- The paper presents ReFEree, a framework that decomposes code summaries into segments and uses dependency-aware analysis to detect factual inconsistencies.
- It introduces a taxonomy of four error types and achieves over 92% accuracy in identifying segment-level inconsistencies in both Python and Java code.
- Empirical results demonstrate that ReFEree outperforms baseline methods, enhancing the reliability of automated code documentation workflows.
Reference-Free and Fine-Grained Evaluation of Factual Consistency in Code Summarization: The ReFEree Framework
Motivation and Problem Statement
Factual consistency evaluation in LLM-based code summarization is critical for engineering reliability and trust in generated documentation. The increasing integration of LLMs like GPT-4, Claude-Code, and Copilot into software development workflows has enabled the automatic creation of lengthy and descriptive code summaries. However, current reference-based metrics (e.g., BLEU, ROUGE, METEOR) and coarse reference-free LLM-judge protocols are limited. They cannot accurately or explainably identify factual inconsistencies—especially those manifesting at sentence or segment granularity or involving code dependencies that span files or external APIs.
Existing LLM-judge and SOTA reference-free approaches typically provide only a single summary-level score, often failing to account for multi-criteria factual errors and external dependencies. As a result, they struggle to both localize specific inconsistencies and justify their assessments, leading to a performance gap relative to human expert judgment.

Figure 1: Existing methods fail to detect segment-level type errors in real-world code summaries, whereas ReFEree achieves alignment with human judgment via dependency-aware analysis.
The ReFEree Framework
ReFEree is a novel reference-free and fine-grained factual consistency evaluation framework specifically targeted for LLM-generated code summaries in real-world contexts. The system architecture is predicated on two major axes: (1) segment-level decomposition, with each sentence evaluated independently according to a defined taxonomy of inconsistency types; and (2) dependency-aware code context mining, which resolves the code’s actual functionality, including properties and behaviors defined in external files or APIs.
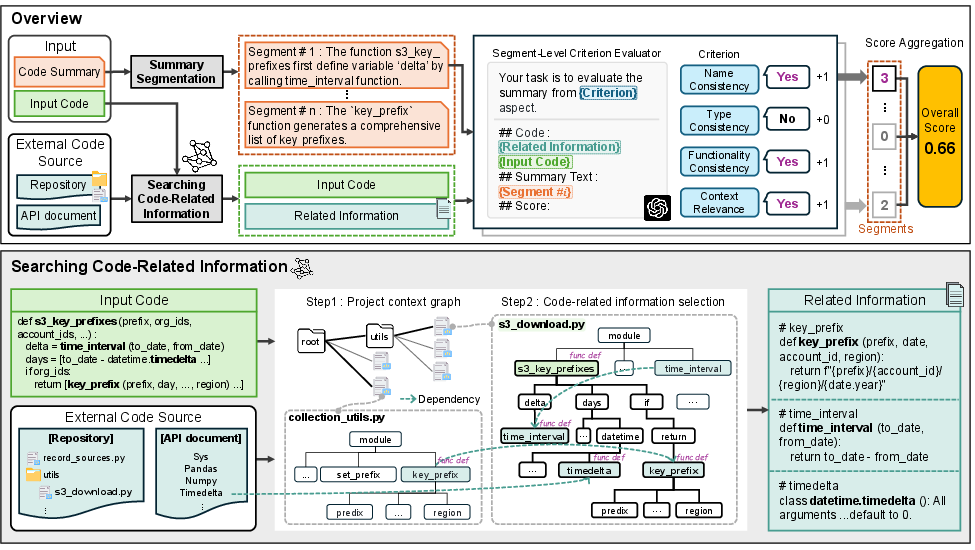
Figure 2: The ReFEree workflow involves information retrieval for dependency resolution, summary segmentation, LLM-based multi-criteria evaluation of each segment, and score aggregation.
ReFEree defines four atomic and empirically validated factual inconsistency criteria:
- Name Inconsistency (C1): Identifier mismatches.
- Type Inconsistency (C2): Return/value type mismatches.
