- The paper presents a dual-encoder architecture that integrates region-aware mask prompting with visual and textual inputs for enhanced segmentation under sparse annotations.
- It achieves significant improvements in Dice and boundary metrics across benchmarks (LA2018, KiTS19, LiTS), outperforming previous state-of-the-art methods.
- The framework employs dynamic loss balancing and a triple-view strategy to effectively propagate sparse labels into dense pseudo-labels for reliable 3D segmentation.
Region-Aware Dual-Encoder Auxiliary Learning for Barely-Supervised Medical Image Segmentation
Introduction
The paper "RADA: Region-Aware Dual-encoder Auxiliary learning for Barely-supervised Medical Image Segmentation" (2604.11164) addresses the critical limitations in medical image segmentation posed by annotation scarcity, specifically focusing on barely-supervised learning (BSL) where only a few labeled slices per volumetric scan are available. Traditional fully and semi-supervised approaches for 3D medical image segmentation are annotation-intensive and thus impractical for large-scale or clinical deployment. Prior BSL methods rely primarily on geometric label propagation, resulting in pseudo-labels that lack pixel-level semantic granularity, especially in scenarios with ambiguous anatomical boundaries or intensity variations.
To tackle these deficiencies, the authors propose RADA, a region-aware dual-encoder auxiliary learning framework. RADA integrates both visual and textual modalities, leveraging a dual-pathway feature extraction strategy pre-trained with Alpha-CLIP. Region-aware supervision is provided by explicitly introducing sparse, annotated mask prompts as auxiliary spatial guidance, substantially enhancing the discriminative power of extracted features under severe annotation constraints. The resulting design enables robust multi-view 3D segmentation even when only three orthogonal slices per scan are labeled.
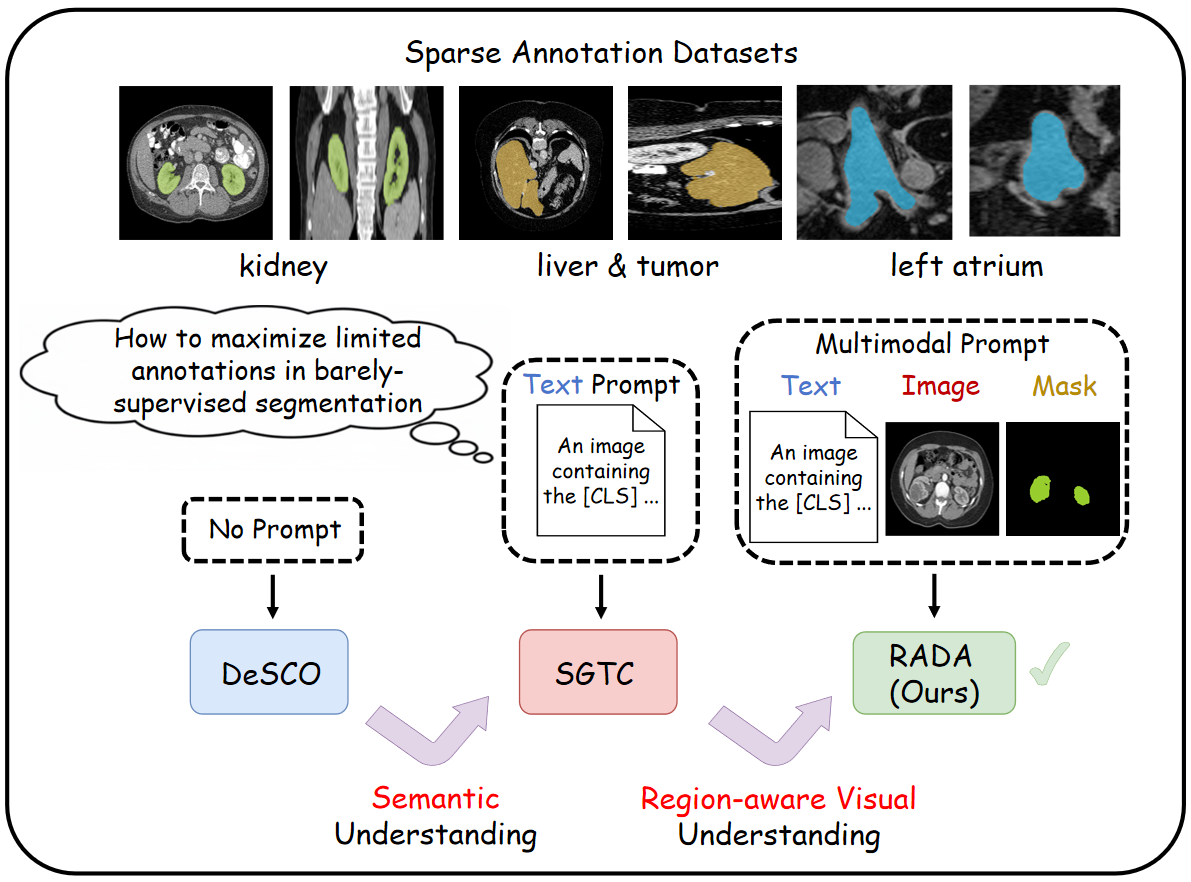
Figure 1: High-level comparison of prompt-based paradigms for barely-supervised medical image segmentation: geometric-only (DeSCO), text-prompted (SGTC), and the multimodal prompt fusion of RADA.
