- The paper introduces NOMAD, a distributed-memory system that scales graph embedding using efficient MPI collectives and bounded staleness.
- Key methodology involves random-walk sampling with six algorithmic variants and an owner-computes model for conflict-free, parallelized updates.
- Experimental results demonstrate significant speedups (up to 370×) and micro-F1 quality improvements (up to 157% over LINE) on massive, billions-edge graphs.
NOMAD: A Distributed-Memory System for Scalable Graph Embedding
Introduction
The ever-increasing size and complexity of real-world graphs in scientific and industrial domains necessitates highly scalable algorithms for network embedding. While shallow proximity-based models such as LINE, DeepWalk, and node2vec have demonstrated efficacy for structure-preserving embeddings, their practical use is severely limited on massive graphs due to the quadratic cost of classic dimensionality reduction and severe bottlenecks stemming from memory capacity, irregular access patterns, and synchronization overhead in distributed environments. The paper "NOMAD: Generating Embeddings for Massive Distributed Graphs" (2604.09419) addresses these challenges by introducing NOMAD, a Message Passing Interface (MPI)-based framework for scalable end-to-end graph embedding on partitioned, distributed-memory graphs.
NOMAD System Design
NOMAD implements a distributed-memory version of the second-order proximity model underlying LINE, and supports efficient random-walk-based positive pair generation, degree-biased negative sampling, and parallelized gradient updates. Graph vertex and edge partitions are distributed across processes in a 1D vertex-based scheme, with each process exclusively updating the embeddings it owns and buffering communication for remote vertices and context embeddings. MPI collectives (especially Alltoallv) are used to efficiently implement the two-phased remote embedding update: fetching the required context embeddings, and sending back accumulated delta updates after local computation.
NOMAD maintains asynchrony and scalability via bounded staleness, which avoids strict synchronization and enables processes to employ slightly delayed embeddings for quality retention and communication amortization. This design permits aggressive parallel exploration and update, dramatically reducing both the communication frequency and the potential for conflicts in embedding updates.

Figure 1: Bounded staleness permits progress with delayed context updates, reducing synchronization bottlenecks at limited quality loss.
Random Walk Sampling and Trade-Offs
Random-walk-driven sampling is central to NOMAD's embedding generation process and is the scalability bottleneck at large scale. The system proposes six algorithmic variants for balancing sample quality, load imbalance, memory demands, and distributed synchronization:
- Local Sampling: Communication-free, each process performs random walks on its local subgraph, yielding maximal scalability but limited cross-partition structural coverage.
- Remote Fresh-Only: Distributed walks with high-quality, fresh samples per batch, but causes significant communication and synchronization overhead.
- Remote Reuse-Spill / Refresh-Spill: Spill buffers amortize distributed sampling cost across batches, at the expense of possible sample staleness.
- Remote Augmented-Single / Augmented-Pair: Upfront random walk sampling and combinatorial sample augmentation trades computation and memory for minimized runtime communication.
By allowing users to tune this tradeoff, NOMAD covers a broad range of operational regimes, including settings where embedding quality must be maximized, or where performance is the overriding concern.
Distributed Embedding Update Mechanics
For each batch, positive samples and corresponding negative samples (drawn from a global, degree-biased distribution with exponent α=0.75) are generated. If both vertices in a pair are local, updates are performed immediately. Remote context vertices are resolved by two-stage batched collective communication and update, with each owner process accumulating all deltas pertaining to each of its owned context embeddings before applying the updates. This owner-computes model ensures consistent embedding updates without lock contention.
NOMAD further explores MPI neighborhood collectives and MPI-3 RMA (remote memory access) one-sided communication, providing a broad palette of trade-offs between communication topology, atomicity, and load balance.
Experimental Evaluation and Results
Baseline Comparison
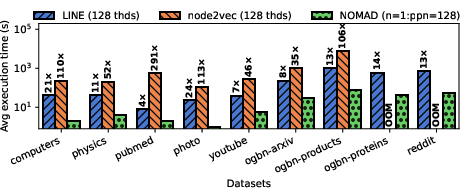
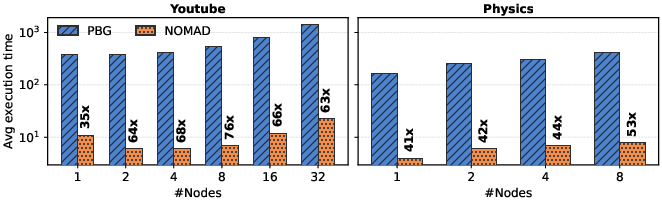
NOMAD demonstrates substantial performance improvements over both strong shared-memory and distributed-memory baselines:
Embedding Quality
NOMAD delivers embedding quality competitive with, and often exceeding, strong baselines. Micro-F1 improvements of 5--29% over the best single-node baseline are observed on several datasets; maximum observed improvement is up to 157% versus LINE, 55% versus GraphVite, and 31% versus node2vec. This gain results from the ability to fully exploit distributed-memory for exhaustive random-walk-based context extraction.
