- The paper presents a novel Incremental Transformer (INCRT) that adaptively adds or removes attention heads using an online residual energy measure.
- The methodology employs a geometric criterion and bidirectional PCA+MCA gates to ensure the architecture remains both minimal and sufficient for the target task.
- Empirical results on tasks such as SARS-CoV-2 classification and SST-2 sentiment analysis demonstrate parameter efficiency and robust performance matching theoretical predictions.
Transformer architectures have, since their inception, relied on architecture-level hyperparameters (e.g., number of attention heads, layer depth) decoupled from the intrinsic structure of the downstream task. Empirically, this induces substantial redundancy, with previous analyses showing that from 50% to 80% of attention heads can be pruned from large models without significant degradation in task performance. The absence of a rigorous principle for capacity allocation forces practitioners to over-provision models and subsequently prune, with no guarantee of architectural sufficiency.
This work introduces the Incremental Transformer (INCRT), a framework for constructing Transformer architectures whose structure is determined online, through a geometric criterion that directly reflects task-induced directional complexity. Rather than growing a model to a predetermined scale, INCRT starts from a single head and adds or removes attention heads adaptively via a scalar online-computable measure of residual directional energy, thus achieving provable minimality and sufficiency without separate validation or post-hoc hyperparameter tuning.
Theoretical Framework
Central to INCRT is the bifurcation of the attention mechanism into symmetric and antisymmetric components. The antisymmetric part, Ma, encodes the directed flow of information, residing in the Lie algebra so(d). Task requirements are quantified through the residual operator:
Ares=P⊥sym(XTXMa)P⊥,
where X is the token embedding matrix and P⊥ projects out directions already captured by existing heads. The largest eigenvalue of Ares, λmax, quantifies the maximal uncaptured task energy; heads are iteratively added in the direction of v1(Ares) whenever λmax exceeds a preset threshold θ.
