- The paper proposes a quantum-gated framework that projects sample and task features into a quantum Hilbert space to dynamically quantify task relevance.
- It employs quantum state fidelity combined with KL-divergence loss for relevance-weighted knowledge transfer, achieving improvements up to +6.5% on challenging benchmarks.
- The method effectively mitigates catastrophic forgetting in class-incremental learning while ensuring parameter efficiency and robust forward transfer.
Quantum-Gated Task-interaction Knowledge Distillation for PTM-based Class-Incremental Learning
Introduction and Motivation
Incremental learning under a task-agnostic, exemplar-free protocol remains a central challenge due to subspace entanglement and catastrophic forgetting caused by overlapping feature representations across tasks. While recent protocols capitalize on strong feature extractors provided by Pretrained Transformers (PTMs), both prompt-based and adapter-based CIL algorithms suffer from inflexible task-level routing. These methods employ either non-adaptive, feature-similarity retrieval (prompts) or parameter-isolated adapters with naive fusions, both of which are insufficient for modeling complex inter-task relationships when task identities are unknown. The absence of an explicit, dynamic, and learnable task-interaction mechanism greatly constrains forward and backward transfer, limiting the potential of PTM-based parameter-efficient fine-tuning (PEFT) strategies.
The QKD framework introduces a quantum-gated task modulation mechanism. This module computes sample-to-task relevance by embedding both sample features and learned task representations in a quantum Hilbert space, leveraging quantum state overlap (fidelity) to estimate and weight multi-adapter knowledge transfer. This proposal directly addresses nontrivial subspace entanglement and adaptivity issues in CIL scenarios, coupling quantum representational expressivity with relevance-guided knowledge distillation.
Methodology
The QKD framework decomposes into two core modules: quantum-gated task modulation (QGTM) for relevance quantification, and task-interaction knowledge distillation (TIKD) for relevance-weighted inter-adapter knowledge transfer.
Quantum-Gated Task Modulation
QGTM quantifies sample-to-task relevance by projecting SVD-reduced representations of both the input sample and task-specific adapters into a quantum circuit parameterized by learnable real-valued rotation angles. The circuit consists of:
- Data encoding via single-qubit Ry rotations of normalized sample features.
- Learnable variational rotations for enhanced task adaptivity.
- Entanglement via CNOT chains to capture high-order cross-component correlations.
The propagated quantum states encode both the sample and all prior task adapters. Their mutual geometric proximity is quantified by the fidelity (inner product squared) of quantum states, effectively leveraging quantum superposition to capture complex overlaps.
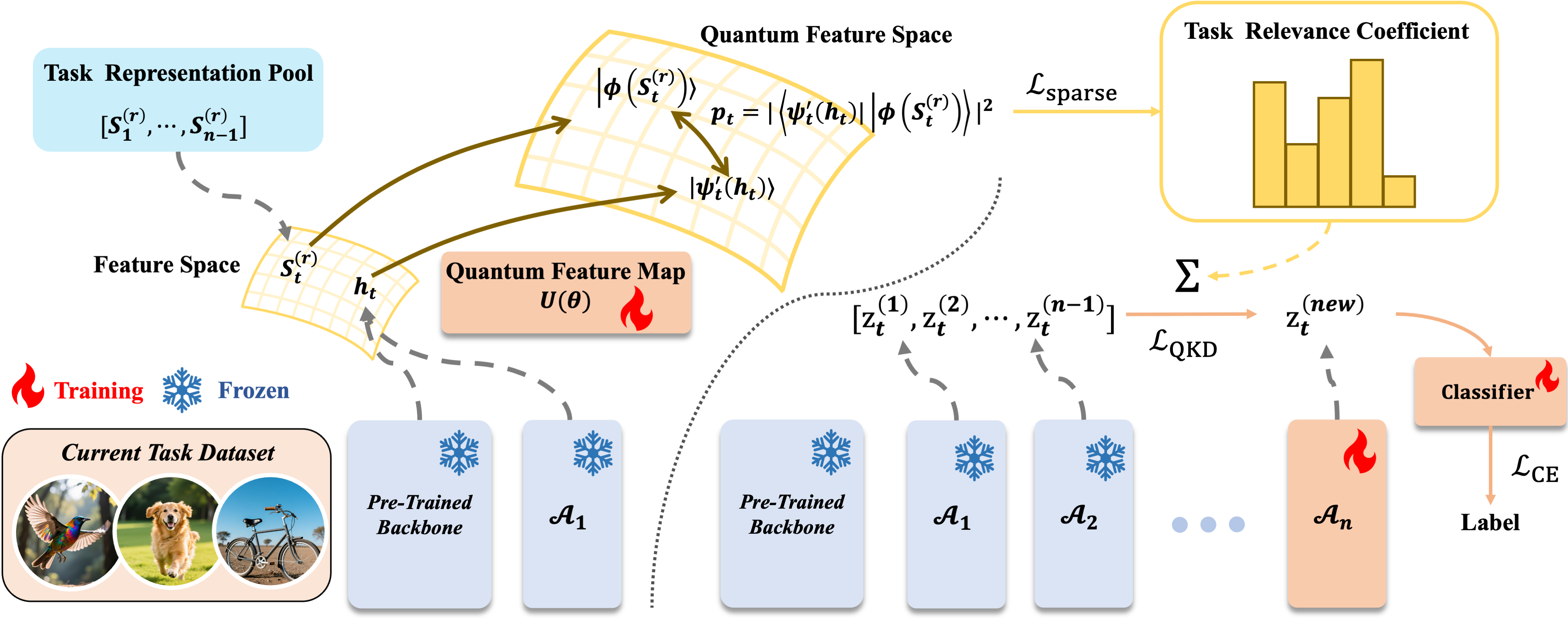
Figure 1: Schematic of QKD: The frozen PTM and base adapter encode the sample; previous adapters form a task pool whose dominant directions are SVD reduced, projected to quantum states, and measured for sample-to-task relevance, modulating both training-time distillation and inference fusion.
