- The paper introduces EIF-based DR- and R-learner estimators for conditional odds and risk ratios, ensuring robustness against nuisance misspecification.
- It demonstrates superior performance over traditional logistic and meta-learner approaches in high-complexity, high-dimensional settings with treatment effect heterogeneity.
- The empirical and theoretical analyses support reliable individualized treatment rules in observational data and provide practical guidance for estimator selection.
Orthogonal Machine Learning for Conditional Odds and Risk Ratios: An Expert Synthesis
Introduction
This work presents a comprehensive theoretical and empirical development of orthogonal machine learning estimators for conditional odds ratio (OR) and risk ratio (RR) parameters, expanding the domain of doubly robust (DR) and orthogonal statistical learning beyond the conditional average treatment effect (CATE/ATE). The methodology leverages efficient influence function (EIF) theory to construct estimators robust to nuisance parameter misspecification, and the empirical evaluation rigorously compares the novel approaches with both parametric (logistic regression) and nonparametric meta-learners (SuperLearner T/S-learners) under a spectrum of simulated treatment effect heterogeneity and data complexity. The implications bear directly on the construction of reliable individualized treatment rules in high-dimensional, confounded observational data.
Methodological Framework
Target Parameters and Nuisance Structure
The estimands of interest are the conditional ATE, OR, and RR, defined as:
- ATE(X)=P(Y=1∣T=1,X)−P(Y=1∣T=0,X),
- OR(X)=P(Y=1∣T=0,X)/(1−P(Y=1∣T=0,X))P(Y=1∣T=1,X)/(1−P(Y=1∣T=1,X)),
- RR(X)=P(Y=1∣T=0,X)P(Y=1∣T=1,X),
where X denotes covariates, T the binary treatment, and Y the binary outcome. The setting assumes full confounder adjustment and nonparametric identification.
Classical plug-in estimators (logistic regression, vanilla SuperLearner T/S-learners) estimate P(Y=1∣T=t,X), then compute contrasts. The DR- and R-learners adapt the pseudo-outcome (AIPW) machinery to form orthogonalized estimates.
Efficient Influence Function-Based DR/R-Learners
The main theoretical advance is the derivation and formal justification of DR-learners and corresponding R-learners directly targeting the conditional OR and RR (on both natural and logarithmic scales). For example, the DR-OR estimator regresses an EIF-based pseudo-outcome for OR(X) on covariates; analogous constructions are made for RR, logOR, and logRR. The EIF-based pseudo-outcomes guarantee that their conditional mean matches the target estimand up to a second-order remainder in the error of the estimated nuisance functions OR(X)=P(Y=1∣T=0,X)/(1−P(Y=1∣T=0,X))P(Y=1∣T=1,X)/(1−P(Y=1∣T=1,X))0 (outcome regressions and propensity), crucially yielding Neyman orthogonality under the Foster-Syrgkanis framework (2604.10412).
The R-learner variants are realized as propensity-overlap-weighted squared loss minimizations of the same pseudo-outcomes. The full theoretical results establish:
- Conditional mean representations with only second-order bias in nuisance error,
- Population risk minimization properties,
- Orthogonal loss function structure leading to favorable excess risk bounds,
- Complete proofs for all considered contrasts and both DR and R configurations.
Monte Carlo Evaluation
Simulation Design
The simulations rigorously stress-test the methods on a grid of data-generating processes (DGPs) varying interaction order among covariates, presence of treatment effect heterogeneity (HTE), and sample size. DGPs are sampled using Dirichlet and GP process priors to capably emulate realistic and complex confounding and heterogeneity structures.
Competing Methods
- LR/S-Learner: Logistic regression, with and without covariate interactions.
- T-Learner/SuperLearner: Meta-learners splitting or pooling on OR(X)=P(Y=1∣T=0,X)/(1−P(Y=1∣T=0,X))P(Y=1∣T=1,X)/(1−P(Y=1∣T=1,X))1.
- Plug-in DR: Two-stage pseudo-outcome regression (DR-P), standard within the CATE literature.