Growth and pruning decisions are provably homeostatic. Every addition of a head strictly reduces the global Lyapunov functional so(d)0, while pruning cannot increase it beyond a controlled margin. The architecture halts further modification when residual energy is below the sufficiency threshold for all heads and no component is redundant, yielding a simultaneously minimal and sufficient configuration.
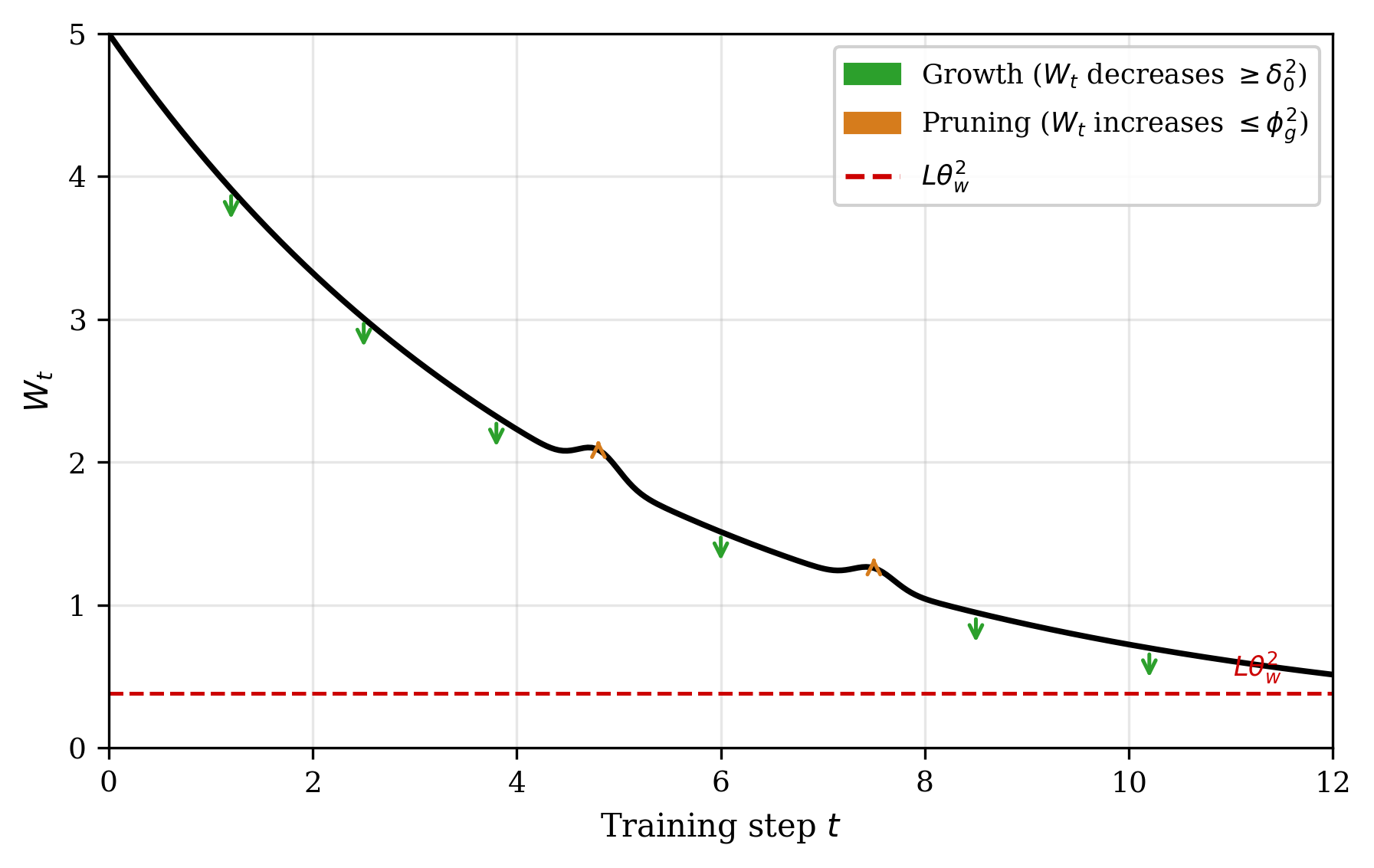
Figure 1: Lyapunov functional so(d)1 exhibits monotonic decay, guaranteeing finite-step convergence and minimality.
Theoretical results include a compressed-sensing-type upper bound stating that the required number of heads, so(d)2, scales as:
so(d)3
where so(d)4 encodes the directional complexity of the task and so(d)5 the initial residual energy. This establishes a direct, measurable relationship between data geometry and model capacity, in contrast to conventional scaling laws.
Architectural Mechanisms
The implementation hinges on the PCA+MCA bidirectional gate, which simultaneously tracks the leading and minor eigenvectors of so(d)6 via Oja’s rule and the MCA EXIN algorithm, endowed with almost sure convergence guarantees. This enables symmetric orthogonal deflation, maximizing coverage of the uncaptured energy subspace at each growth event.
Three nested levels of architectural adaptation are supported: (1) width (number of heads per layer), (2) head eigenspace dimension, and (3) network depth. Growth triggers are derived from directional energy thresholds, while pruning is activated if a head’s aligned energy remains below a secondary threshold for a specified number of steps. Crucially, new heads are initialized along dominant-motor directions, with their effect on model output bounded so as to ensure knowledge preservation during structural transitions.
Empirical Results
Validation is performed on SARS-CoV-2 variant classification (synthetic and real GISAID dataset) and SST-2 sentiment analysis. On the synthetic CoV-2 task, the predicted and observed head count coincide (so(d)7), with final accuracy of 99.47% using seven times fewer parameters than BERT-base, surpassing the latter’s accuracy even when trained from scratch and without pre-training.