Methodology
RADA employs a dual-encoder architecture, fusing region-aware visual features and domain-specific semantic guidance. The visual encoder extracts fine-grained, region-targeted features from the original volumetric image and the binary mask using a frozen Alpha-CLIP backbone. The text encoder processes explicit medical-domain prompts (e.g., "An image containing the [CLS], with the rest being background") to generate categorical embeddings. Cross-modal alignment is achieved through a lightweight, trainable Adapter module that concatenates and transforms the resulting embeddings, bridging the inherent domain gap between CLIP pretraining (on natural images and text) and medical volumes.
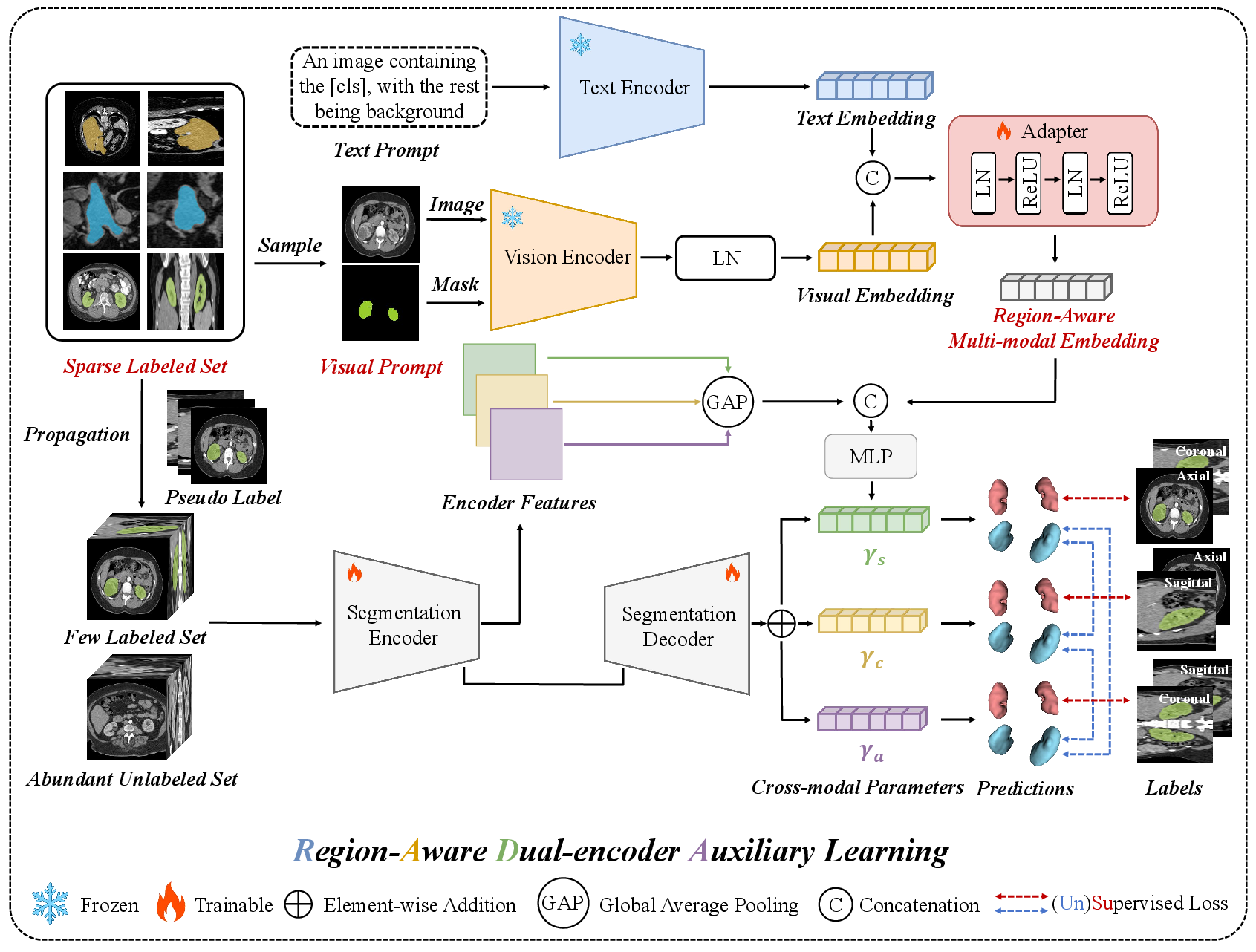
Figure 2: The RADA pipeline, illustrating dual-encoder feature extraction, cross-modal fusion via an Adapter, and triple-view 3D segmentation with pseudo-label propagation and auxiliary learning.
Segmentation is performed using three parallel 3D sub-networks, each dedicated to one orthogonal anatomical plane (sagittal, coronal, axial). Cross-modal fused features serve as auxiliary guidance, injected into decoder heads via an MLP-derived parameterization that conditions