- The paper introduces a hybrid framework combining multi-scale pyramid feature extraction with Clifford algebra fusion to efficiently restore UHD low-light images.
- It employs frequency decoupling and a Retinex-inspired dynamic mapping to enhance color fidelity and suppress noise in challenging conditions.
- Empirical results show up to 115.2 FPS at 4K and robust performance in downstream detection tasks with minimal memory overhead.
Clifford Pyramid Enhance: Real-Time UHD Low-Light Image Enhancement via Clifford Algebra Fusion
Introduction and Motivation
Ultra-high-definition (UHD) low-light image enhancement at 4K/8K resolutions presents formidable computational and algorithmic challenges, particularly in the context of real-time requirements on edge devices. State-of-the-art Transformer-based and complex CNN architectures encounter severe memory bottlenecks—the so-called "memory wall"—and exhibit excessive inference latency, rendering them impractical for large-scale inputs. Conversely, lightweight curve-based models achieve high throughput but at the cost of poor denoising and color fidelity due to their inability to decouple frequency bands effectively.
The paper "UHD Low-Light Image Enhancement via Real-Time Enhancement Methods with Clifford Information Fusion" (2604.09321) addresses these bottlenecks through a hybrid approach—integrating efficient pyramid-based feature extraction with a novel Clifford algebraic feature fusion module. This framework, Clifford Pyramid Enhance (CPE), is specifically designed for both computational efficiency and high-fidelity restoration in UHD scenarios, targeting deployment on consumer-grade and edge hardware.
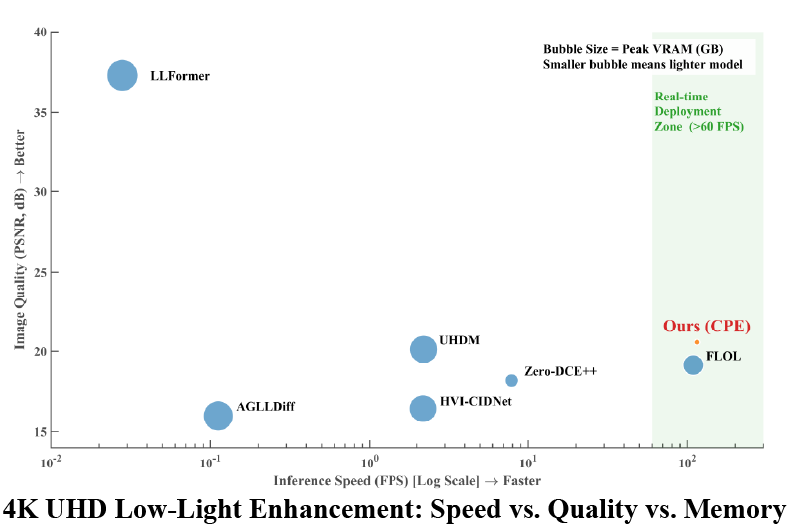
Figure 1: Comprehensive performance of low-light enhancement models at 4K, contrasting inference speed, memory (bubble size), and image quality (PSNR); green zone denotes real-time feasibility.
Architecture and Methodology
Multi-Scale Pyramid with Frequency Decoupling
CPE adopts a four-level feature pyramid where each spatial scale progressively upsamples a compact tensor representation of the input. Each pyramid level separates low- and high-frequency features using a 3×3 Gaussian blur—decomposing the image into illumination (scalar) and structure (vector) channels. These bands are each processed by lightweight, depthwise-separable UNet branches that maximize receptive field while minimizing parameter overhead.
Clifford Algebra Fusion for Geometric Consistency
Traditional feature fusion by concatenation or addition often collapses geometric and color relations, leading to texture misalignment and artifacts. CPE introduces a feature fusion module based on 2D Clifford algebra (Cl(2,0)), projecting feature tensors into a multivector space that distinctly encodes scalar intensity, spatial directionality (vectors), and local orientation (bivectors).
Within this space, fusion is executed via a geometric product and similarity mask that measures spatial directional alignment between frequency bands. This mechanism prioritizes retention of structures in directional-consistent regions and suppresses noise in spatially chaotic regions, circumventing degradation typical of linear fusion.