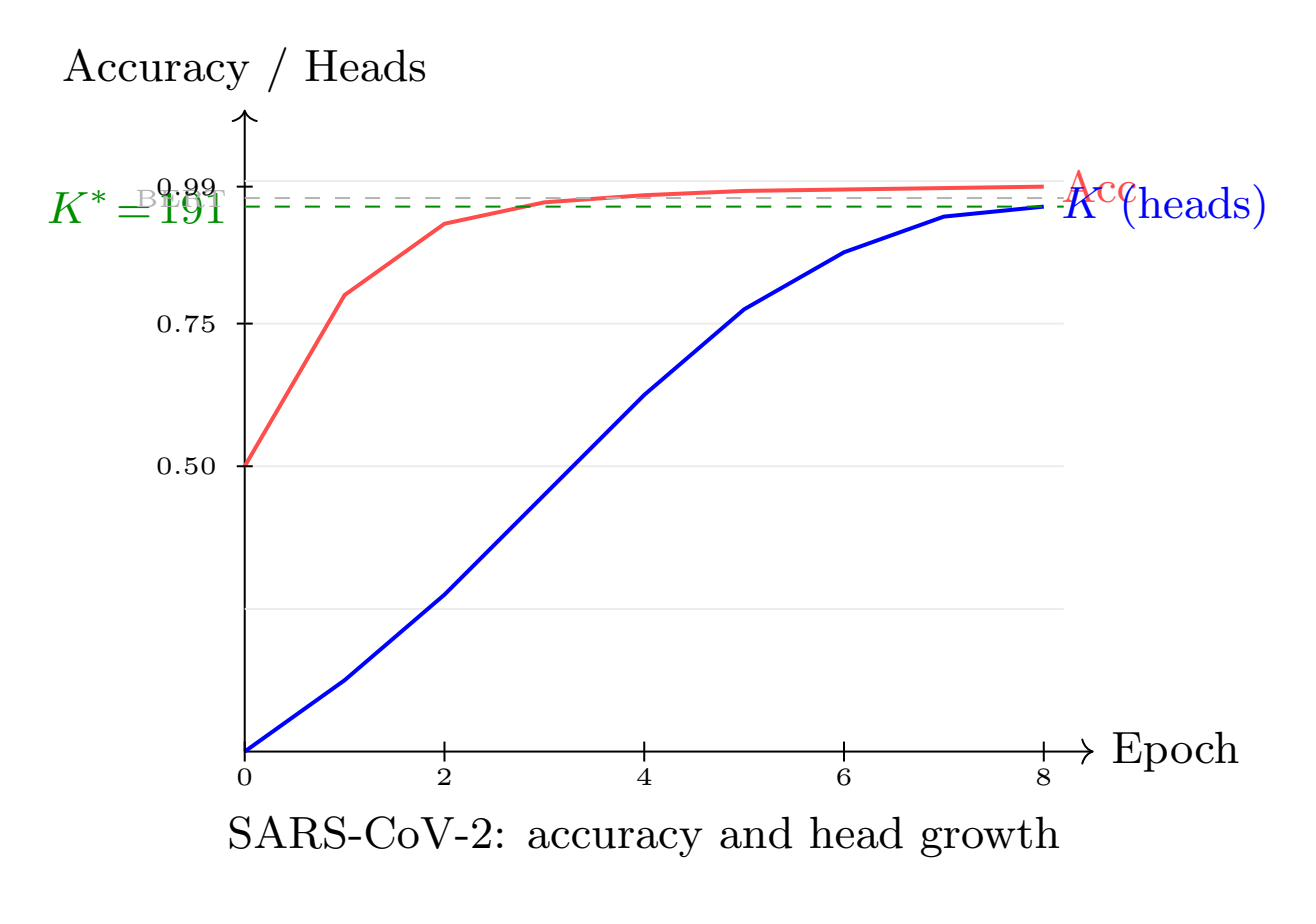
Figure 2: Validation accuracy and head count plateau synchronously, demonstrating tightly coupled stopping of both training and architectural growth via the geometric criterion.
Decay of the residual energy follows the compressed-sensing prediction tightly, confirming the law’s applicability beyond the asymptotic regime.