predictions on both visual and textual context. Sparse annotations are expanded through registration-based label propagation, yielding dense pseudo-labels whose reliability is weighted based on proximity to true annotations (with a tunable decay rate). Supervised and unsupervised losses are dynamically balanced to exploit both true and pseudo-labels, with further regularization via triple-network cross-supervision on unlabeled volumes.
Experimental Results
RADA is evaluated on three public benchmarks: LA2018 (left atrium), KiTS19 (kidneys/tumors), and LiTS (liver), under a strict 10% annotation regime (three orthogonal slices per scan). Quantitative results demonstrate consistent improvement over prior SOTA methods (including DeSCO and SGTC):
- LA2018: RADA achieves 0.8652 Dice and 0.7634 Jaccard, surpassing SGTC by >2% Dice margin.
- KiTS19: RADA records 0.9448 Dice, with significant reductions in boundary error (HD 3.09).
- LiTS: Dice and Jaccard of 0.9363 and 0.8809 (respectively), setting new benchmarks in extremely sparse annotation settings.
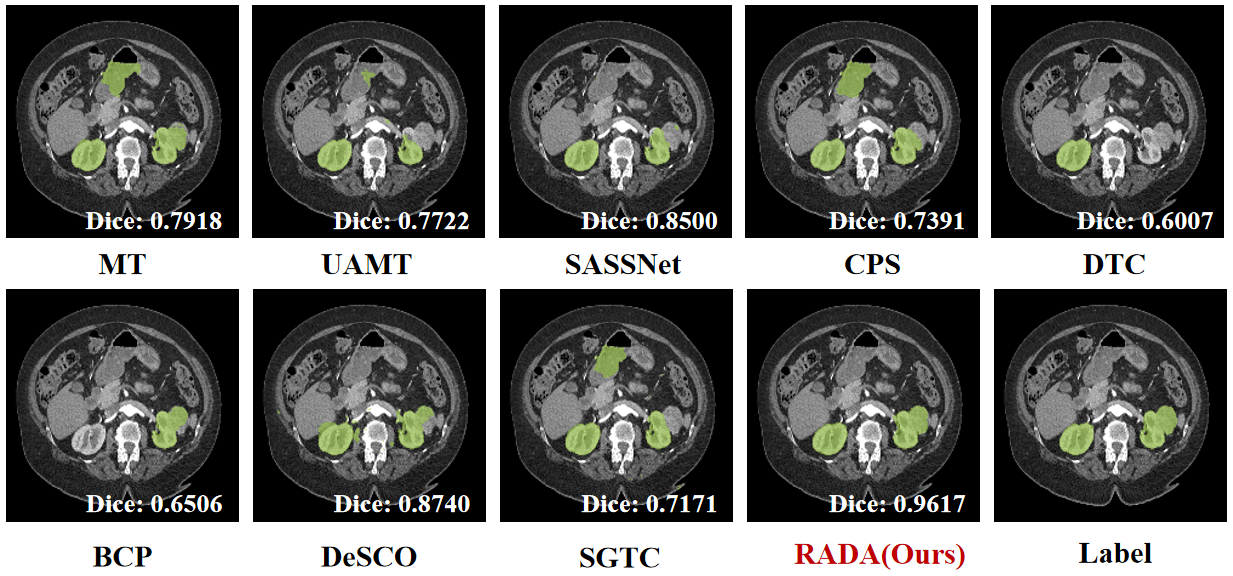
Figure 3: Performance comparison on KiTS19 at 10% labeled data, highlighting RADA's superior Dice and boundary metrics.

