- The paper presents a novel GPU-based subgraph matching model with fine-grained task decomposition that reduces memory overhead and minimizes idle threads.
- It employs warp-level batch scheduling to dynamically distribute candidate validation tasks, achieving up to 36× speedup over traditional methods.
- Empirical results demonstrate high scalability and robust performance across both small and large query workloads on massive graphs.
Fine-Grained, Hardware-Efficient Subgraph Matching on GPUs with gMatch
Introduction and Motivation
Subgraph matching underpins critical applications in graph analytics, such as social network analysis, fraud detection, and bioinformatics. The problem, which seeks all isomorphic mappings of a query graph Q within a data graph G, is computationally demanding—particularly when large queries or massive power-law graphs are involved. Existing GPU-based subgraph matching algorithms mainly rely on coarse-grained parallel models, mapping each partial match to a single warp and leveraging either BFS or DFS search strategies. However, these approaches exhibit inherent limitations on real-world, skewed graphs: they incur high per-warp stack memory overhead (scaling with O(∣V(Q)∣×dmax)) and suffer from pervasive thread underutilization (due to the discrepancy between dynamic candidate set sizes and the warp width). These deficiencies fundamentally restrict both the computational and memory scalability of GPU-based matching methods.
The paper "gMatch: Fine-Grained and Hardware-Efficient Subgraph Matching on GPUs" (2604.10601) introduces a fundamentally different parallelization strategy with the gMatch framework. At its core, gMatch adopts a fine-grained execution model, decomposing extension tasks at the per-candidate level and distributing them across individual threads. Combined with warp-level batch task scheduling, this approach optimally exploits GPU parallelism and memory resources—addressing the core bottlenecks in prior methods.
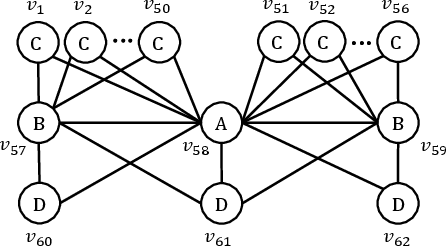
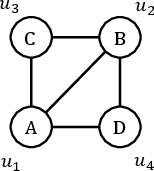
Figure 1: Example query graph and data graph Q (left) and G (right) illustrating the fundamental subgraph matching task.
Limitations of Coarse-Grained Execution Models
Traditional GPU-based methods (e.g., STMatch, T-DFS, EGSM) assign all partial match expansion for a single query path to a warp and use intra-warp SIMD operations for set intersection during extension. The execution stack for each warp must thus buffer potentially massive candidate lists at every depth of the search, which, on power-law graphs (with large dmax), rapidly exhausts available device memory and constrains parallelism to a limited number of warps.
Moreover, GPU SIMT execution mandates that all threads in a warp advance in lock-step, yet the size of candidate sets varies dramatically (often ≪32 in filtered workloads), resulting in frequent idle threads and low compute utilization. Although techniques like loop unrolling partially mitigate this, they do so at the expense of further increasing per-warp stack memory and fail to adapt to dynamic candidate set sizes.
This paradigm’s limitations are illustrated by frequent out-of-memory failures even for moderate queries on real datasets and persistent underutilization of available computational resources.
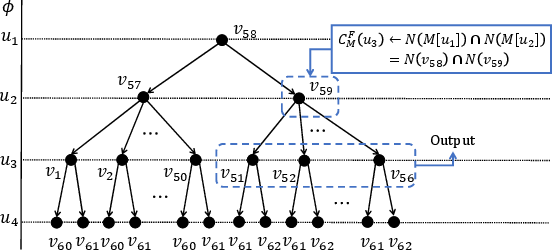
Figure 2: Search tree visualization for classic coarse-grained GPU-based parallel execution models, highlighting DFS/BFS search and stack space consumption.
Design and Execution Strategy of gMatch
Fine-Grained Parallel Execution
gMatch reconceptualizes the basic unit of work from a single partial match to an atomic candidate validation task: checking if a query vertex can be extended to a given candidate in the current data graph context. Each thread is responsible for one such task. By doing so, stack memory now scales with O(∣V(Q)∣) per warp (the recursion depth), entirely eliminating the dmax multiplicative factor.
Crucially, this decomposition enables flexible allocation of extension tasks: a single warp can process tasks from multiple partial matches, and any leftover tasks from prior expansions can be dynamically scheduled with zero synchronization overhead. This is particularly advantageous in the presence of small or irregular candidate sets after filtering.