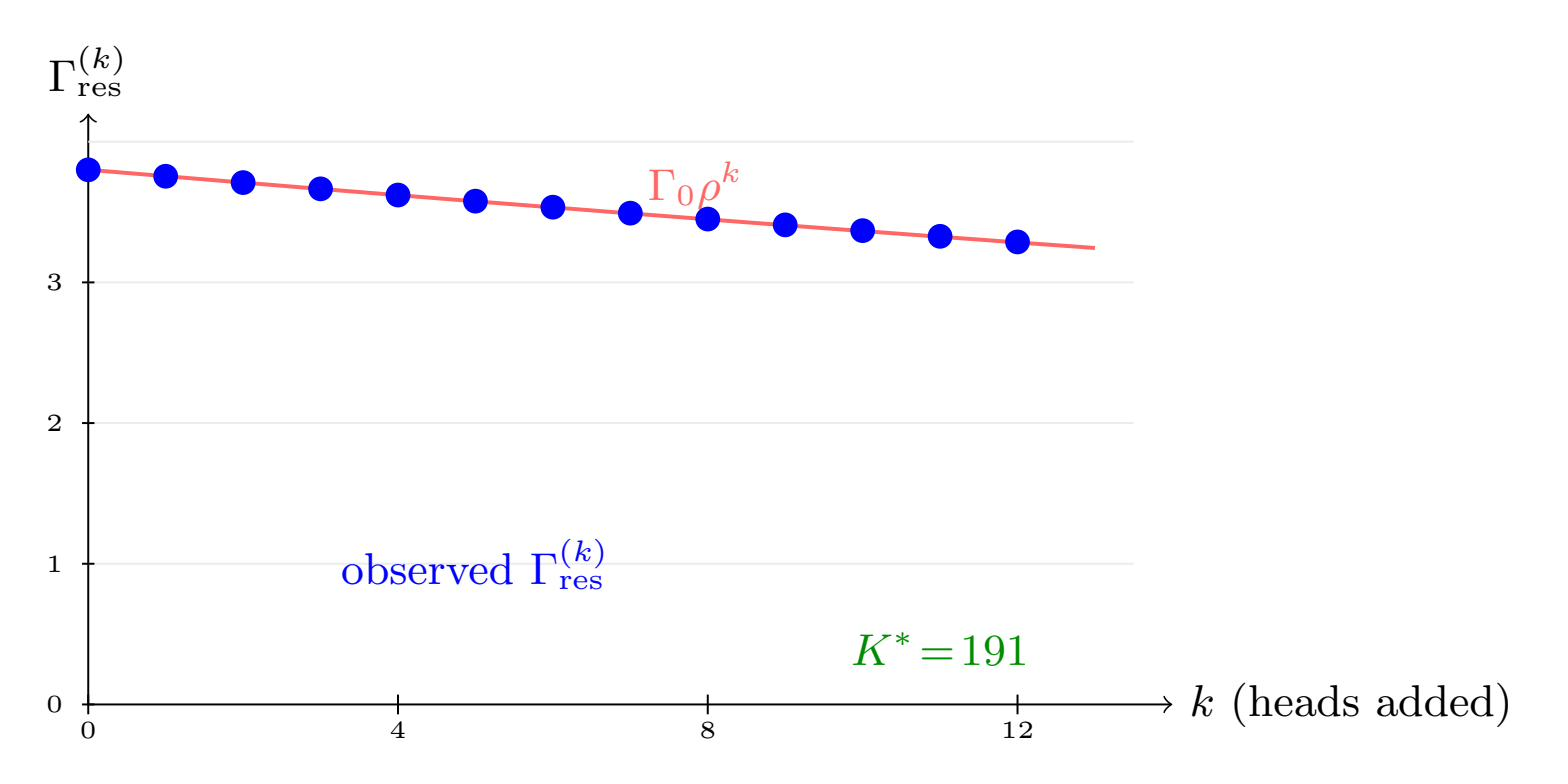
Figure 3: Residual energy so(d)8 decays geometrically in accordance with theoretical bounds derived from task spectral structure.
On the real GISAID dataset, both the bidirectional (BD) and PCA-only gates terminate at the predicted head count, achieving 99.84–99.94% classification accuracy, and match or exceed BERT-base performance with 3.7× parameter efficiency.
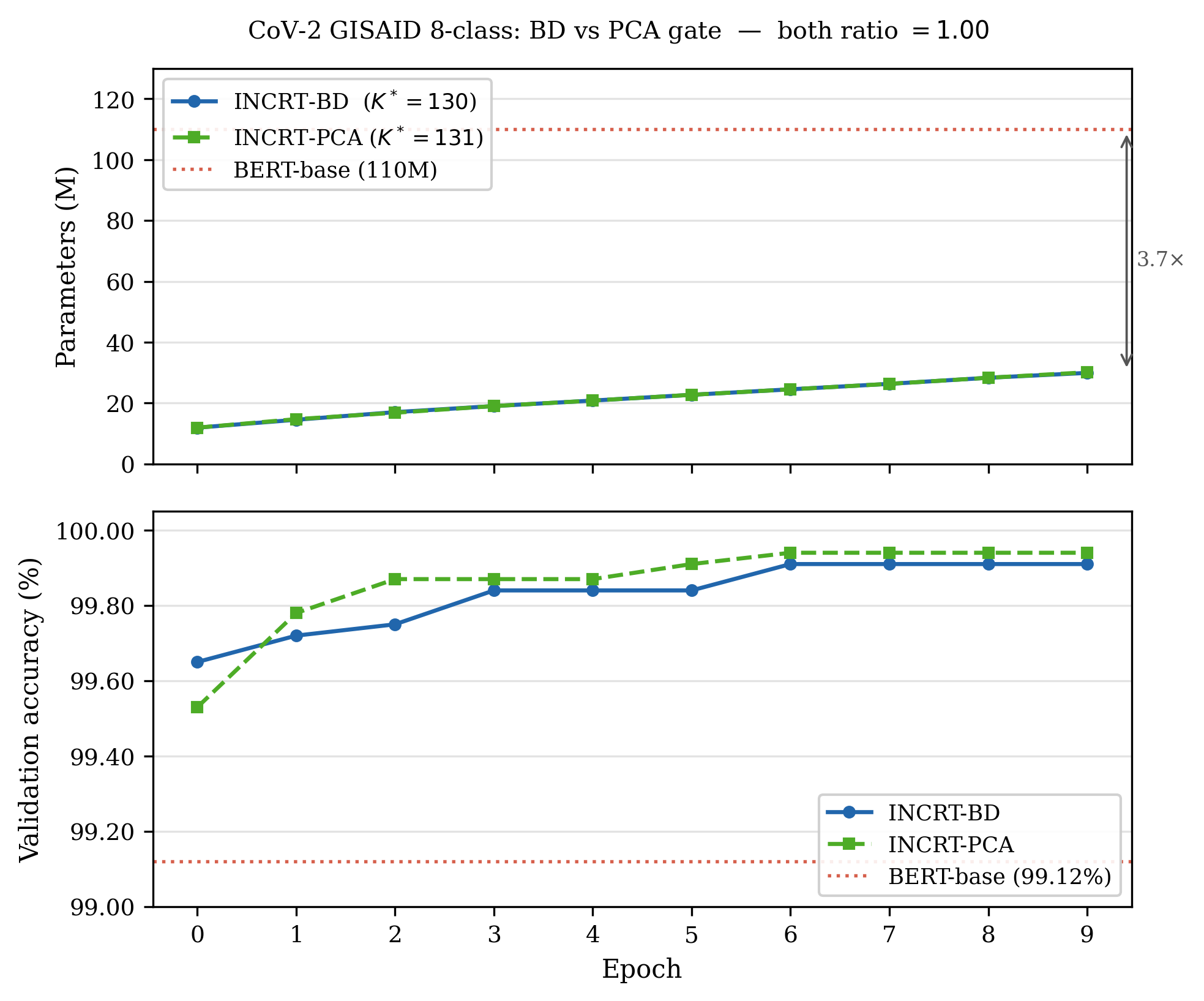
Figure 4: Comparison of parameters and accuracy for INCRT versus BERT-base across training epochs on the CoV-2 real GISAID dataset.
The SST-2 sentiment task, lacking localized directional signals, still conforms to the head-count law within 11%, and the observed offset is quantitatively predicted by the theoretical so(d)9-approximation overhead in the incremental gate.
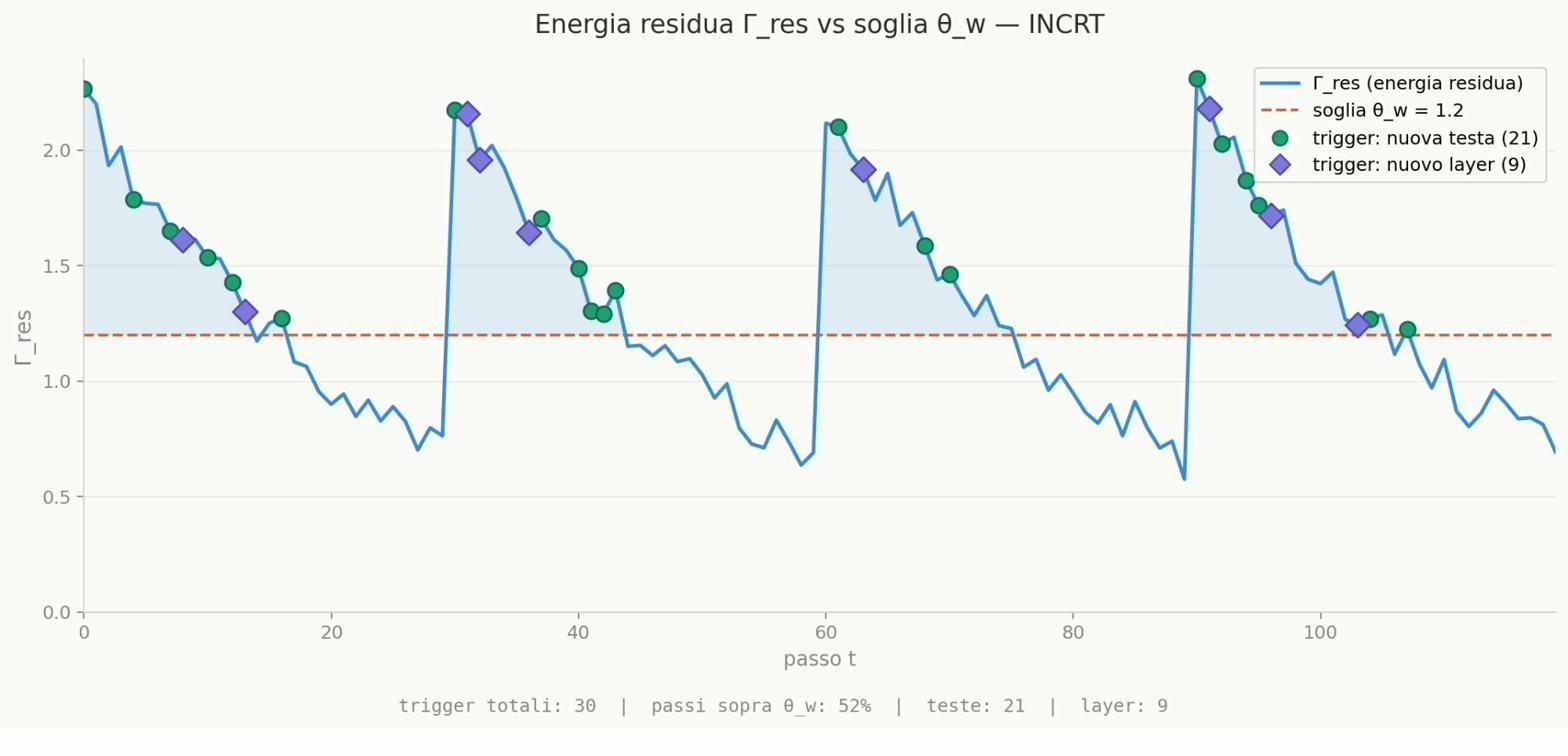