Sparsity is encouraged on the resulting task-attention vector via L1 regularization, ensuring only salient historical tasks inform the current learning process. Finally, temperature-softmax normalization yields inference-adaptable task relevance coefficients.
Relevance-Guided Knowledge Distillation
The quantum-derived relevance scores αi directly modulate a KL-divergence-based feature distillation loss among adapters, enforcing that each prior adapter contributes to the new adapter training in proportion to quantum-inferred task similarity. The explicit objective is:
LQKD=i=1∑t−1αiKL(σ(zt(i))∥σ(zt(new)))
where zt(i) indicates the logits from the ith adapter and σ is softmax.
The total loss further includes supervised classification and sparsity penalties. During inference, the same quantum modulation is used to adaptively fuse or select task adapters in a task-agnostic regime.
Experimental Results
Datasets and Protocol
The evaluation adopts five benchmarks (CIFAR-100, CUB-200, ImageNet-A, ImageNet-R, and VTAB), strictly under an exemplar-free regime and standard “B-m Inc-n” splits. The backbone is a frozen ViT-B/16-IN21K, adapters use bottleneck dimension r=64, SVD truncation dimension is 12, and quantum circuits employ 3–15 qubits.
QKD consistently outperforms all state-of-the-art PEFT CIL baselines across all benchmarks, both in final and average accuracy. Notably, QKD's gains over the second-best method exceed 2% on multiple benchmarks, and reach up to +6.5% in final accuracy for challenging out-of-distribution datasets (e.g., ImageNet-A) without utilizing any exemplars.
