- The paper proposes a novel integration of LLM-generated counterexamples with dynamic specification inference to systematically eliminate spurious contracts.
- Methodology combines SpecFuzzer’s candidate generation with LLM-driven test synthesis, showing up to a 7 percentage point improvement in precision.
- Empirical results highlight robust reduction of false positives and demonstrate the potential for automated oracle triage in software specification mining.
Leveraging LLM-Generated Counterexamples to Enhance Dynamic Specification Inference
Introduction and Motivation
Dynamic specification inference frameworks, particularly exemplified by Daikon, have enabled automated contract assertion synthesis via runtime trace analyses. However, such approaches exhibit a major precision/recall tradeoff tightly bound to the diversity and coverage of the underlying test suites. While grammar-based or evolutionary enhancements (e.g., in SpecFuzzer or EvoSpex) have extended the expressiveness of predicate templates, the process consistently suffers from “false positives”: postconditions that are consistent with the sampled traces but are invalid in general program executions.
The paper “Improving Dynamic Specification Inference with LLM-Generated Counterexamples” (2604.10761) proposes to tightly couple LLM-based test generation with the dynamic inference loop to systematically identify and eliminate these spurious contracts. Here, the LLM is not used for general test generation or direct assertion synthesis, but for focused oracle falsification—generating targeted counterexample tests to challenge only those likely-invariants (i.e., passing the initial dynamic filtering) that await manual triage.
Methodology: Integrating LLM-Guided Falsification
The method introduces an augmented inference pipeline:
- Dynamic Assertion Generation: Candidate postconditions are constructed (using SpecFuzzer's grammar-based fuzzing) and filtered on the initial test suite in the classical style.
- Oracle Verification via LLMs: For each surviving assertion, the LLM is instructed with the program context (class code, focal method, candidate postcondition) to decide its validity. If the assertion is suspected invalid, the LLM is required to synthesize a JUnit counterexample test—an executable evidence that would falsify the assertion.
- Test Suite Augmentation: Only those test cases that compile are appended to the dynamic validation suite. SpecFuzzer is then re-executed to re-filter candidate assertions.
- Evaluation: The refined specification set is compared against curated ground truths, using SAT/SMT solvers for semantic equivalence checking (see benchmark details in the paper).
This design exploits the LLM’s code-level reasoning abilities for local counterexample synthesis, as opposed to directly trusting natural language validity judgments.
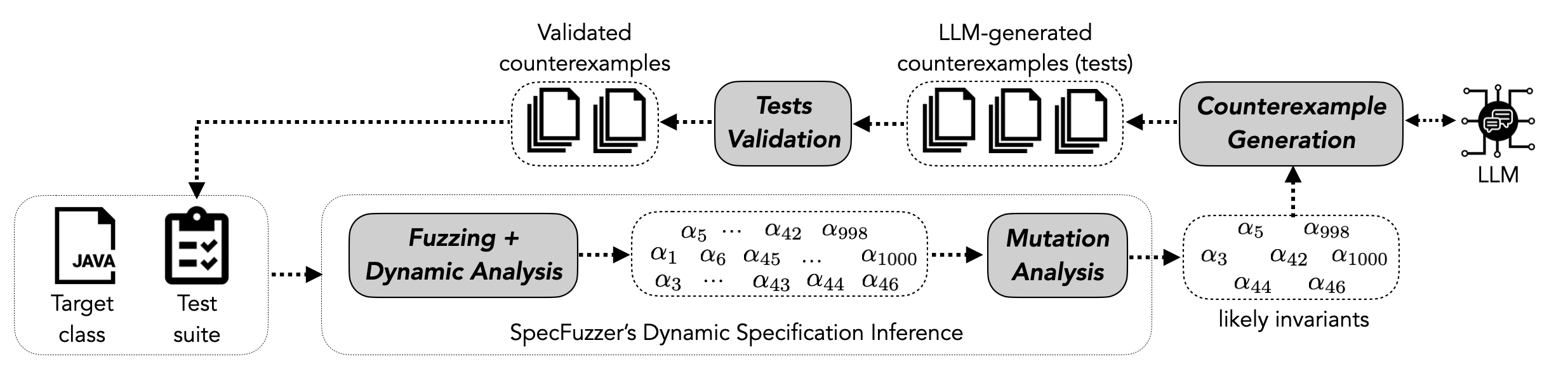
Figure 1: The workflow integrates SpecFuzzer’s dynamic inference with an LLM-orchestrated counterexample generation and assertion revalidation cycle.