Figure 4: Quantitative comparison on LA2018 demonstrating RADA’s consistent performance advantage over competitors.
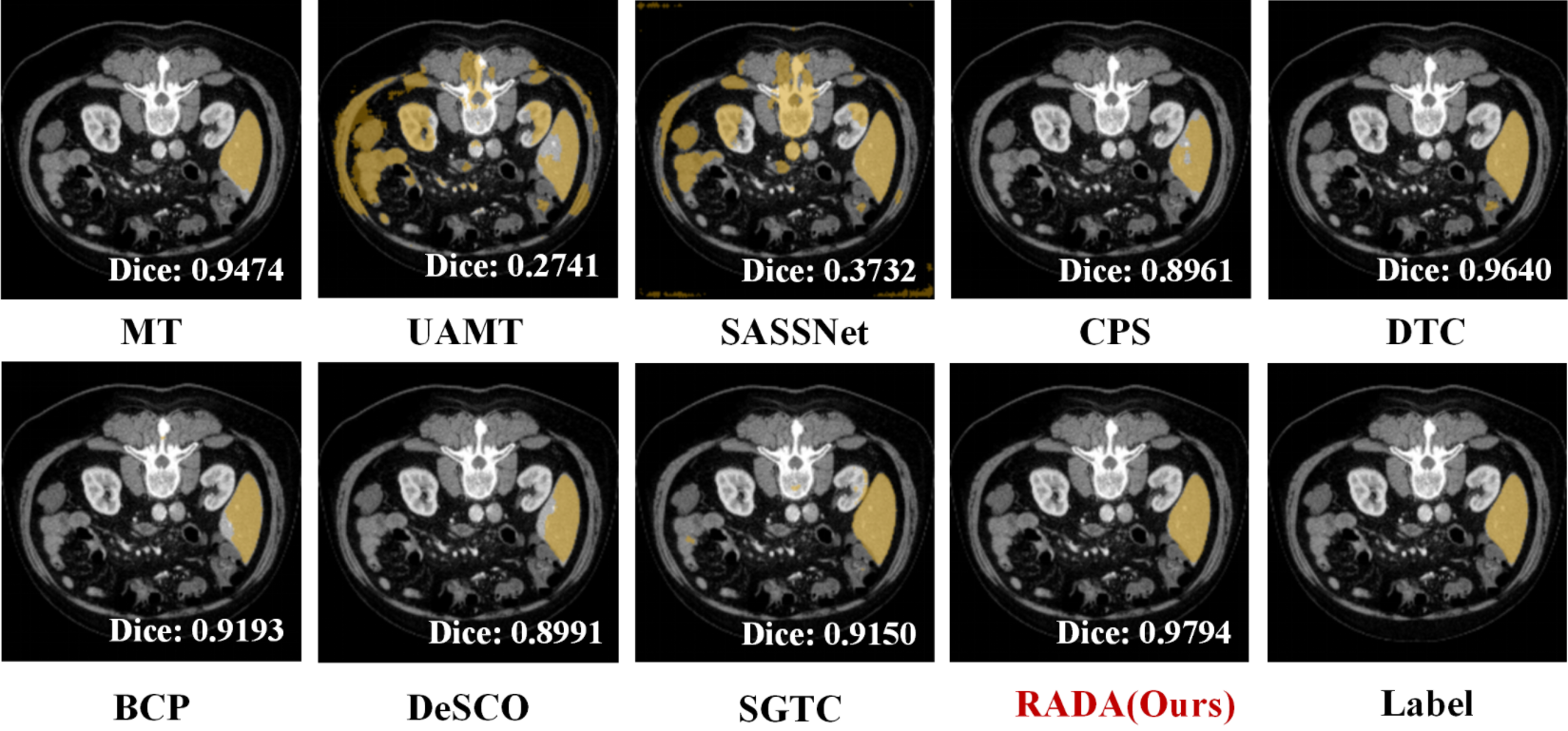
Figure 5: Dice and Jaccard improvement on LiTS under barely-supervised conditions as achieved by RADA.