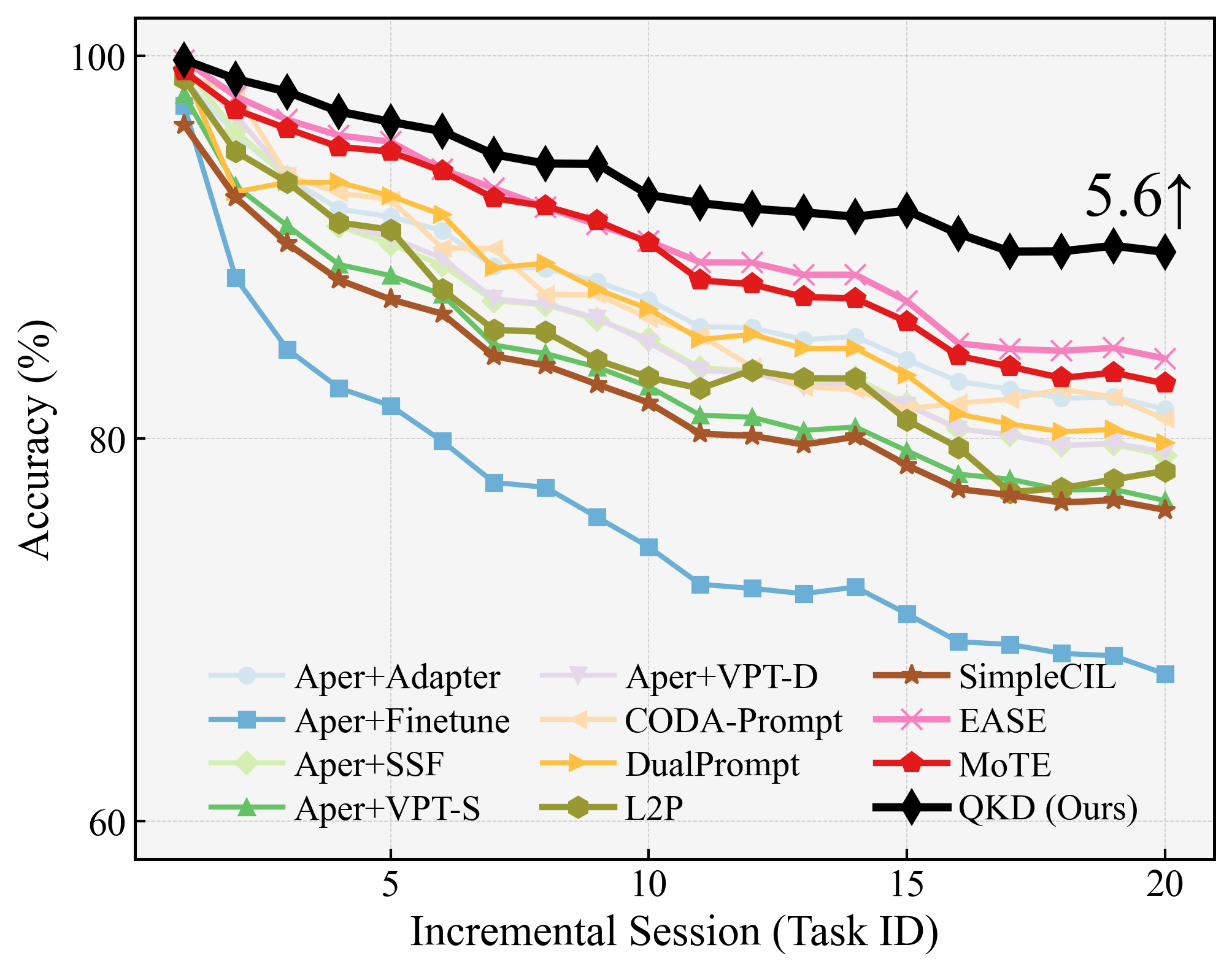
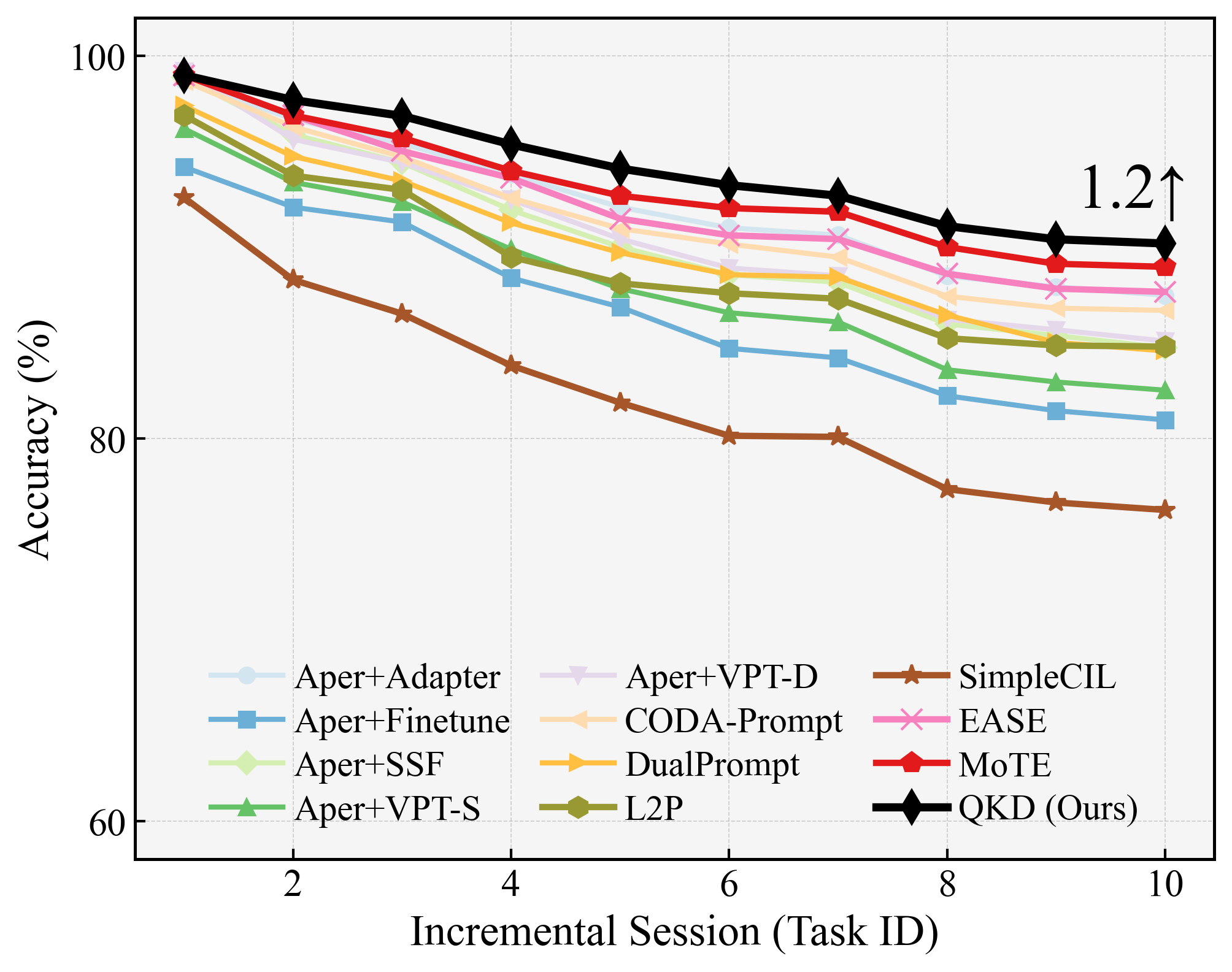
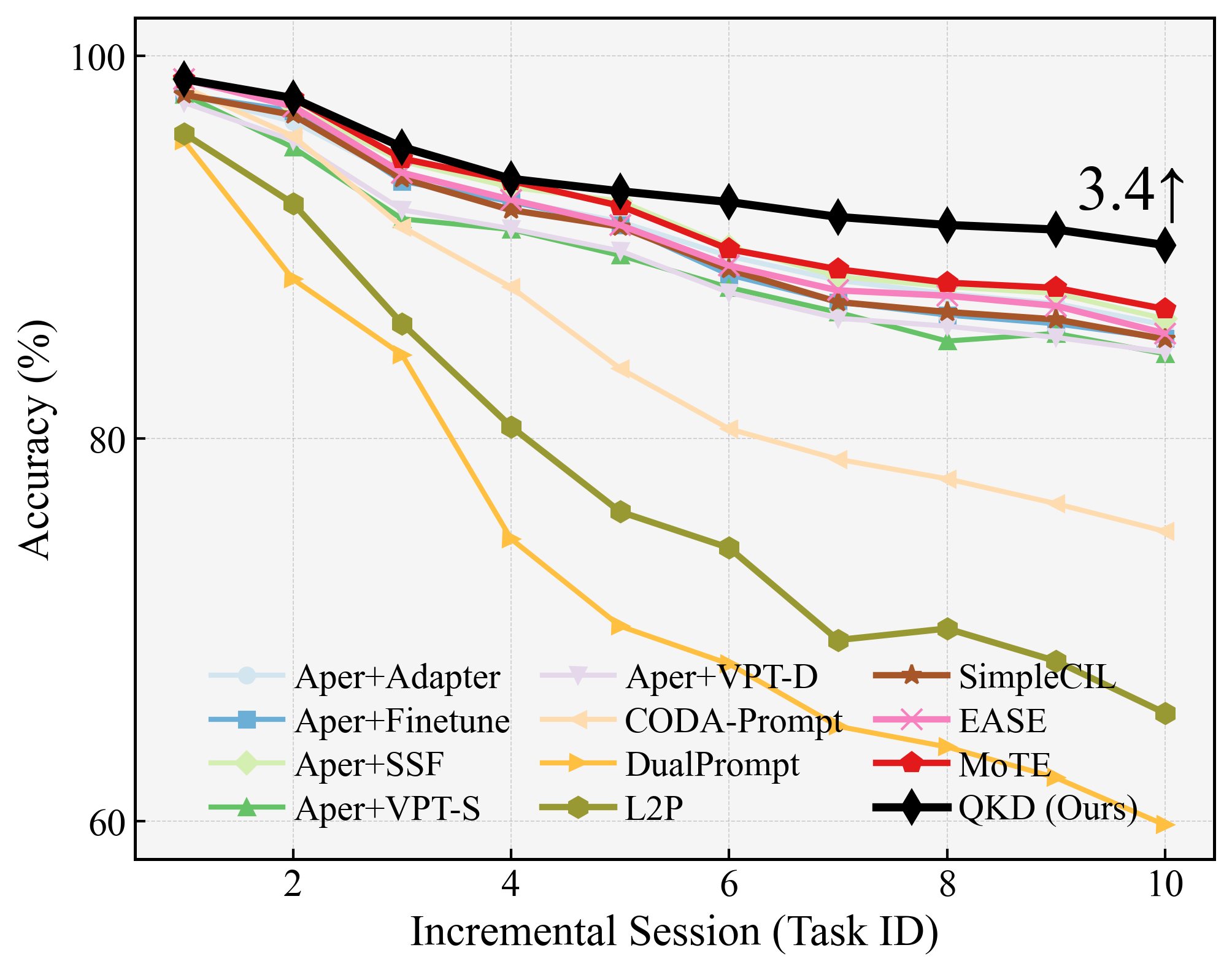
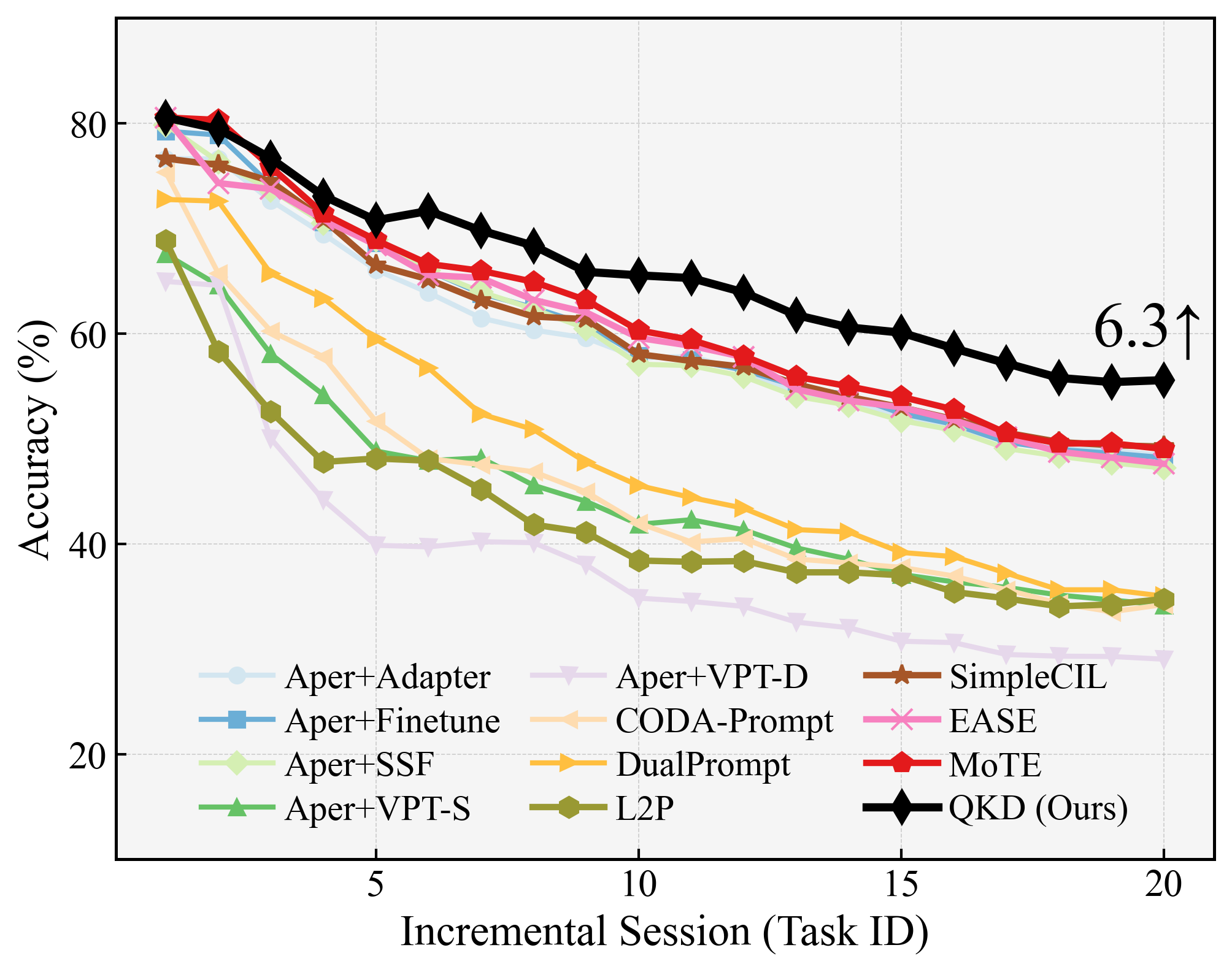
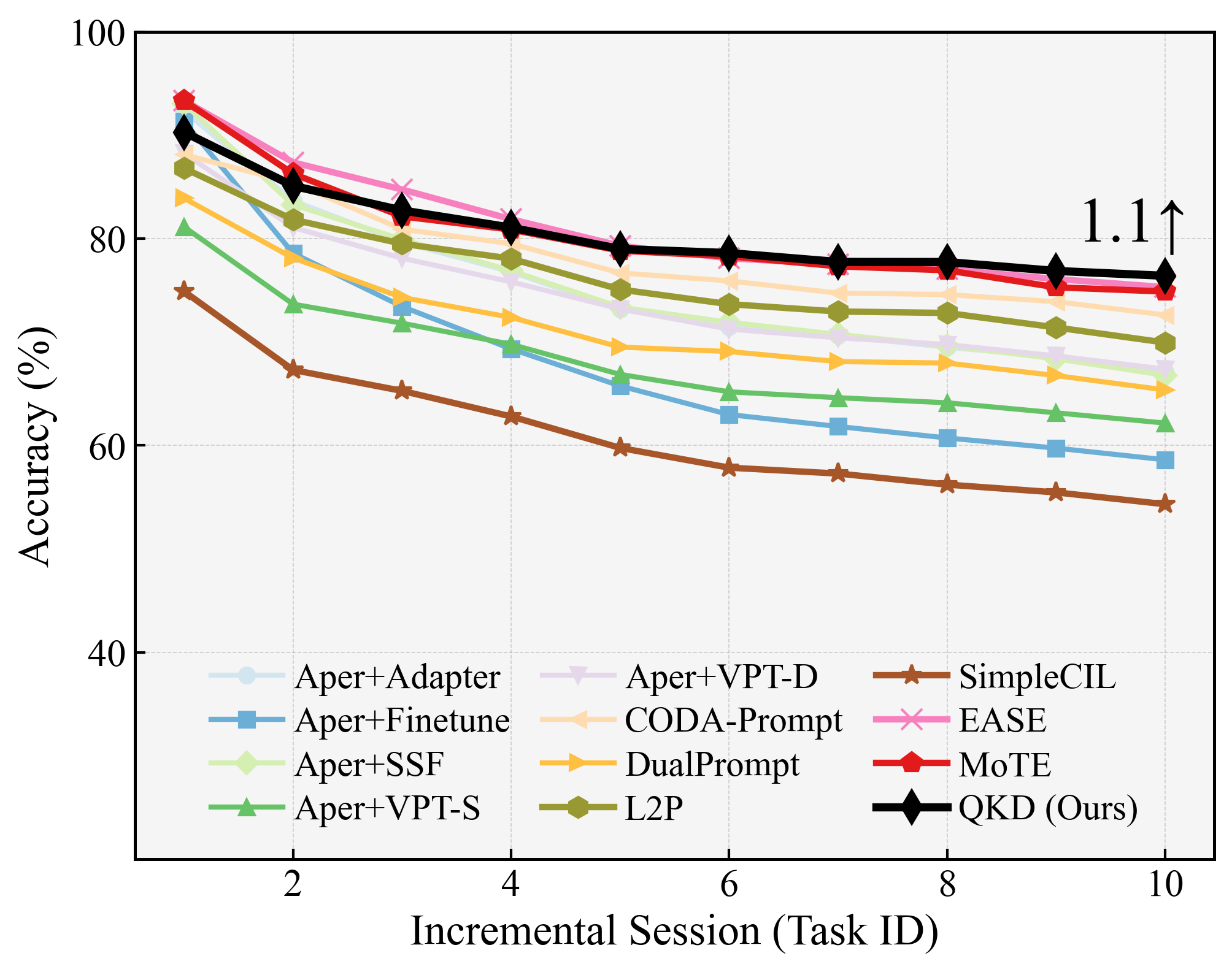
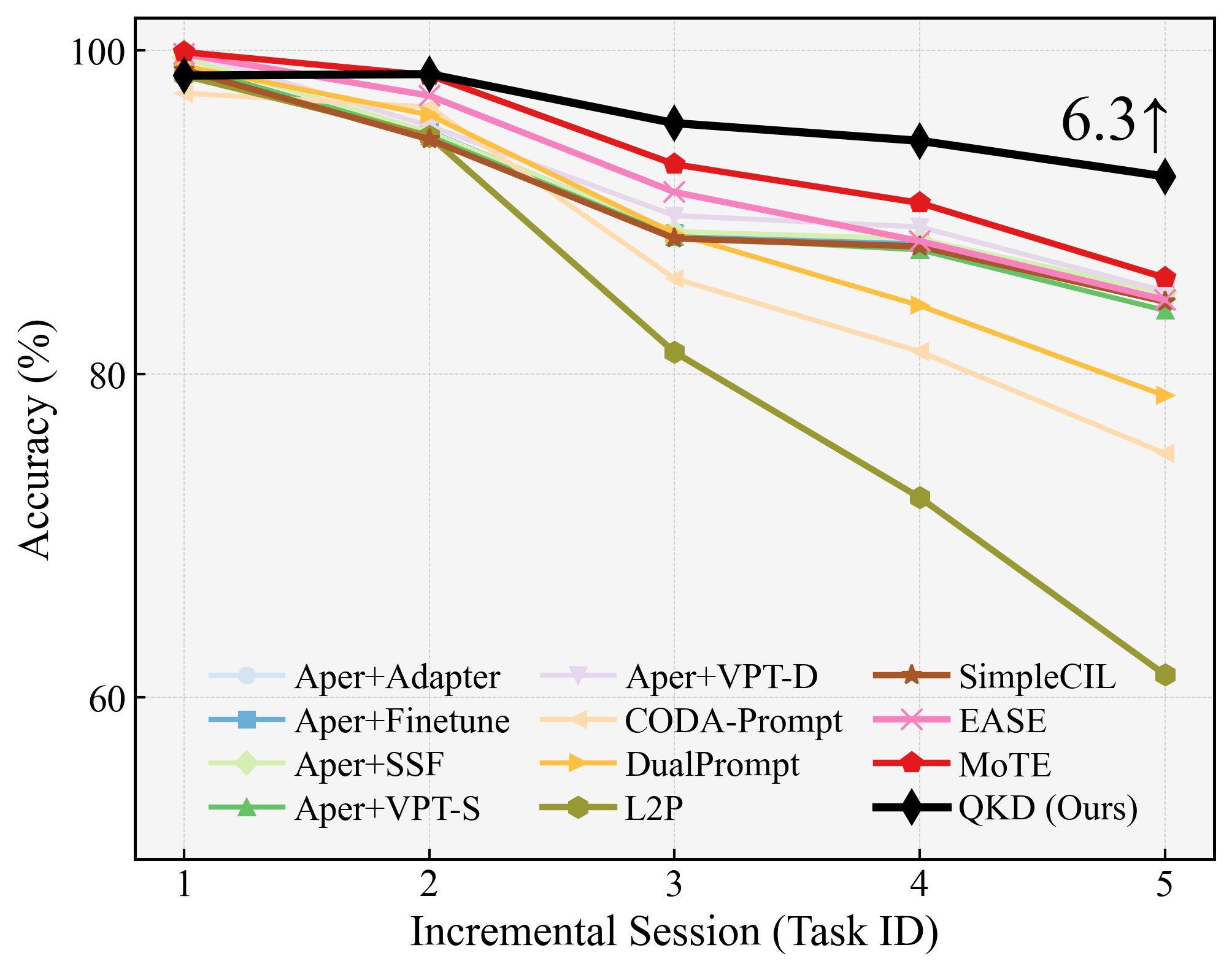
Figure 2: Class-incremental learning accuracy on CIFAR-100 (B0-Inc5) throughout all stages, highlighting the relative gains of QKD.