Figure 5: Residual energy on SST-2 converges robustly to the growth threshold, highlighting the method’s applicability to complex, heterogeneous tasks.
An ablation study in a synthetic nonstationary setting demonstrates automatic pruning and regrowth: upon a sudden shift in the task operator, obsolete heads are retired and new heads are allocated, validating true architectural plasticity in online learning.
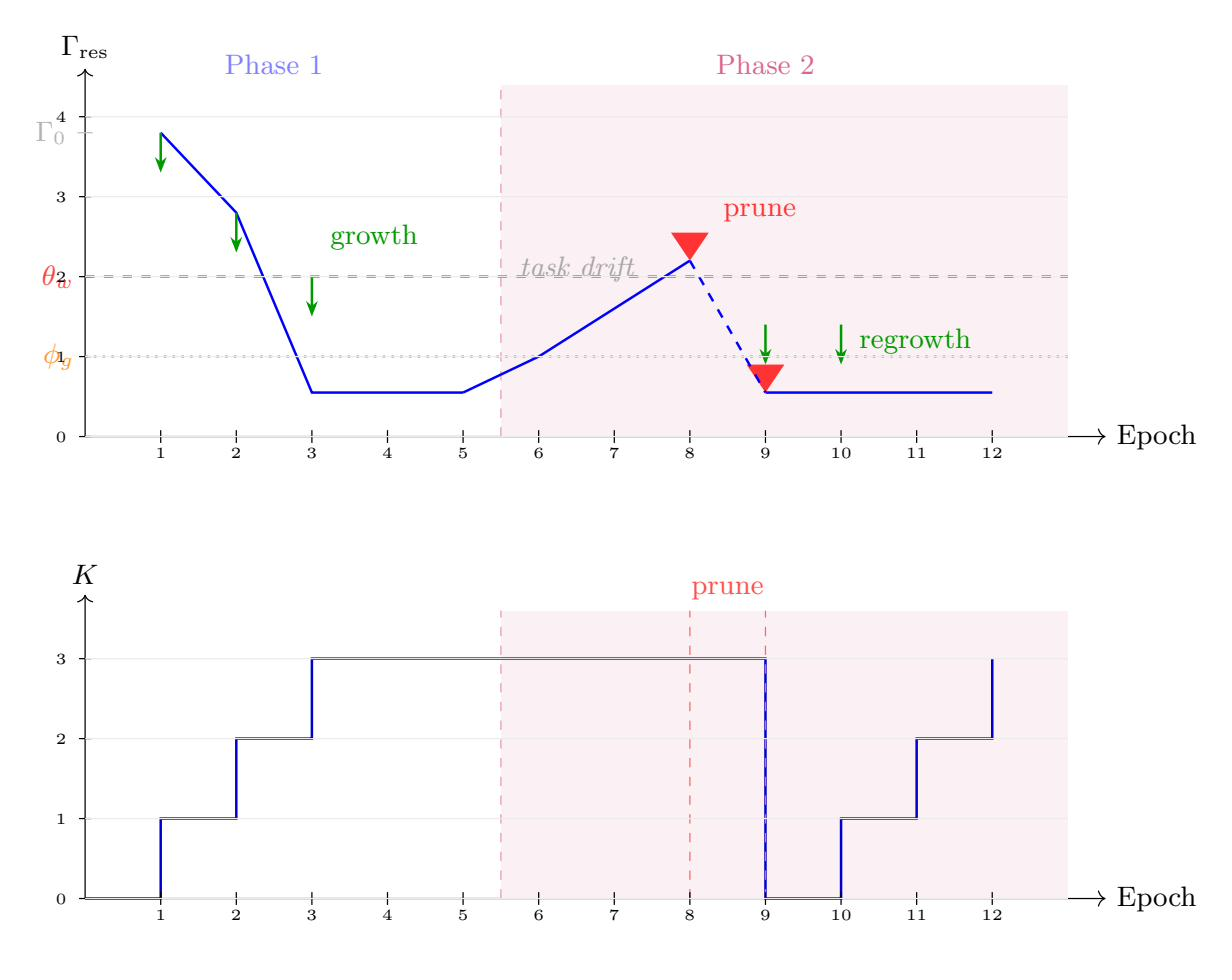
Figure 6: Head count and residual energy trajectories on a synthetic nonstationary task where a shift in the operator triggers pruning and regrowth.
Robust geometric decay of residuals is maintained even after distribution shift, confirming compressed-sensing bounds throughout both stationary and nonstationary phases.
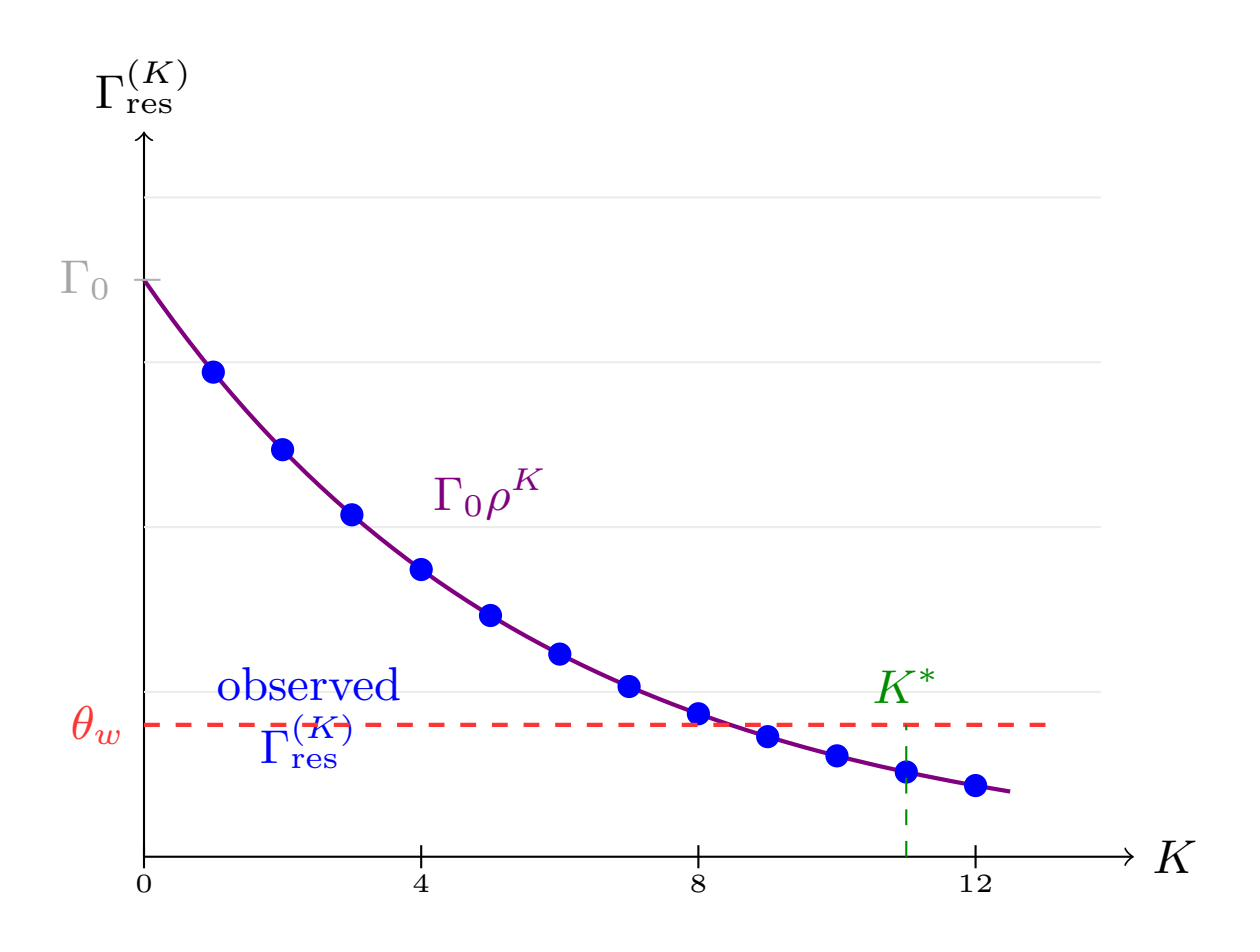
Figure 7: Geometric decay of Ares=P⊥sym(XTXMa)P⊥,0 (circles) in both phases matches the theoretical rate.
Practical and Theoretical Implications