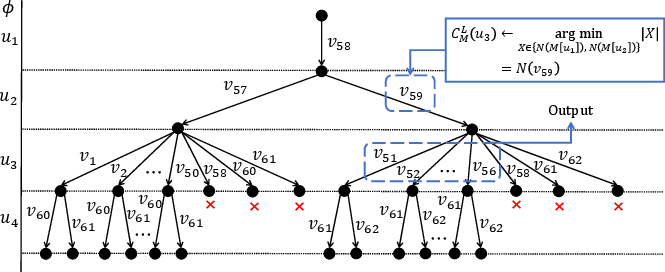
Figure 4: Search tree induced by fine-grained parallel execution, showing decomposition of match expansion to the per-candidate/thread level.
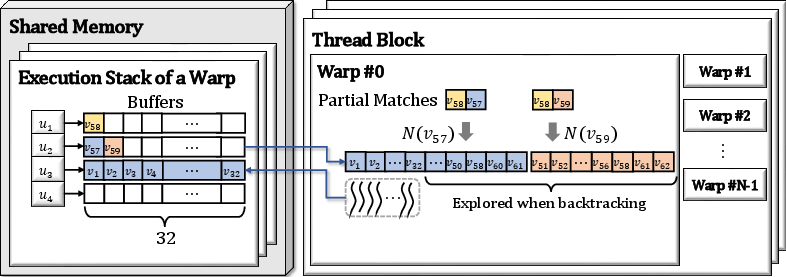
Figure 6: Fine-grained batch scheduling across partial matches within a warp. Blue and red denote disjoint partial match subtrees.
Warp-Level Batch Exploration
To further enhance utilization and minimize synchronization, gMatch introduces a warp-level batch scheduler. Task groups—collections of candidate checks from different partial matches—are collated into a shared pool per warp. Two shared pointers per warp are then used to efficiently orchestrate dynamic task fetching across all threads.
This design allows (1) multiple distinct partial matches of varying candidate multiplicities to be scheduled adaptively within the same warp, and (2) all computational capacity to be utilized regardless of the candidate set distribution.
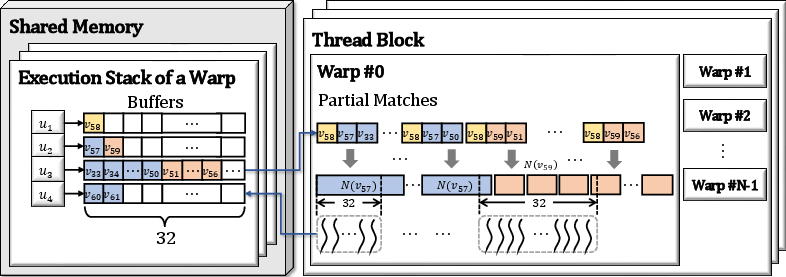
Figure 3: Warp-level batch exploration, where multiple candidate checks for multiple partial matches are processed in a single warp cycle.
Lightweight Load Balancing
To avoid the bootstrap underutilization problem, gMatch implements an initialization phase based on a brief BFS exploration (until pool size τ is reached, e.g., G0 matches). This yields a large, well-balanced task pool that ensures warps remain busy with minimal need for subsequent work stealing. If load imbalance emerges at runtime, gMatch uses simple intra-block (shared memory) and inter-block (global memory) queues for cheap, decentralized work-stealing—however, due to the ample initial pool size and the embarrassingly parallel nature of the problem, work-stealing is rarely triggered, and scheduling overhead is negligible.
Implementation and Complexity Analysis
A key advantage of the gMatch stack design is that per-warp stack size is independent of G1 and trivially fits in shared memory (few KB per warp). For load balancing, all synchronization structures are small and operate at warp or thread-block granularity.
From a time complexity perspective, per-candidate checks perform (per-thread) the usual adjacency, label, and uniqueness validation steps, fused into a single scan of the stack. Total search space remains unchanged relative to DFS/BFS models, but improved hardware efficiency arises from vastly superior thread utilization: average idle rates across tested datasets fall from 15–70% (coarse-grained) to 1–4% with gMatch.
Empirical Results
gMatch is empirically benchmarked against T-DFS, STMatch, EGSM, BEEP, and GG2Miner on a range of real and synthetic network datasets, scaling to graphs with over G3 edges. For small queries (≤5 vertices) on multi-million-edge graphs, only gMatch completes all test cases without OOM/OOT failures; competitors fail on power-law graphs or at large G4 (see Table 1 in the paper).