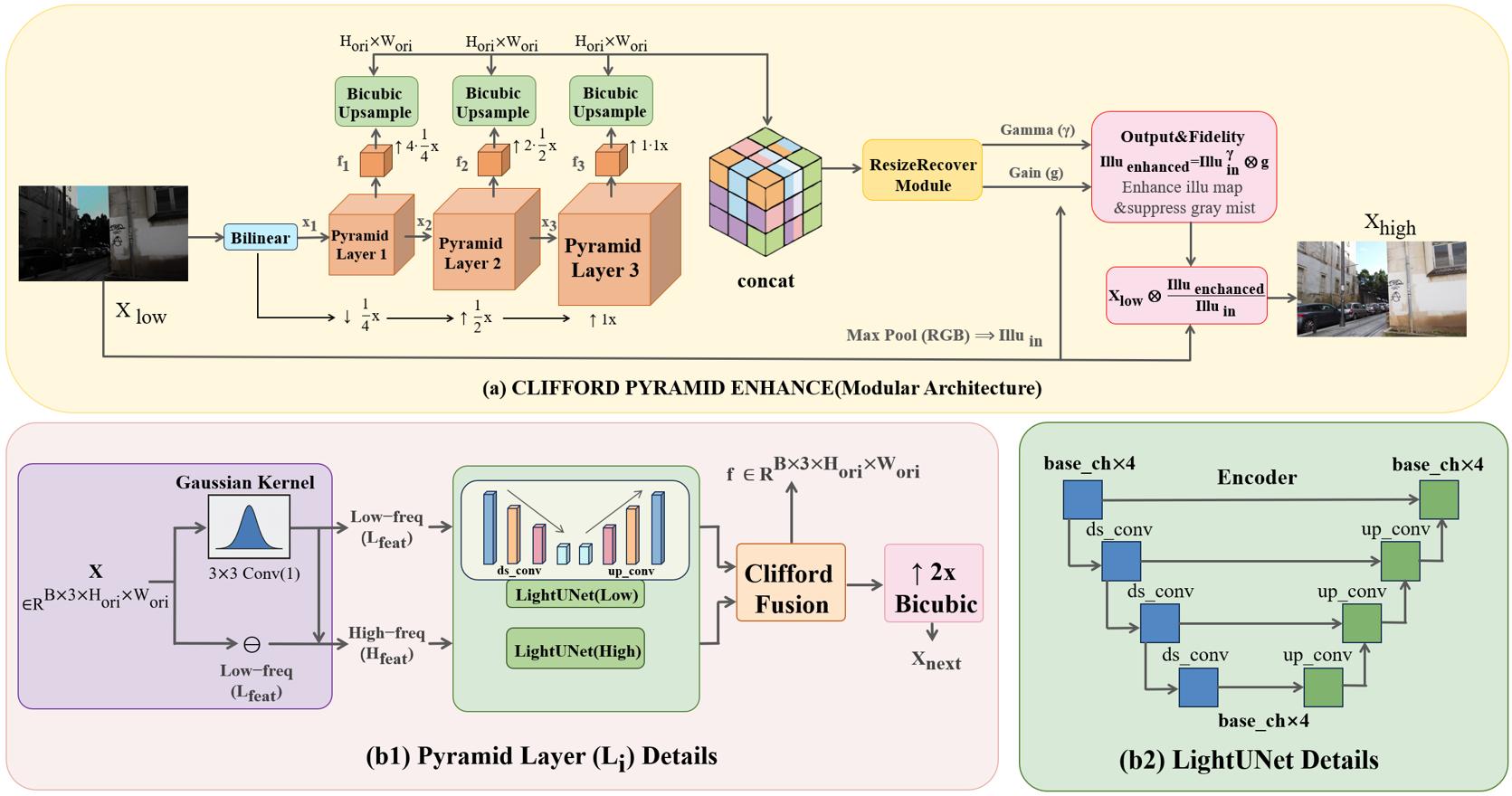
Figure 2: Overview of CPE framework, including frequency-decoupled extraction and Clifford algebraic feature fusion across pyramid stages.