Crucially, boundary-aware metrics (HD, ASD) consistently favor RADA, validating its efficacy for precise anatomical delineation where traditional geometric propagation or text-only prompt approaches degrade. Qualitative assessment via Grad-CAM reveals more focused and confident activations within regions of interest, indicating improved interpretability and reliability.
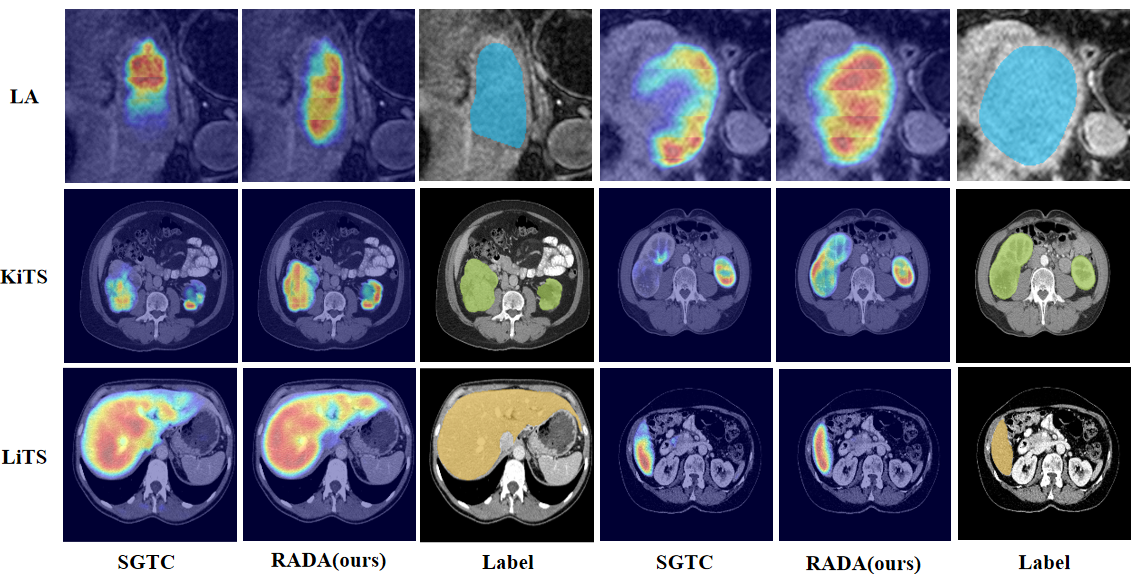
Figure 6: Grad-CAM visualizations on LA2018, KiTS19, and LiTS demonstrate RADA’s focused, high-confidence region activation compared to alternatives.
Analysis and Ablation
Ablation studies decompose the contributions of visual prompting, mask prompting via Alpha-CLIP, registration-based augmentation, and the effect of textual prompt variants. Key findings include:
- Region-aware mask prompting is essential; adding mask prompts to the visual encoder (Alpha-CLIP vs. vanilla CLIP) yields substantial Dice improvements (up to 2.5% absolute gain).
- Text prompt design significantly impacts performance—the optimal formulation ("An image containing the [CLS], with the rest being background") delivers maximal segmentation accuracy, supporting the need for explicit semantic separation in medical contexts.