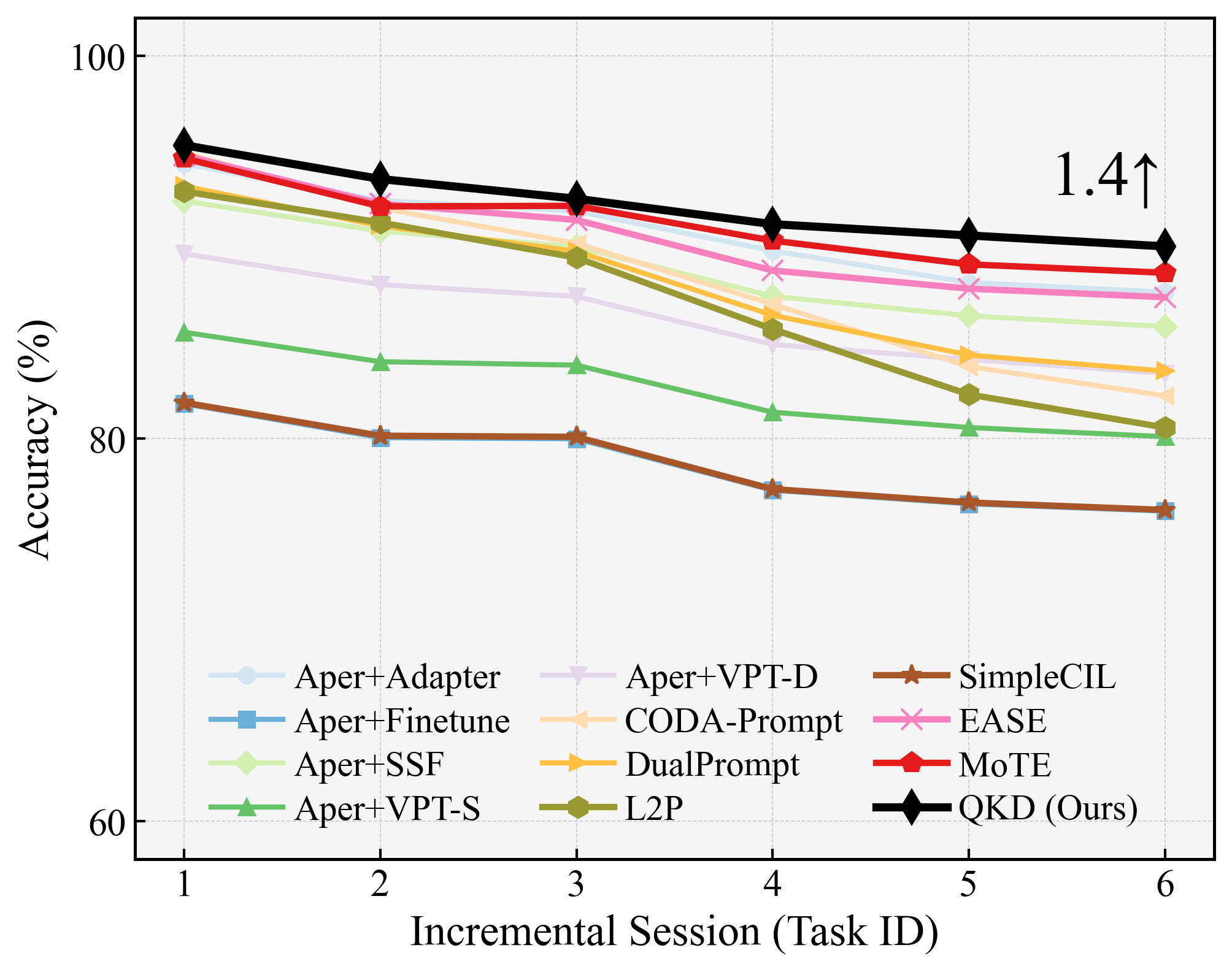
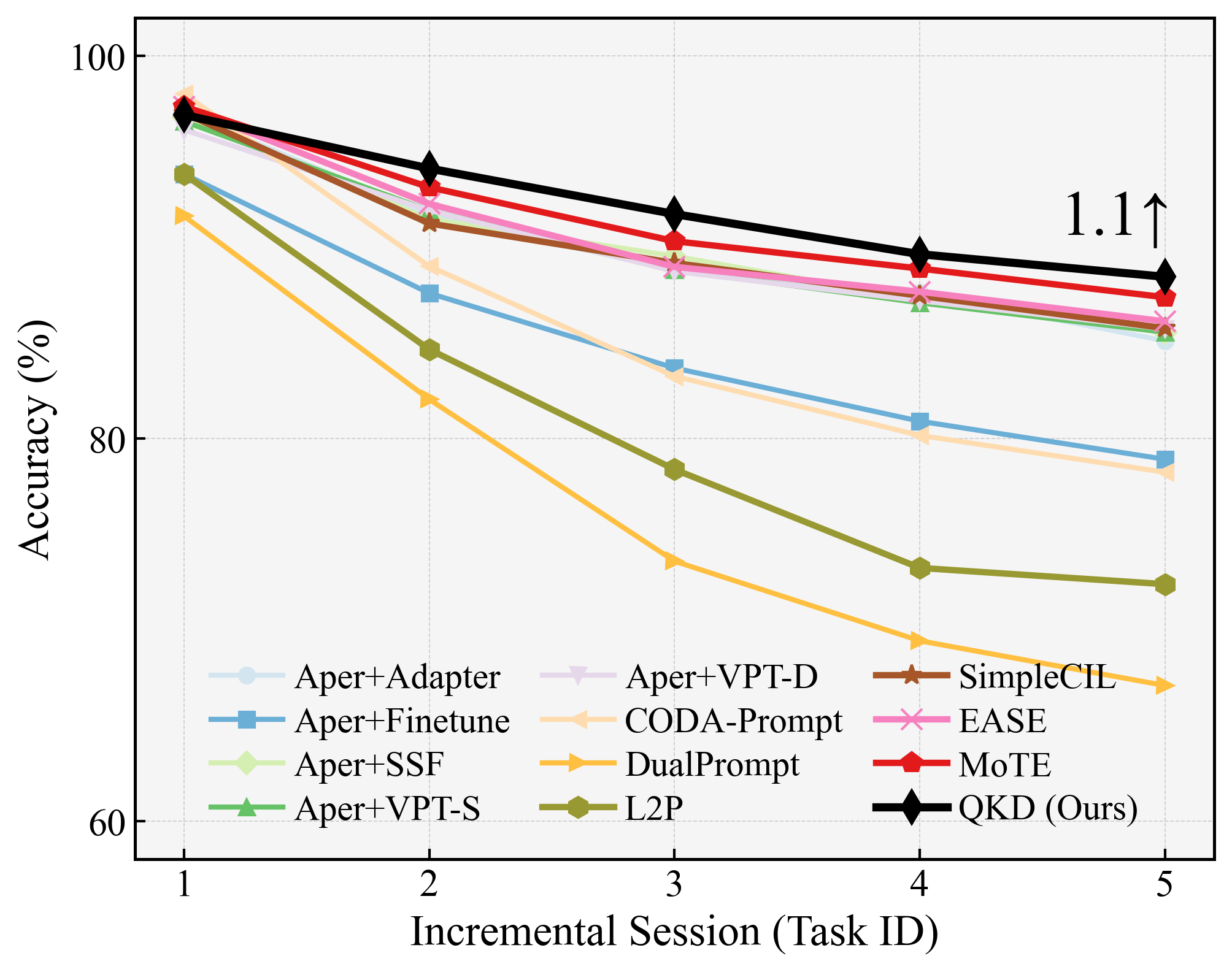
Figure 3: Stage-wise performance on CIFAR-100 (B50-Inc10), demonstrating the stability and forward transfer advantages of quantum gating.
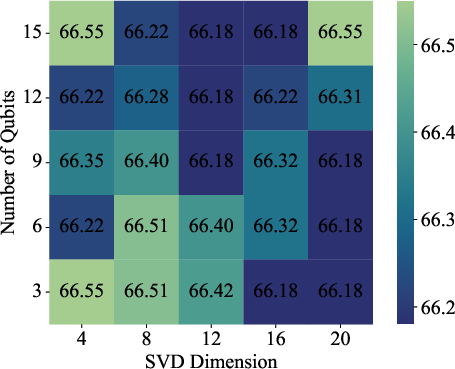
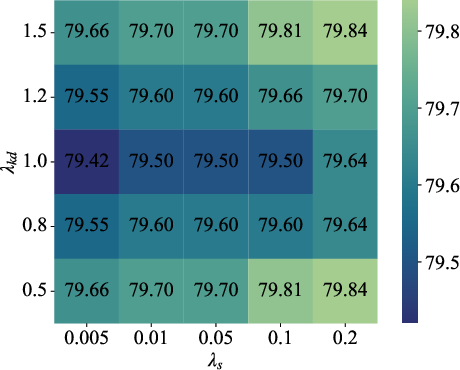
Figure 4: Incremental accuracy on ImageNet-A (B0-Inc20), showing robustness of QKD under severe distribution shifts and high class-count scenarios.
Ablation studies show that removing quantum gating or distillation terms produces dramatic performance degradation, validating the significance of Hilbert-space sample-task projection for dynamic routing and transfer.
Analysis of Task Recognizers
Tabled comparison shows that quantum gating introduces minimal computational and memory overhead relative to MLPs, cosine similarity, and attention, while always improving accuracy (+1% or more on all major datasets). The system is robust to hyperparameters such as SVD dimension, number of qubits, and loss coefficients.
Analysis demonstrates that using the base-task adapter (A1) for sample feature extraction suffices for robust quantum projections; stacking further adapters yields marginal improvements at nearly doubled computational cost.
Implications and Prospects
QKD formalizes task interaction in CIL as a quantum mutual information estimation challenge, moving beyond heuristic similarity routing or strict subspace isolation. This results in two principal advances:
- Task-aware router generalization: The quantum circuit learns complex cross-adapter dependencies, ideal for high-dimensional entangled PTM representations where classical similarity metrics collapse.
- Principled, adaptable transfer: By weighting knowledge distillation with quantum mutual information, QKD avoids both negative backward transfer and insufficient forward transfer, leading to improved retention and forward generalization.
Potentially, such quantum-score task modulations are extensible to multi-modal or continual learning regimes, especially as quantum-inspired kernel methods and quantum processors mature. Since the quantum circuit is trainable end-to-end, it could further adapt to other parameter-efficient architectures or model surgical approaches.
Conclusion
QKD represents a principled integration of quantum machine learning and PTM-PEFT CIL, introducing sample-adaptive, learnable routing for knowledge transfer via quantum Hilbert spaces. Its strong empirical performance under the stringent exemplar-free regime and robust ablation evidence affirm the criticality of explicit, dynamical modeling of task interactions. This methodology offers an extensible approach for mitigating catastrophic forgetting and is positioned to inspire further hybrid quantum-classical methodologies for continual learning and beyond.