- Functionality Inconsistency (C3): Erroneous description of implemented behavior, often due to dependency errors.
- Context Irrelevance (C4): Introduction of unverifiable or off-topic content.
The evaluation proceeds as follows:
- Context Resolution: Static analysis (AST traversal) constructs a project context graph, encompassing all code entities (functions, classes, variables) and their dependencies (including cross-file and external APIs via documentation lookup).
- Segment-Level Judgment: The code summary is tokenized into sentences. Each segment is processed by a prompt-driven LLM agent, which assigns binary (0/1) consistency judgments for each of the four criteria, using both the input code and the retrieved context.
- Score Aggregation: The overall factual consistency is computed via normalized aggregation, yielding a fine-grained, interpretable and criterion-aware metric in [0,1].
Empirical Evaluation
A new benchmark was constructed, comprising 2,055 code summaries (Python and Java) with gold human annotations at both segment and summary levels. The data contain intentionally factually inconsistent samples aligned to the four ReFEree inconsistency criteria, with high annotation reliability (Krippendorff’s α: summary-level 0.74, segment-level 0.84).
Baselines include eight classic reference-based and five reference-free methods, with strong attention to LLM-judge, G-Eval, and FactScore protocols.
ReFEree achieves highest correlation with human judgment across all tested metrics. For instance, summary-level Pearson/Spearman/Kendall correlations on Python code reach 0.497/0.489/0.390, which is approximately 15–18% superior to the best prior art (G-Eval), and up to 35% higher than FactScore on Java. Critically, ablation studies show that omitting code-related information or reducing the number of evaluative criteria significantly degrades performance.
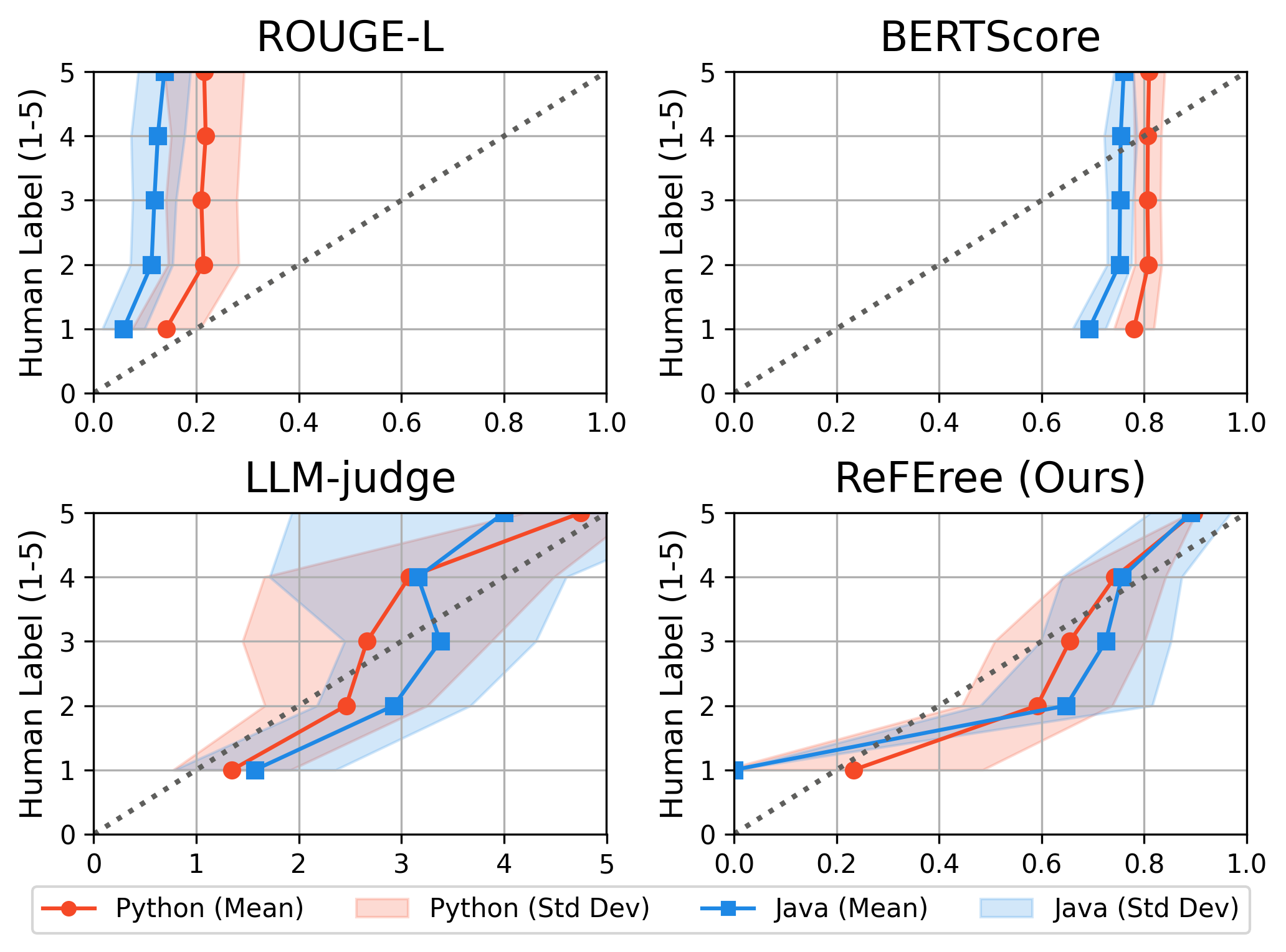
Figure 3: The correlation between evaluation scores and human labels for each method (Python and Java), showing ReFEree’s strong linear alignment and low variance compared to baselines.
Segment-level accuracy in identifying C1–C4 inconsistencies exceeds 92% for both languages. Notably, only ReFEree enables actionable, explainable error localization, in contrast to previously monolithic scoring approaches.
Generalizability and Stability
ReFEree’s architecture is agnostic to the underlying LLM used as judge. Evaluations with multiple LLMs (Llama3, Mistral, Qwen2, GPT-4o-mini, GPT-4.1-mini) confirm consistent outperformance over G-Eval and other benchmarks, despite variations in model quality.
The framework also displays higher stability than prior LLM-judge systems under both prompt perturbation and seed variation (inter-annotator agreement: up to 0.90).
Results further indicate that ReFEree maintains its performance across code summary lengths and developer-written docstrings, underlining its robustness and real-world applicability.