The paper conclusively demonstrates that a geometric online criterion can yield Transformer architectures that are both minimal and sufficient with respect to a rigorously defined residual energy. Empirical matched counts between predicted and achieved architectures support the quantitative law. In practice, this refines the approach to model sizing on distribution-specific tasks, indicating that maximally efficient architectures typically have more heads and fewer layers than standard models, with head counts scaling predictably from measured task complexity rather than trial-and-error grid search.
The ability to adapt the architecture online, and to prune as well as grow, sets INCRT apart from both post-hoc pruning and progressive stacking methods, neither of which offer sufficiency guarantees or bidirectional control. The framework has direct implications for scaling transformer architectures to new modalities or rapidly shifting domains, such as real-time bioinformatics or non-stationary NLP environments.
Theoretically, INCRT introduces a connection between residual geometric structure and NTK alignment, bridging capacity growth, kernel methods, and compressed sensing. The geometric minimality criterion aligns precisely with the NTK-based convergence speed criterion for kernel regression, offering tight analytic control over the trade-off between model complexity and approximation error.
Limitations and Future Directions
This submission restricts validation to single-layer transformers. The extension to automatic depth growth remains to be evaluated at scale, though the theoretical mechanism is in place. The notion of sufficiency adopted is geometric rather than task-theoretic (Bayes optimality is not guaranteed by directional sufficiency alone); formal connections between geometric sufficiency and generalization remain an open direction. Robustness of the NTK alignment under large parameter updates is empirically observed, but in adversarial or multimodal settings additional correction mechanisms may be required.
A further promising direction is the integration with explicit geometric pretraining objectives targeting the antisymmetric component, which standard MLM-based objectives largely neglect.
Conclusion
INCRT presents a paradigm for self-structuring transformers, establishing that online geometric criteria can provide capacities that are both minimal and sufficient for a target task. The method is validated by strong correspondence between theoretical predictions and observed architectures on tasks of varying complexity and domain. The bidirectional PCA+MCA gate and associated Lyapunov-style convergence proofs provide a rigorous foundation. The work delineates a path beyond search-based architecture tuning, toward measurable, adaptive mechanisms reflecting true problem complexity (2604.10703).