- The paper introduces STORM, an end-to-end MLLM that seamlessly fuses referring grounding and multi-object tracking without relying on external detectors.
- It deploys a LLaVA-style architecture with a ViT encoder and a LLaMA-based language model to generate temporally consistent bounding boxes from natural language queries.
- By leveraging a novel task-composition learning paradigm and the comprehensive STORM-Bench dataset, STORM outperforms state-of-the-art methods with significant gains (e.g., +21.2 HOTA, +31.2 IDF1).
End-to-End Referring Multi-Object Tracking with STORM
Introduction
The task of Referring Multi-Object Tracking (RMOT) occupies a central position in vision-language research, demanding the coherent spatial–temporal association of all objects in a dynamic scene that match a free-form natural language query. The "STORM: End-to-End Referring Multi-Object Tracking in Videos" (2604.10527) introduces an end-to-end multimodal LLM (MLLM) named STORM, designed to unify referring grounding and tracking. STORM eliminates external detectors and trackers, directly mapping complex linguistic expressions to precise object localizations and identities maintained over video sequences. In addition, the paper presents a novel annotation pipeline and STORM-Bench, a comprehensive RMOT dataset with dense, diverse, and unambiguous referring expressions.
Methodology
Architecture
STORM adopts a LLaVA-style MLLM architecture, integrating a ViT-based vision encoder to generate spatial representations from each video frame. These are projected via an MLP into the textual embedding space of a LLaMA-based LLM. In the joint input space, video frames and textual queries are auto-regressively processed to produce temporally consistent, referent-conditioned bounding boxes in a structured plain-text format. This architecture directly optimizes for next-token prediction with cross-entropy loss, leveraging LLMs’ inherent reasoning and generation capabilities.
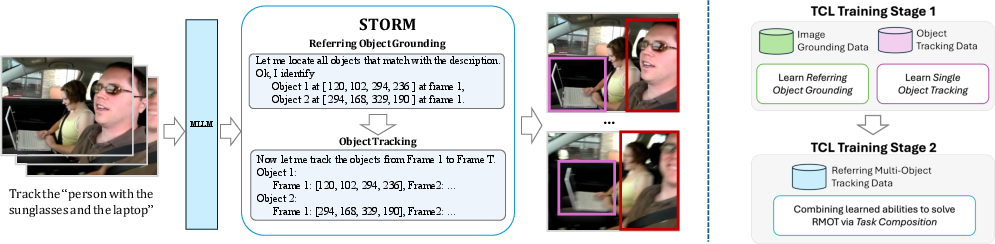
Figure 1: STORM framework: a LLaVA-style MLLM with task-composition learning to enable RMOT with limited annotated data.
Task-Composition Learning
Due to the annotation cost of RMOT datasets, the paper introduces a task-composition learning (TCL) procedure. TCL decomposes RMOT into three sub-tasks with abundant existing data: image grounding, single-object tracking (SOT), and referring single-object tracking (RSOT). STORM is initially pre-trained on large-scale image grounding and SOT corpora to acquire visual-linguistic grounding and temporal consistency, then fine-tuned with reasoning-based supervision (chain-of-thought) using the specialized STORM-Bench for RMOT.
This paradigm exploits the availability of data-rich domains and enables robust generalization to complex multi-object, relational, and ambiguous queries, as confirmed by extensive ablations in the paper.
Data Pipeline: STORM-Bench
The annotation pipeline for STORM-Bench is notably bottom-up. Object-centric captions are generated with an MLLM using enhanced visual prompts (e.g., framing object instances with colored boxes), followed by cross-view LLM verification to filter hallucinated or inconsistent captions. Multi-object referring expressions are then synthesized by textual LLMs to ensure attribute- and relation-rich, unambiguous language. The resulting benchmark provides 15K+ videos, 0.2M expressions, and 73.7K objects, with enhanced coverage of object types and linguistic phenomena, spanning a wide range of real-world activities and interactions.