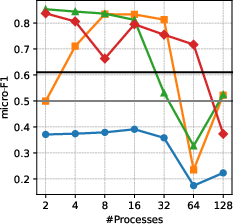
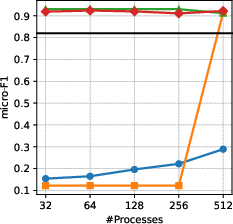
Figure 4: Micro-F1 quality increases with process count on computers (left) and reddit (right), especially with appropriate sampling variants.
Scalability and Imbalance Analysis
NOMAD achieves order-of-magnitude parallel speedups on diverse graphs. However, scalability is sensitive to sampling variant, synchronization choice, and partition-induced imbalance; the most communication-avoiding variants (e.g., Local, Aug-Pair) show the best scaling at the expense of possible sample quality loss under severe partition skew.
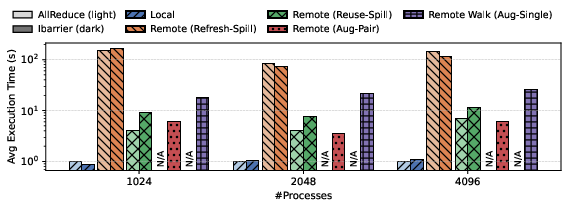
Figure 5: End-to-end time for each NOMAD variant (e.g., AR-Local, AR-Aug-Pair) on ogbn-arxiv shows augmented-pair variants minimize sample imbalance cost.
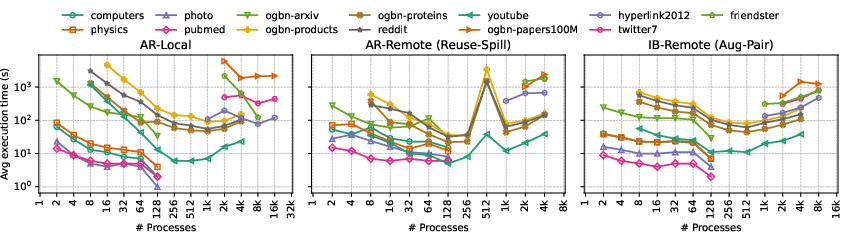
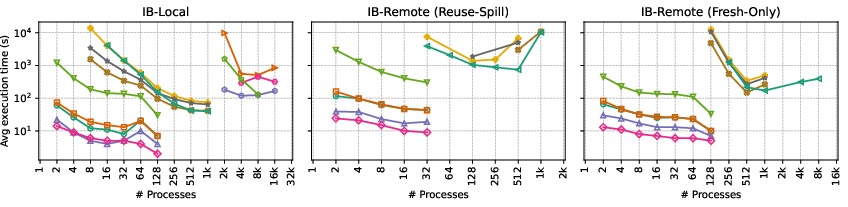
Figure 6: Scalability across 13 datasets indicates robustness of AR-Local and AR-Aug-Pair strategies on process counts up to 16K.
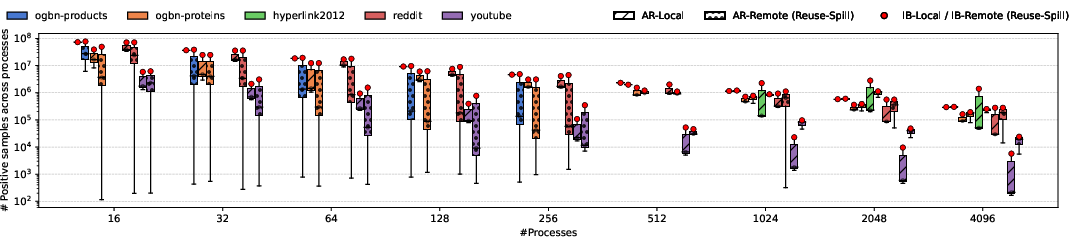
Figure 7: Imbalance in sample generation distribution is visible in AR-Local; AR-Remote (with spill) suffers high variability, mitigated by IBarrier-based variants.
Communication, Memory, and System-level Trade-offs
Detailed system profiling reveals that random-walk sampling dominates runtime as scale grows, with communication overheads further inflated by partition skew and irregular sampling patterns. The benefit of large (2MB) huge pages is workload and scale dependent, providing up to 4× improvement for embedding updates when memory fragmentation is low. One-sided RMA communication, while conceptually elegant, increases load imbalance at scale, reflected in the higher proportion and variability of MPI synchronization time.