- Dynamic loss balancing for supervised/unsupervised terms (parameter β) outperforms static settings, stabilizing training and enhancing final accuracy.
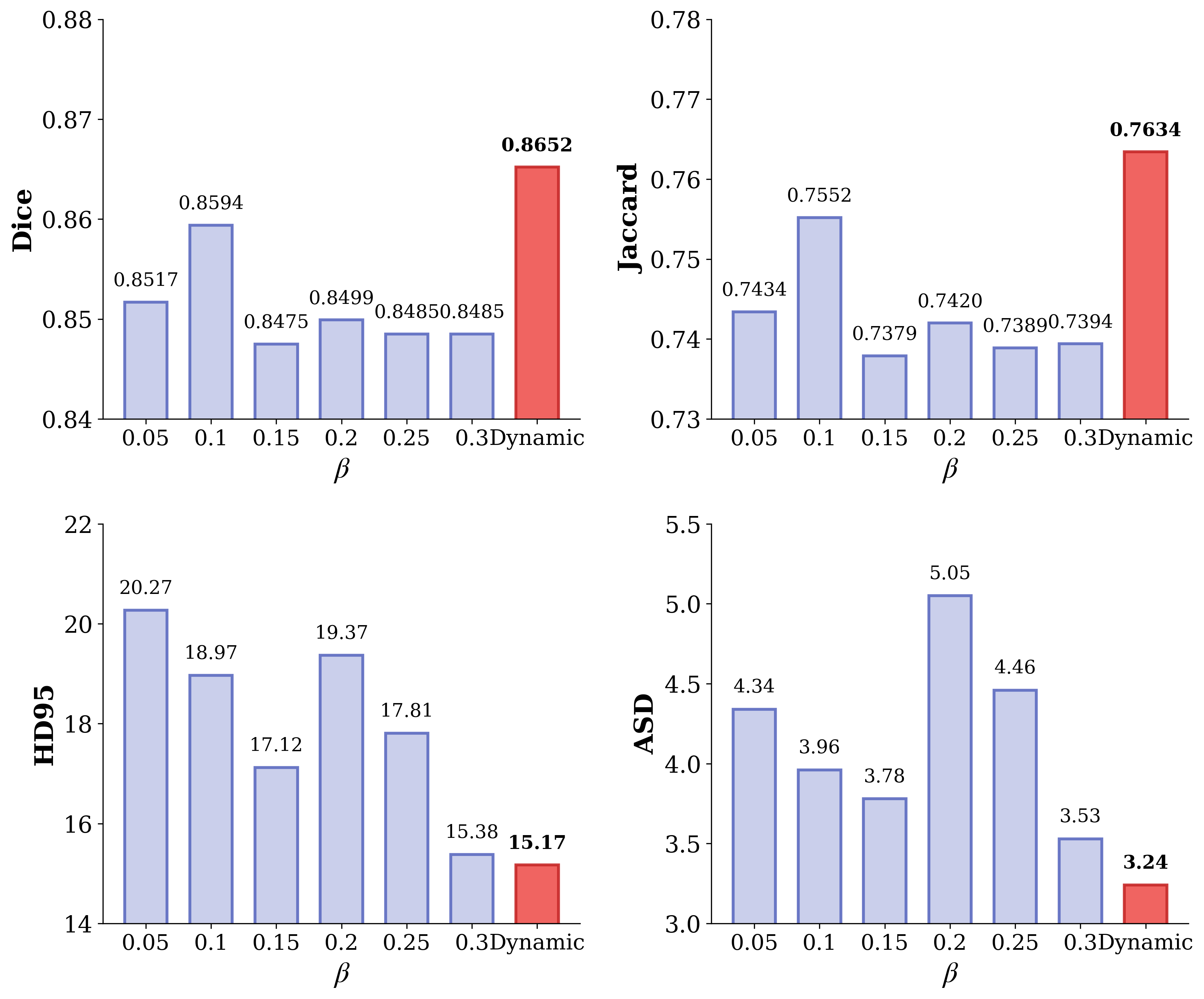
Figure 7: Dynamic parameter β analysis confirms that adaptive supervision-unsupervised balance yields best Dice on LA2018.
