveals consistent and severe limitations in LLM faithfulness across diverse state-of-the-art models when external evidence diverges. XoT, a model-agnostic, explanation-based prompting framework, achieves robust gains in most conflict scenarios—particularly for models and settings that are otherwise severely compromised by evidence heterogeneity. Nevertheless, fully robust cross-source conflict resolution in LLMs remains elusive, especially in the presence of adversarial or narrative-rich misleading evidence.
The tools and findings herein will form a critical foundation for future developments in reliable, heterogeneous-knowledge-grounded LLM reasoning.
Reference: “Exploring Knowledge Conflicts for Faithful LLM Reasoning: Benchmark and Method” (2604.11209).