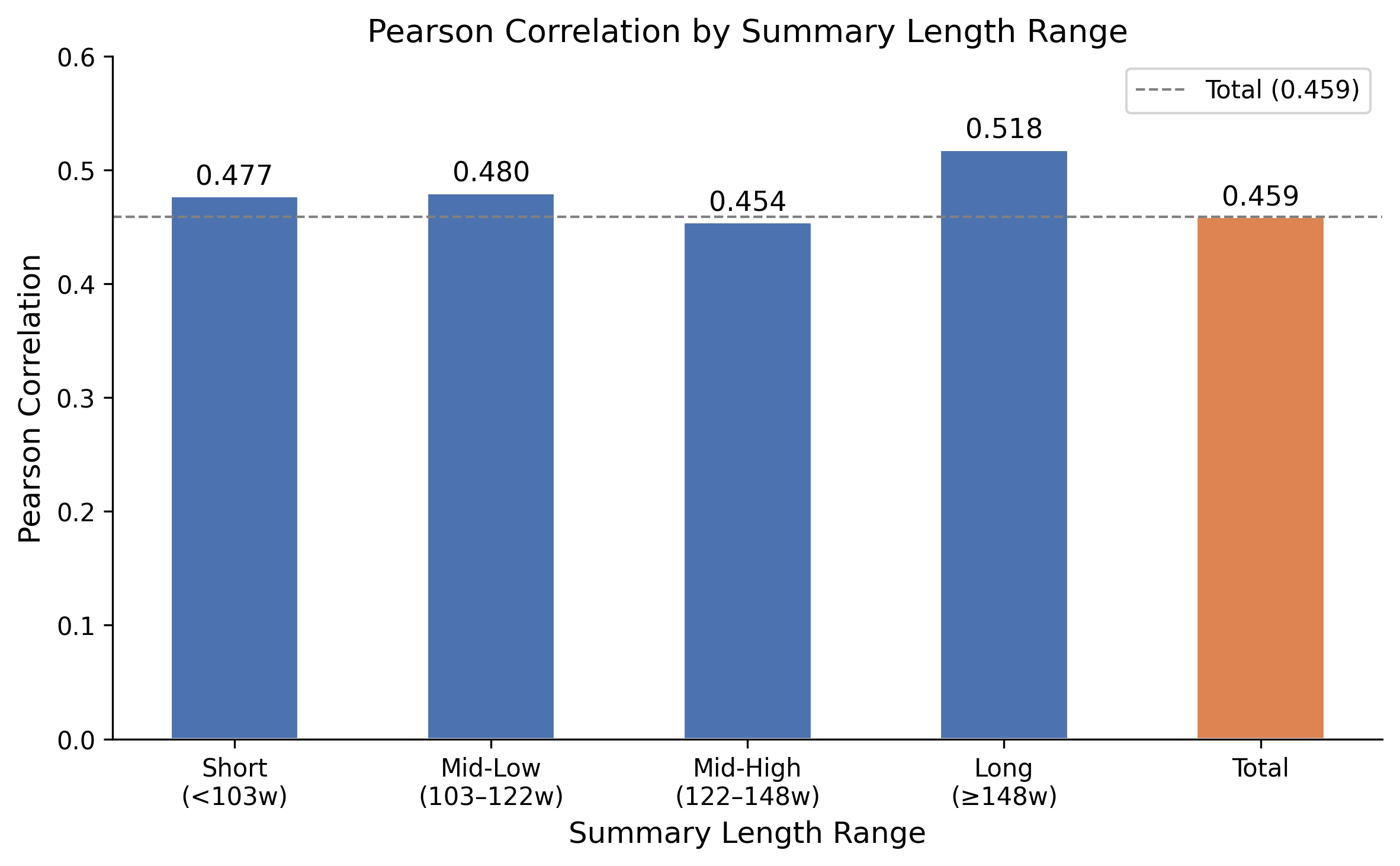
Figure 4: ReFEree’s score–label correlation remains stable across varying summary lengths.
Implications
Practical Implications
The adoption of ReFEree has direct application to CI/CD pipelines, documentation QA, and LLM code assistant deployments within industry-scale codebases. By delivering high granularity, dependency-aware factuality evaluation, it enables:
- Early detection of hallucinated or misleading LLM-generated docstrings before human review or deployment.
- Targeted feedback for fine-tuning LLMs, by pinpointing consistent error sources.
- Automated scoring in code documentation competitions or model benchmarks where references are unavailable or insufficient.
Theoretical and Methodological Impacts
The ReFEree framework advances factuality evaluation by:
- Proposing a multi-dimensional taxonomy for code summary consistency, grounded in empirical error analysis.
- Demonstrating the necessity of dependency-aware context mining for realistic code summarization tasks.
- Shifting the paradigm from monolithic, reference-based evaluation to reference-free, explainable, and fine-grained approaches.
The decomposable architecture also facilitates future research into explainable LLM evaluation, reliability analysis under diverse repository structures, and the extension of segment-level methods for summary completeness or quality.