- Novel DR- and R-learners: EIF-based for OR, RR, and their log variants.
Metrics
Estimation performance was assessed using integrated mean squared error (iMSE), integrated squared bias, and variance, with transformations to log scale for ratios to facilitate interpretable comparison.
Results
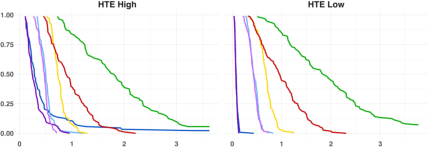
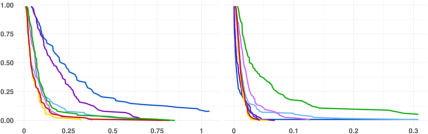
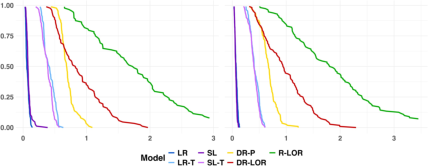
Figure 1: Conditional OR estimation performance (iMSE, iBiasOR(X)=P(Y=1∣T=0,X)/(1−P(Y=1∣T=0,X))P(Y=1∣T=1,X)/(1−P(Y=1∣T=1,X))2, iVariance) for interaction order 3, sample size 2000.
Across high-complexity DGPs with strong HTE and large OR(X)=P(Y=1∣T=0,X)/(1−P(Y=1∣T=0,X))P(Y=1∣T=1,X)/(1−P(Y=1∣T=1,X))3, the proposed DR-LOR outperforms parametric approaches and nonparametric S/T-learners, yielding dominant iMSE and significant bias mitigation (see Figure 1). Parametric models display considerable bias, only being competitive when the underlying signal is simple or sample size is small (where variance dominates). For moderate and low HTE or small OR(X)=P(Y=1∣T=0,X)/(1−P(Y=1∣T=0,X))P(Y=1∣T=1,X)/(1−P(Y=1∣T=1,X))4, SuperLearner and LR achieve comparable or better iMSE due to lower variance despite higher bias. DR-P strikes an intermediate bias-variance balance but fails to match direct-targeting DR-LOR and DR-LRR in the high-complexity regime.
The empirical reliability functions for iMSE demonstrate that the DR-learner versions achieve superior right-tail behavior in iMSE, a critical consideration for practitioners targeting worst-case DGPs.
Figure 2: Conditional OR estimation for interaction order 3, sample size 200 (variance-dominated regime).
R-learner variants invariably exhibit excessive variance, even in well-powered settings, due to aggressive weighting and should thus be eschewed in favor of DR-based or ensemble methods.
Coverage of All Configurations
The ranking is robust across all metrics and sample sizes, as detailed in supplementary tables. The debiased ratio learners (DR-LOR/DR-LRR) provide the most significant gains in nonparametric/high-variance settings, with the bias-variance characterization governing practical selection.
Real Data Application: NHANES Physical Activity Effect on Sleep
The methodology is illustrated using NHANES data to estimate the effect of physical activity on trouble sleeping, leveraging a rich set of demographic and clinical covariates.
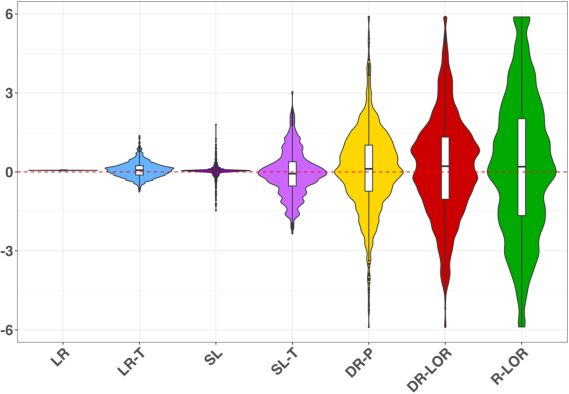
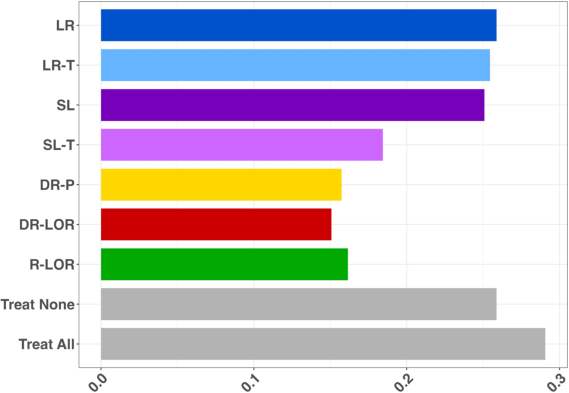
Figure 3: Distribution of estimated conditional log-odds ratios and evaluation of treatment rules for reducing sleep trouble incidence using DR-LOR, R-LOR, SL-T, LR, and naive treat-all recommendation.