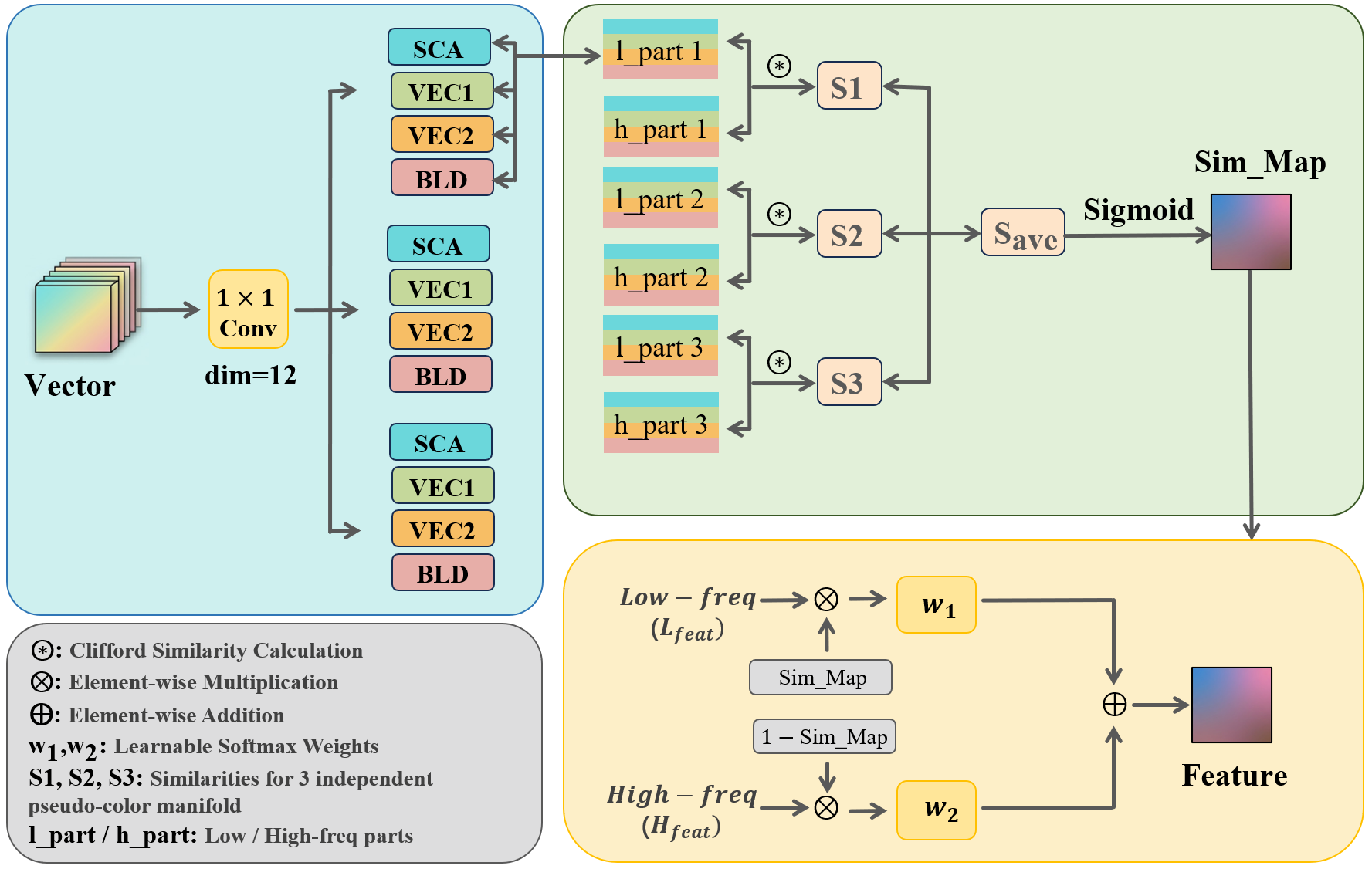
Figure 3: Clifford Feature Fusion module, projecting channel-wise features into multivector form for geometric similarity-based aggregation.
Dynamic Resolution Reconstruction and Retinex Mapping
Final enhancement occurs at native resolution, leveraging spatially adaptive Gamma and Gain maps derived from the multi-scale fused feature block. These maps parametrically adjust illumination in a Retinex-inspired fashion, nonlinearly scaling log-illumination to restore exposure and maintain strict RGB channel proportionality, thus guaranteeing color constancy while avoiding the pitfalls of direct residual prediction.