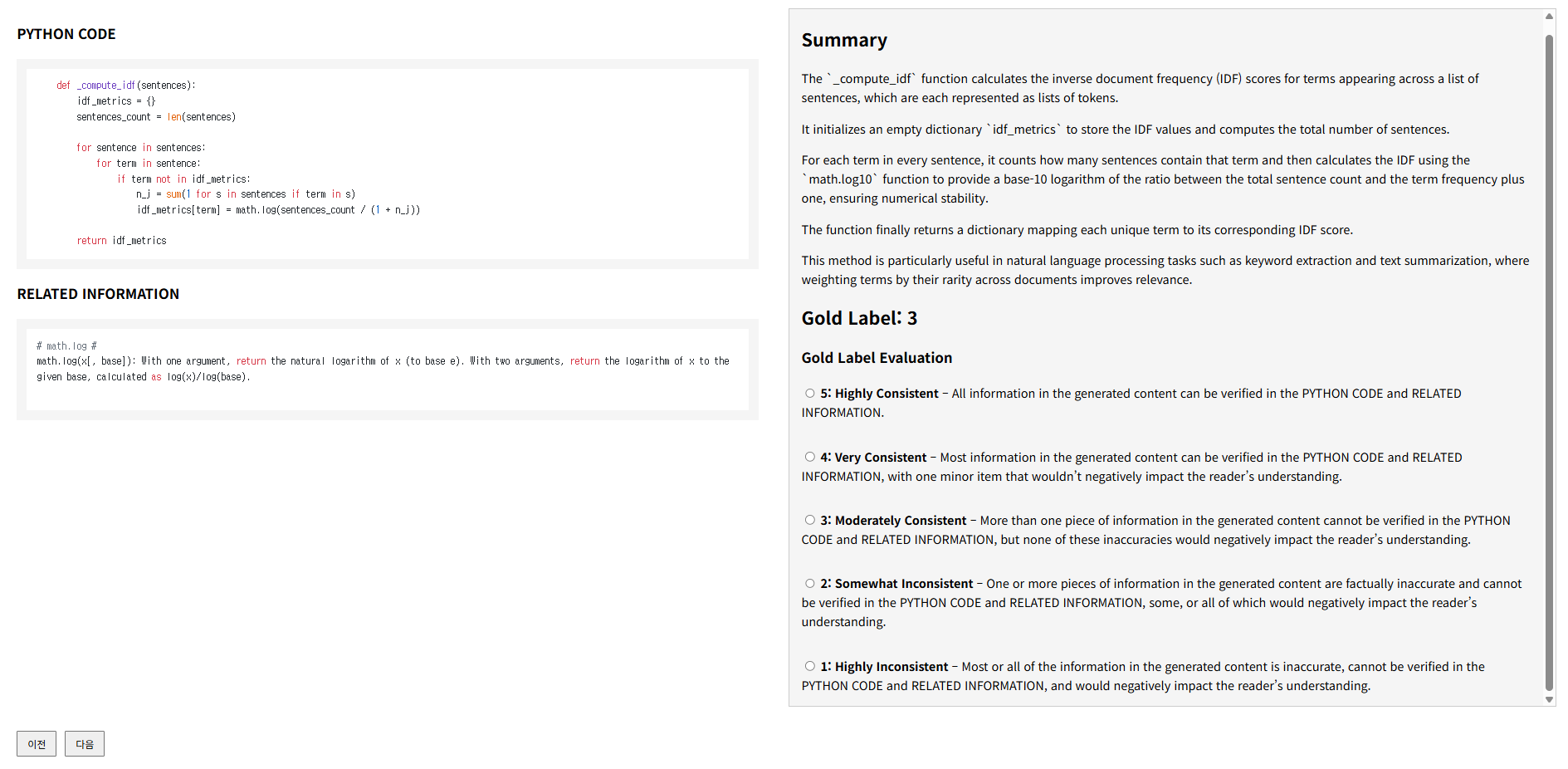
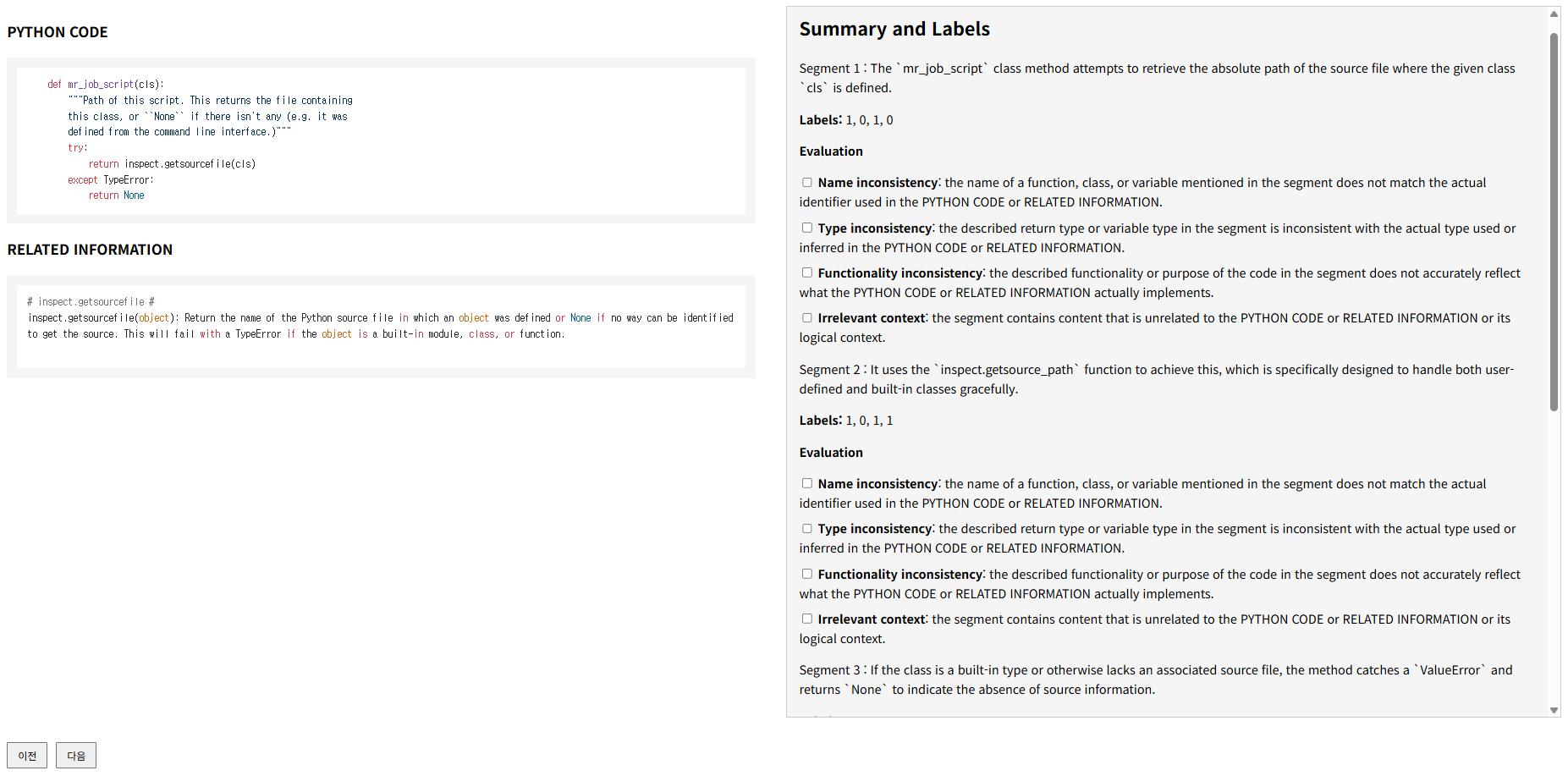
Figure 5: Summary-level human annotation interface developed for the benchmark resource.
Conclusion
ReFEree establishes a new state-of-the-art for reference-free, fine-grained factual consistency evaluation in code summarization. It aligns more closely with expert human judgment than all competitive baselines, generalizes across models and programming languages, and provides score interpretability and actionable diagnostic feedback. These capabilities position it as a critical tool for both researchers and practitioners seeking to advance reliable, trustworthy, and robust code documentation supported by LLMs.
Future Directions
Expanding ReFEree to handle summary completeness and nuanced qualitative aspects—beyond pure factuality—is a natural progression. There is also fertile ground to extend beyond static AST-based analysis to encompass complex dynamic code behaviors or support deeper multi-hop dependency reasoning. Finally, open challenges remain in extending such criteria-based, reference-free evaluation to non-summary code generation tasks and to other software engineering artifacts.