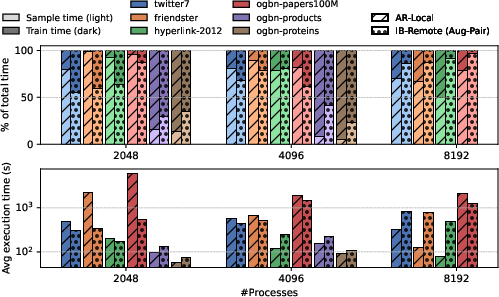
Figure 8: Training time can be dominated by either sampling or embedding updates, contingent on input graph structure and variant.
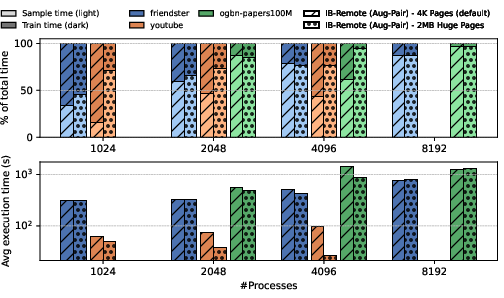
Figure 9: Adoption of 2MB huge pages significantly enhances training and sampling efficiency, with speedup most prominent on large graphs and mid-scale process counts.
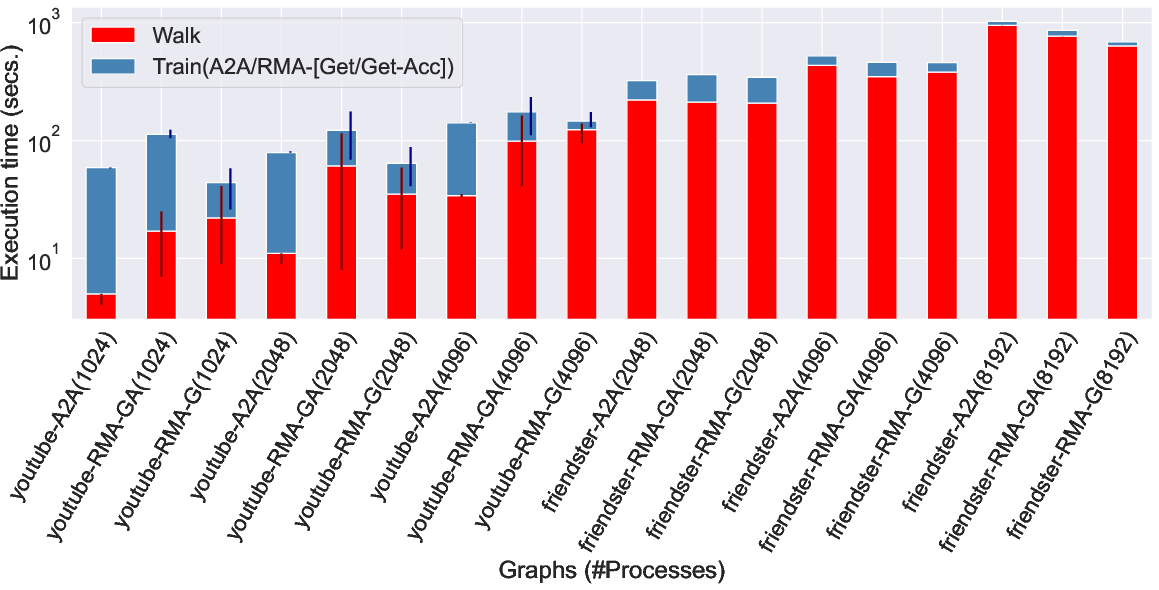
Figure 10: RMA-based variants show increased performance variability and imbalance, especially for repeated remote sampling strategies.
Implications and Future Directions
NOMAD demonstrates that end-to-end structure-only graph embedding can be made highly scalable on distributed-memory, with principled tradeoffs across embedding quality, communication, and synchronization. The system is inherently agnostic to cluster hardware, relying only on well-designed MPI patterns and data batching, favoring adoption for massive scientific and web graphs where node features and labels are sparse or unavailable.
NOMAD's approach paves the way for further generalizations, including direct support for GNN pre-training, integration with node-attribute-aware message-passing models, and potentially extending to asynchronous, fault-tolerant environments. Improved load balancing for extreme-scale and multi-modal graphs, and extension to GPU clusters with hybrid MPI+CUDA models, present natural next steps for the field.
Conclusion
NOMAD advances the state of practice for distributed graph embedding, offering flexible synchronization and sampling strategies that enable strong speedups (up to 370× over single-node and 76× over distributed baselines) and high-quality representations on graphs with billions of edges. Its design principles, extensive evaluation, and ablation over tradeoffs provide an authoritative blueprint for large-scale, structure-preserving representation learning in distributed settings (2604.09419).