The empirical conditional effect heterogeneity captured by DR-LOR/R-LOR is broad, in contrast to the constant effect from logistic regression, and leads to improved individualized treatment rule evaluation (lower mean counterfactual risk by TMLE estimation). This validates the practical gain from EIF-driven approaches persisting even in complex, confounded real-world data.
Theoretical and Practical Implications
Theoretical advances include universality of orthogonal risk minimization for ratio estimands, with full Neyman orthogonality established for loss functions constructed from EIFs of OR and RR. Oracle inequalities and fourth-order convergence rates in nuisance estimation error confirm super-efficiency in the doubly robust regime.
Practically, the results provide direct recommendations:
- Use DR-learner estimators (log-scale variants) for conditional OR/RR in settings of high complexity, sufficient sample size, and strong likelihood of model misspecification.
- For simpler settings or small OR(X)=P(Y=1∣T=0,X)/(1−P(Y=1∣T=0,X))P(Y=1∣T=1,X)/(1−P(Y=1∣T=1,X))5, default to LR or SuperLearner, optimizing for stability and computational tractability.
- Avoid R-learner weighting for ratio contrasts.
Future Directions
The study is limited by the dimensionality supported in simulation and by a focus on binary outcomes/treatments. Extensions would generalize orthogonal pseudo-outcome derivations to continuous or time-to-event endpoints and scale the empirical exploration to larger covariate spaces. Integrating these developments with calibration and uncertainty quantification for individualized rules remains an important next step.
Conclusion
This paper rigorously establishes the feasibility and superiority of orthogonal machine learning for conditional odds and risk ratios, equipping practitioners with robust, low-bias estimators for advanced personalized effect discovery and decision rule development in high-dimensional, confounded data. The empirical results and theoretical guarantees together support wide adoption in causal inference and precision medicine pipelines.
Figure 4: Conditional OR estimation (iMSE, iBiasOR(X)=P(Y=1∣T=0,X)/(1−P(Y=1∣T=0,X))P(Y=1∣T=1,X)/(1−P(Y=1∣T=1,X))6, iVariance) for interaction order 1, sample size 2000, demonstrating increased estimator agreement as underlying structure simplifies.
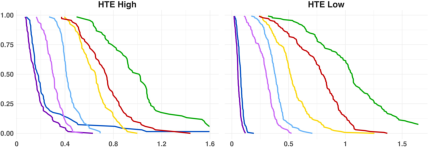
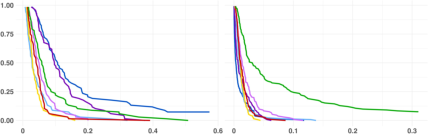
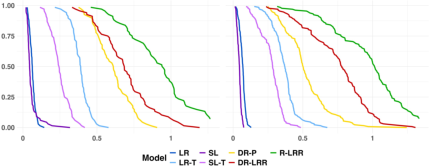
Figure 5: Conditional RR estimation for interaction order 3, sample size 2000 (log-scale), illustrating congruence with findings from the OR analysis and gains of DR-LRR in high complexity.
Reference: "Orthogonal machine learning for conditional odds and risk ratios" (2604.10412)