Empirical Results and Observations
Effectiveness of Counterexample Generation
Extensive experiments were conducted on a diverse pool of Java methods benchmarked with established contract datasets (e.g., GAssert, EvoSpex, open-source Java libraries). Three SOTA LLMs were evaluated: OpenAI's GPT-5.1, Llama 3.3 70B, and DeepSeek-R1.
Key findings:
- GPT-5.1 reduced false positive postconditions by 10.09%, eliminating 1877 invalid assertions (using 1009 LLM-generated counterexamples across 43 subjects). Precision increased by ~7pp (from 67.83% to 74.17%), while recall was unaffected.
- Llama 3.3 70B generated fewer (430) counterexamples, removing 5.63% of invalid contracts; DeepSeek-R1 generated 3684, discarding 11.68%.
- The findings are robust to LLM family; open models are competitive, though GPT-5.1 demonstrated higher cost-effectiveness per asserted contract falsified.
- Precision improvement is directly attributable to the specific elimination of spurious contracts and not to accidental collateral test coverage.
- In several cases, LLM-generated counterexamples identified actual assertion flaws missed by traditional fuzzing and even revealed errors in hand-curated ground truths.
LLM As Oracle Judge: Failure Modes and Prospects
The experiments show that LLMs can reliably generate compiling counterexamples in the majority of cases (87.2% for GPT-5.1 on “FAILED” verdicts). However, LLMs occasionally mark valid postconditions as invalid (“false alarms”), motivating further upstream filtering for oracle trustworthiness.
Separately, using the LLM verdict directly as a static “oracle” (LLM-as-a-Judge, as per [ZhengLLMAsJudge]) was compared. Precision (64.2%) and recall (83.1%) lag the counterexample-augmented process, indicating that automatic falsification via test synthesis is necessary for minimizing false eliminations.
Implications for Software Specification and Program Analysis
Automating Oracle Triage in Specification Mining
The approach fundamentally shifts the oracle triage workload from manual inspection to automated, LLM-leveraged verification. By generating targeted counterexamples only for those likely-invariants that survive traditional suite-based dynamic analysis, this pipeline decouples oracle strength from suite exhaustiveness—an ongoing practical bottleneck in contract mining adoption. This directly reduces developer effort and increases reliability for downstream applications in automated verification, testing, and program repair.
LLMs for Contract Weakening and Regression Testing
The success of guided counterexample generation opens the door to iterative contract weakening and dynamic co-evolution of test suites and specification candidates. As LLMs are further fine-tuned on the domain of assertion falsification and test case generation, the performance/cost ratio for real integration into specification mining loops will improve further. The paradigm can also extend to regression test minimization and adversarial contract regression detection.
Relation to Broader LLM-in-SE Research
The proposed approach is orthogonal to direct assertion/documentation extraction via LLMs (e.g., [nlp2postcondition2024]); it rather uses the LLM’s synthesis/analysis abilities to instantiate the “oracle improvement” loop at scale. This sits at the intersection of prior “neural oracles” and mutation-driven test-based inference, but avoids the proliferation of tautological or overfit contracts ([gassert2020], [togll2024]).
The design decision to always revalidate assertions by explicit LLM-produced code (not just LLM “verdicts”) mitigates the impact of LLM hallucinations and provides concrete auditability.
Limitations and Future Directions
- False Positive Rate: Current LLMs occasionally over-predict assertion invalidity. Advanced multi-turn prompting, verification via static analysis, or committee-validation among multiple LLMs could further filter spurious “FAILED” labels.
- Feedback and Iteration: Only a single inference-augmentation iteration is explored. Iterative synthesis to a fixed point, along with contract shrinking/generalization, warrants deeper investigation.
- Specification Expressiveness: The maximum achievable recall/expressiveness remains bound by SpecFuzzer’s grammar/template language. Integrating LLMs for assertion synthesis as well as falsification could further increase the coverage of real-world program invariants.
- Generalization to Large, Multi-language Systems: Scaling this pipeline to industrial repositories, or languages other than Java, will require further engineering and LLM context adaptation.
Conclusion
The hybrid architecture described in "Improving Dynamic Specification Inference with LLM-Generated Counterexamples" (2604.10761) constitutes a robust method for enhancing precision in dynamic contract inference pipelines. The design effectively harnesses LLM reasoning and synthesis in a tightly-integrated, auditably “falsification-oriented” loop that retains the reliability guarantees of code-level test execution. The resultant system improves the cost-effectiveness of dynamic assertion mining, setting a new baseline for semi-automated specification engineering. The work provides a practical blueprint for next-generation program analysis tools that actively use AI both for discovering specification candidates and for “breaking” them—blurring the traditional line between dynamic testing and specification mining.