- View and slice selection ablation demonstrates robust orthogonal triple-view training as optimal, with orthogonality outperforming parallel or single-plane strategies across datasets.
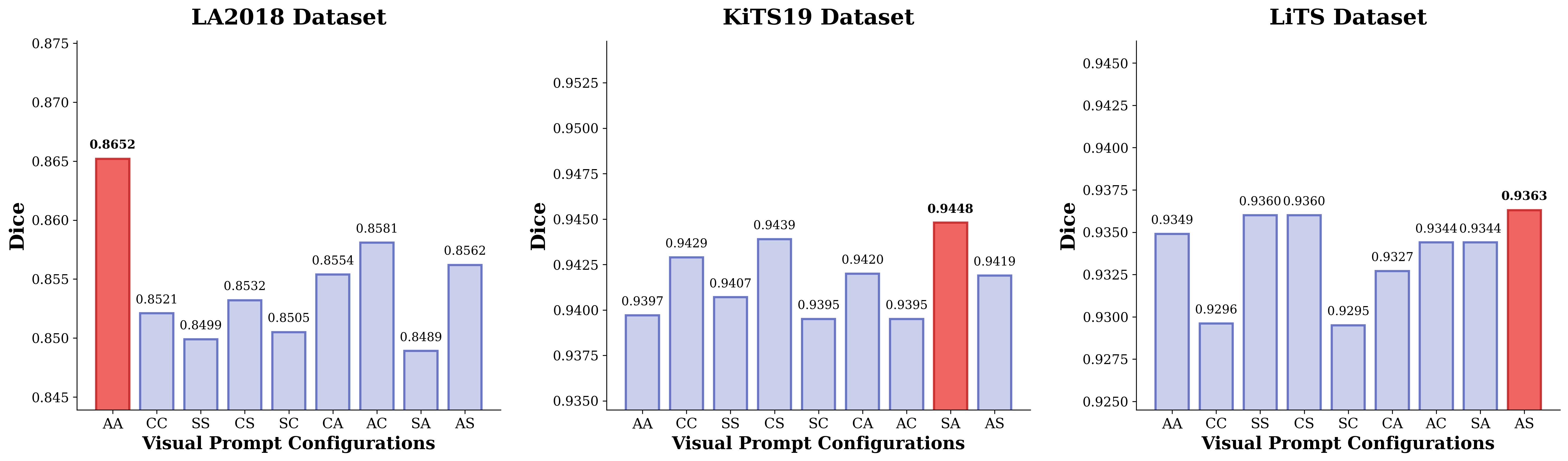
Figure 8: Visual prompt ablation across datasets, with red bars indicating optimal orthogonal view combinations for each anatomical target.
Implications and Future Directions
RADA's integration of explicit region-aware prompting with pre-trained multimodal encoders and unsupervised label expansion redefines the limits of barely-supervised learning in medical segmentation. The results demonstrate that pixel-level supervision can be extrapolated robustly from annotation-minimal regimes when dense, structured visual-language alignment is leveraged, and spatial priors are introduced via region-specific masks.
This work suggests several future research avenues:
- Extension to multi-organ and multi-class volumetric segmentation scenarios leveraging anatomical atlases as additional textual priors.
- Integration with weak labeling sources (e.g., scribble-based, bounding box, point) to further minimize annotation effort.
- Investigation of generalization to rare disease datasets and longitudinal imaging, exploiting RADA’s robust cross-modal transfer under extreme data scarcity.
- Exploration of task-specific prompt engineering to enhance CLIP-based feature alignment for other clinically relevant targets (e.g., tumor sub-regions, treatment response monitoring).
Conclusion
RADA represents a scalable, annotation-efficient framework for 3D medical image segmentation under extremely sparse supervision. By tightly coupling region-aware visual prompting, explicit text-guided semantics, and advanced pseudo-label propagation, RADA achieves SOTA performance across diverse anatomical structures. This paradigm substantially reduces annotation demands without sacrificing segmentation precision or generalization, informing both practical deployment in clinical pipelines and theoretical advances in multimodal, semi/self-supervised representation learning for medical imaging.
References:
- "RADA: Region-Aware Dual-encoder Auxiliary learning for Barely-supervised Medical Image Segmentation" (2604.11164)