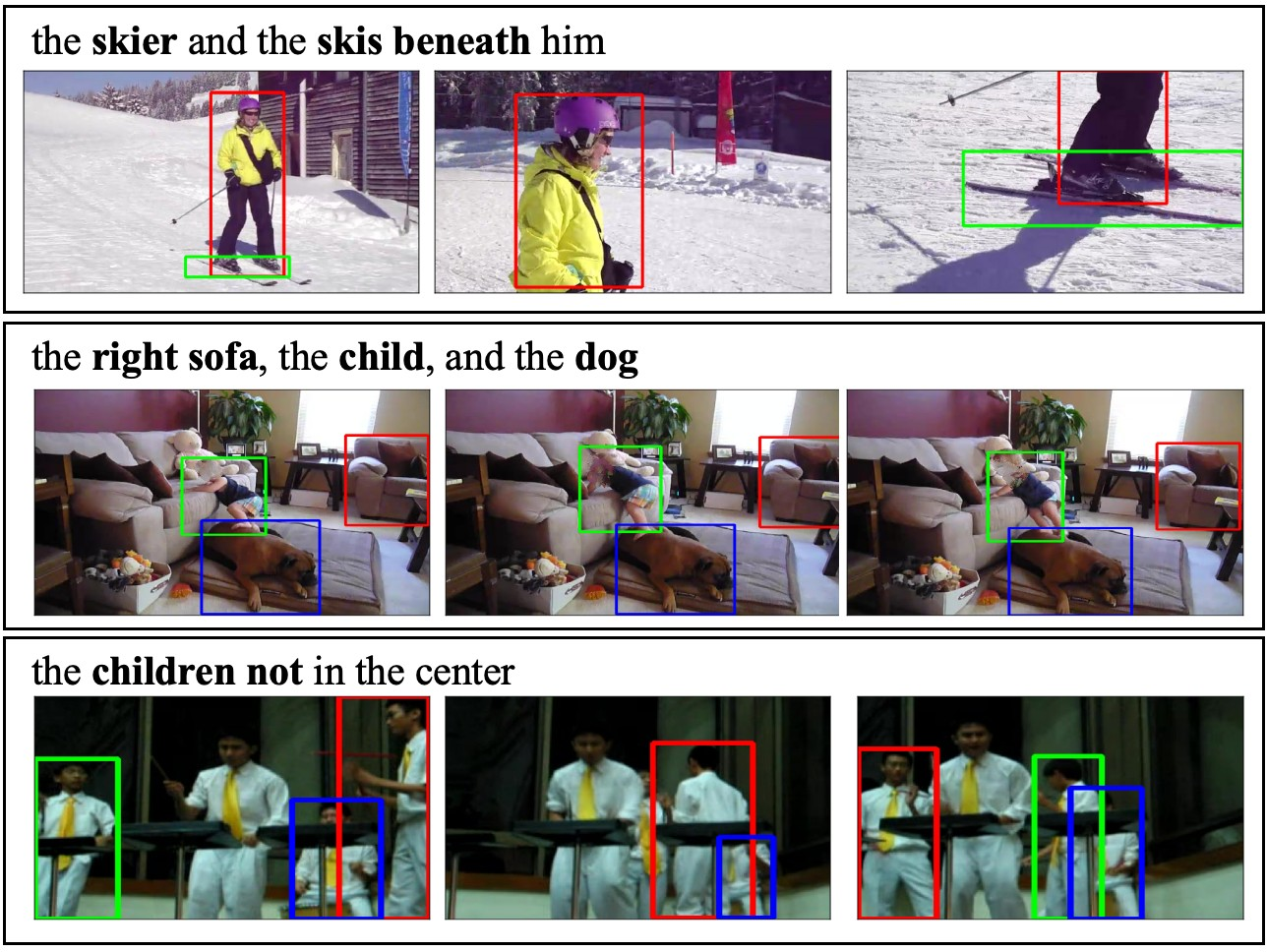
Figure 2: STORM-Bench samples: significant target scale variation, complex multi-object tracking under weak/strong expressions, and identity maintenance for similar object types.
Experiments and Results
The evaluation protocol spans image grounding (RefCOCO, RefCOCO+, RefCOCOg), RSOT (Elysium), and RMOT (STORM-Bench), using established metrics such as HOTA, IDF1, and MOTA.
Image Grounding: STORM achieves state-of-the-art performance on all splits of RefCOCO, RefCOCO+, and RefCOCOg, despite not being specifically fine-tuned for static images. This confirms effective transfer from RSOT and RMOT tuning.
Single-Object Tracking (RSOT): On Elysium, STORM is competitive with or surpasses specialized SOT/RSOT models such as Elysium, especially for long and compositional prompts. The architecture and TCL support strong knowledge transfer from grounding and SOT sub-tasks, evidently boosting performance with complex language.