For larger queries (e.g., 12 vertices), gMatch outperforms EGSM by 20–36G5 average speedup due to higher warp efficiency. In memory consumption (execution stack), gMatch enables all queries to be performed with stack buffers resident in shared memory, while STMatch/T-DFS encounter OOM events at or below the mid-scale (see Table and Figure 8 in the paper).
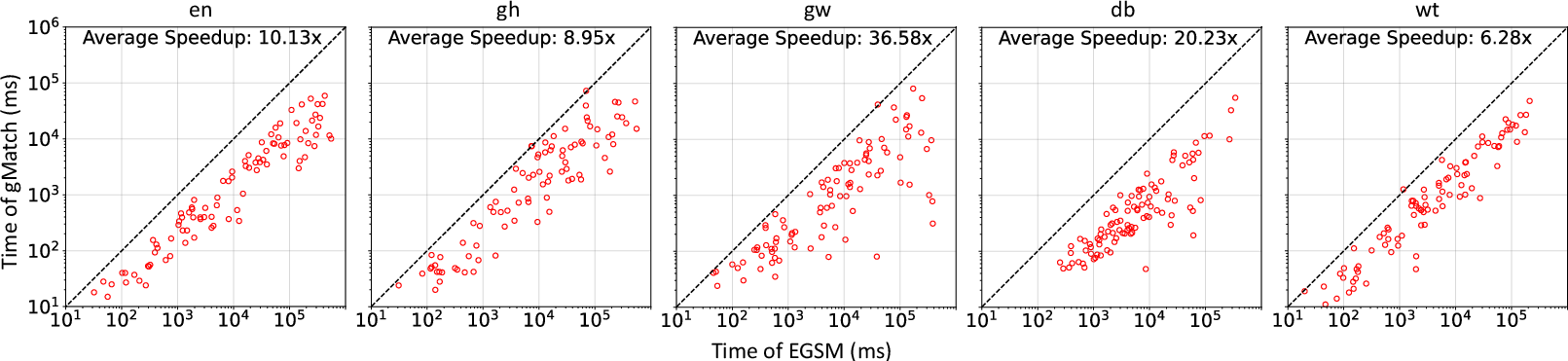
Figure 5: Comparative search time (milliseconds) between EGSM and gMatch across benchmark datasets (lower is better).
Ablation and Utilization Studies
Ablation experiments confirm that neither loop unrolling (even at factor 8) nor coarser task grain sizes match the achieved search time and GPU utilization of the fine-grained model with batch scheduling.
(Table in the paper)
For all tested datasets, the fine-grained model with batch exploration is the only configuration solving all queries without OOM. Idle rate is systematically reduced to less than 5%.
(Table in the paper)
Table: Warp idle rates across datasets under different models. gMatch universally achieves lowest idle rate.
Practical and Theoretical Implications
The gMatch framework establishes a new parallel execution paradigm for graph analytics workloads on GPUs, decoupling task unit granularity from hardware scheduling primitives. By leveraging fine-grained decomposition and inexpensive batch scheduling, it (a) eliminates the classic scaling bottleneck of per-warp stack allocation, (b) achieves near-ideal GPU thread utilization even under highly skewed or dynamic candidate sets common in real-world graphs, and (c) is robust across both small-query/large-graph and large-query/medium-graph workloads, adapting to workload heterogeneity without manual tuning.
Practical implications are immediate for industrial-scale graph mining pipelines, enabling in-memory GPU-based matching for datasets orders of magnitude larger than those tractable with previous state-of-the-art methods. The stack design and scheduling approach generalize to other recursive or search-based graph processing primitives (e.g., motif enumeration, clique listing), suggesting future research directions around unified, fine-grained GPU frameworks for graph intelligence workloads.
Conclusion
gMatch fundamentally redefines how subgraph matching should be parallelized on GPUs by introducing fine-grained tasks mapped directly to individual threads, coupled with a batch-aware warp scheduler and memory-efficient stack architecture. This paradigm shift achieves high scalability, dramatically reduced memory consumption, and superior hardware utilization across diverse workload regimes, outperforming prior GPU-based approaches by wide margins. The presented methodology has broad implications for the future design of large-scale, parallel graph analytics systems.