Figure 4: Retinex-based dynamic adaptive brightness and color mapping process from initial illumination extraction to final enhancement.
Empirical Results and Numerical Analysis
Quantitative Evaluation
CPE demonstrates superior Pareto-optimality in both quality and efficiency. On UHD-LOL 4K/8K benchmarks, CPE delivers 115.2 FPS (8.68 ms latency) at 4K and 87.0 FPS (11.49 ms latency) at 8K natively—orders of magnitude faster than Transformer and diffusion models, which can exceed several minutes per 8K frame or require severe downsampling and patching that destroy detail.
Quality metrics show competitive or superior results compared to baselines:
- 4K PSNR: 20.56 dB (CPE) vs 18–21 dB (lightweight baselines; 37.31 dB for LLFormer with prohibitive latency)
- 8K PSNR: 22.80 dB (CPE); SSIM: 0.9453
- Consistently lower VRAM consumption (<1.2 GB at 8K) without OOM issues

Figure 5: Visual comparisons demonstrate CPE's superiority in restoration, avoidance of patch artifacts, and preservation of fine textures at native resolution.

Figure 6: Comparative assessment of global illumination consistency and suppression of grid artifacts in extremely dark scenes.
Qualitative Insights
CPE achieves uniform global exposure adjustment, circumvents artifacts from patch-based pipelines, and retains native high-frequency details even at 8K. In particular, it sidesteps blurring and color shifts found in curve-fitting and simple CNNs, as well as the high-frequency loss in downsampling-based acceleration schemes.


Figure 7: Native 4K/8K reconstruction by CPE preserves fine text and structure, outperforming downsampling or patch-based competitors.

Figure 8: CPE maintains robust color fidelity and suppresses noise without over-enhancement or color shifts in dark regions.
Ablation and Component Analysis
Systematic ablations confirm:
- Frequency decoupling reduces memory footprint and improves denoising.
- Multiscale fusion without proper constraint can degrade performance—Retinex mapping corrects this.
- Incorporating Clifford fusion yields ~1 dB PSNR gain over the multi-scale + Retinex baseline at virtually zero parameter or latency cost, confirming its unique role in robust spatial alignment.
Downstream Task: Object Detection
When integrated as a preprocessing stage for state-of-the-art detectors (YOLOv10x), CPE's enhancements led to the identification of 576 (8K) and 2264 (4K) objects, exceeding most lightweight/fast baselines. While LLFormer is slightly superior in absolute detection count, CPE achieves 98.6% of its performance with a 14,000× speedup, demonstrating very strong utility for real-time high-level vision in challenging lighting.

Figure 9: Downstream nighttime detection results show CPE enables robust small-object recognition under severe low-light.
Practical Implications and Limitations
CPE's fusion of geometric reasoning and Retinex-inspired, resolution-agnostic parameter mapping fundamentally redefines the tradeoff space for UHD enhancement. It is deployable on commercial smartphones, running full 8K enhancement in ~312 ms and easily satisfying the frame-rate and resource constraints of edge vision systems.
Limitations persist, including minor color halos near intense lights and flicker when extended to video streams, potentially due to the single-frame design. Over-reliance on Retinex priors might limit generalizability to non-canonical degradation.
Figure 10: Hardware overhead comparison, with CPE avoiding OOM and sustaining real-time operation across resolutions.
Theoretical and Future Directions
The work exemplifies a shift toward incorporating geometric algebraic constraints into deep vision models, moving beyond simplistic channel mixing or even quaternionic approaches, to capture higher-order relationships in color and structure. Potential avenues include extending Clifford-based reasoning to spatio-temporal and generative video priors, dynamic HDR processing, and multitask pipelines co-optimizing perception and enhancement.
Conclusion
CPE introduces an effective, scalable solution for real-time UHD low-light enhancement, enabling both practical deployment and rigorous performance in unconstrained visual environments. The integration of Clifford algebraic fusion with multi-scale latent processing offers a compelling computational and geometrical paradigm for future low-level vision research. The implications suggest promising directions for geometry-aware representations and efficient vision systems tailored for edge hardware and streaming applications.