Multi-Object Tracking (RMOT): On STORM-Bench, STORM substantially outperforms recent SOTA models such as Grounding DINO, Qwen2.5-VL, VisionLLMv2, and LaMOT by a large margin (e.g., +21.2 HOTA and +31.2 IDF1 over the best baseline), even using modest RMOT-specific data. Unlike image-based MLLMs, STORM demonstrates robust spatial-temporal association and identity preservation under complex relational or compositional prompts.

Figure 3: STORM’s qualitative performance: precise, consistent localization under referential queries involving attributes and relations.

Figure 4: Comparative tracking: STORM accurately localizes all referents per query, outperforming Qwen2.5-VL and VisionLLMv2 on complex RMOT cases.
Qualitative Insights
Further visualizations demonstrate that STORM successfully grounds and tracks referents through occlusion, camera motion, and when entities appear or disappear between frames, maintaining identity and spatial consistency in challenging, real-world scenarios.

Figure 5: Example: "the baby and the pink toy above it"—STORM accurately tracks spatial relations and maintains identity consistency.
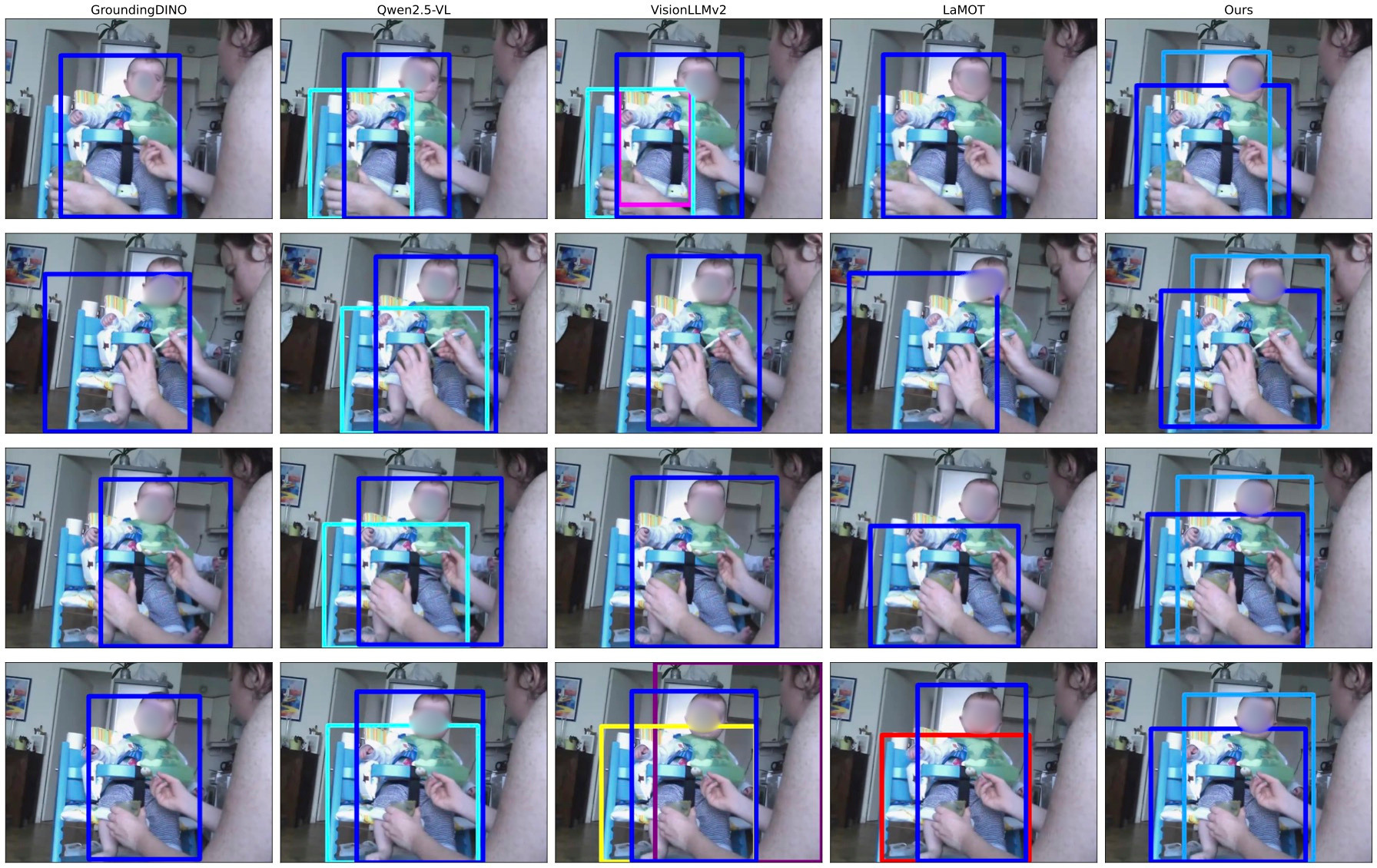
Figure 6: Example: "the baby and the blue high chair beneath the baby"—robust handling despite occlusion and partial visibility.

Figure 7: Example: "the cup next to the dish with fan-shaped meat arrangement"—STORM yields correct absence-of-object predictions when items leave the frame.
Dataset Analysis
STORM-Bench is shown to cover more object classes and support far longer, attribute- and relation-embedded expressions than prior datasets such as LaMOT, Elysium, and Refer-KITTI-V2. Visualizations (see word cloud and class distribution) confirm both linguistic and visual diversity, addressing annotation ambiguity and bias found in competing resources.
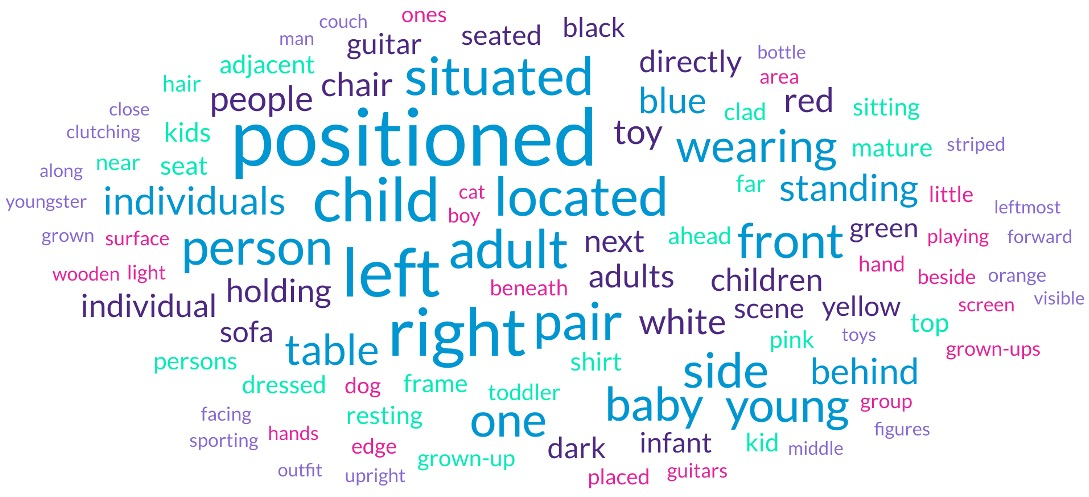
Figure 8: Word cloud: expressions in STORM-Bench frequently reference spatial relation, color, age, and co-occurrence.
Figure 9: Distribution: STORM-Bench includes diverse categories—people, animals, furniture, food, and electronics.
Implications and Future Directions
STORM demonstrates that an end-to-end, LLM-centered framework can effectively unify referring grounding and multi-object tracking tasks without reliance on hand-crafted cue integration, external detectors, or explicit data augmentation. This approach offers a scalable path for vision-language systems to handle complex and context-sensitive queries in dynamic environments.
On the practical side, such models hold strong promise for deployment in video analytics, real-world assistive or surveillance applications, and embodied perception, where spatial–temporal reasoning and natural-language control are demanded over arbitrary, open-vocabulary objects.
Future work should explore further architectural optimizations to cope with extended video lengths, increased referent counts, and crowded or heavily occluded scenes. Further efficiency enhancements are required for real-time application scaling, as inference costs currently scale linearly with object count due to auto-regressive decoding. Additionally, improved strategies for dense annotation in high-ambiguity video frames and iterative refinement of multi-object expressions would contribute to even higher robustness and interpretability.
Conclusion
STORM establishes a new state-of-the-art in referring multi-object tracking, validating both its fully end-to-end MLLM-based design and its data-efficient TCL paradigm using high-quality, large-scale STORM-Bench supervision. These results confirm that combining strong LLMs with compositional learning strategies and rich annotation pipelines delivers robust, generalizable reasoning and tracking in complex vision–language domains.

