- The paper presents a novel framework that uses global spatiotemporal features and a transformer-graph architecture for accurate, early accident anticipation.
- The methodology leverages a pretrained VideoMAE-V2 backbone with a Transformer Encoder and graph transformer to model local and causal temporal dependencies.
- Experimental results demonstrate superior Average Precision and mean Time-to-Accident metrics across multiple datasets while reducing computational overhead.
Vision-based Accident Anticipation with Global Features: An Analysis of VAGNet
Introduction
Anticipating traffic accidents proactively is essential for effective deployment of Advanced Driver Assistance Systems (ADAS) and autonomous vehicles. Traditional methods for accident anticipation from on-board dashcam video depend heavily on computationally intensive object detection and per-object feature extraction pipelines. The proposed VAGNet framework addresses these inefficiencies by leveraging global features extracted from traffic scenes, employing a transformer-graph hybrid architecture, and utilizing foundation model representations. This essay provides an in-depth technical review of the VAGNet approach, including its architecture, comparative empirical results, and practical/theoretical implications.
Methodology and Architecture
VAGNet introduces a fundamentally different processing pipeline that omits explicit object-centric reasoning, instead utilizing high-dimensional spatiotemporal embeddings from a pretrained VideoMAE-V2 foundation model. The core architecture comprises three key stages: global spatiotemporal feature extraction, temporal modeling via a Transformer Encoder, and causal temporal dependency modeling with a graph transformer.
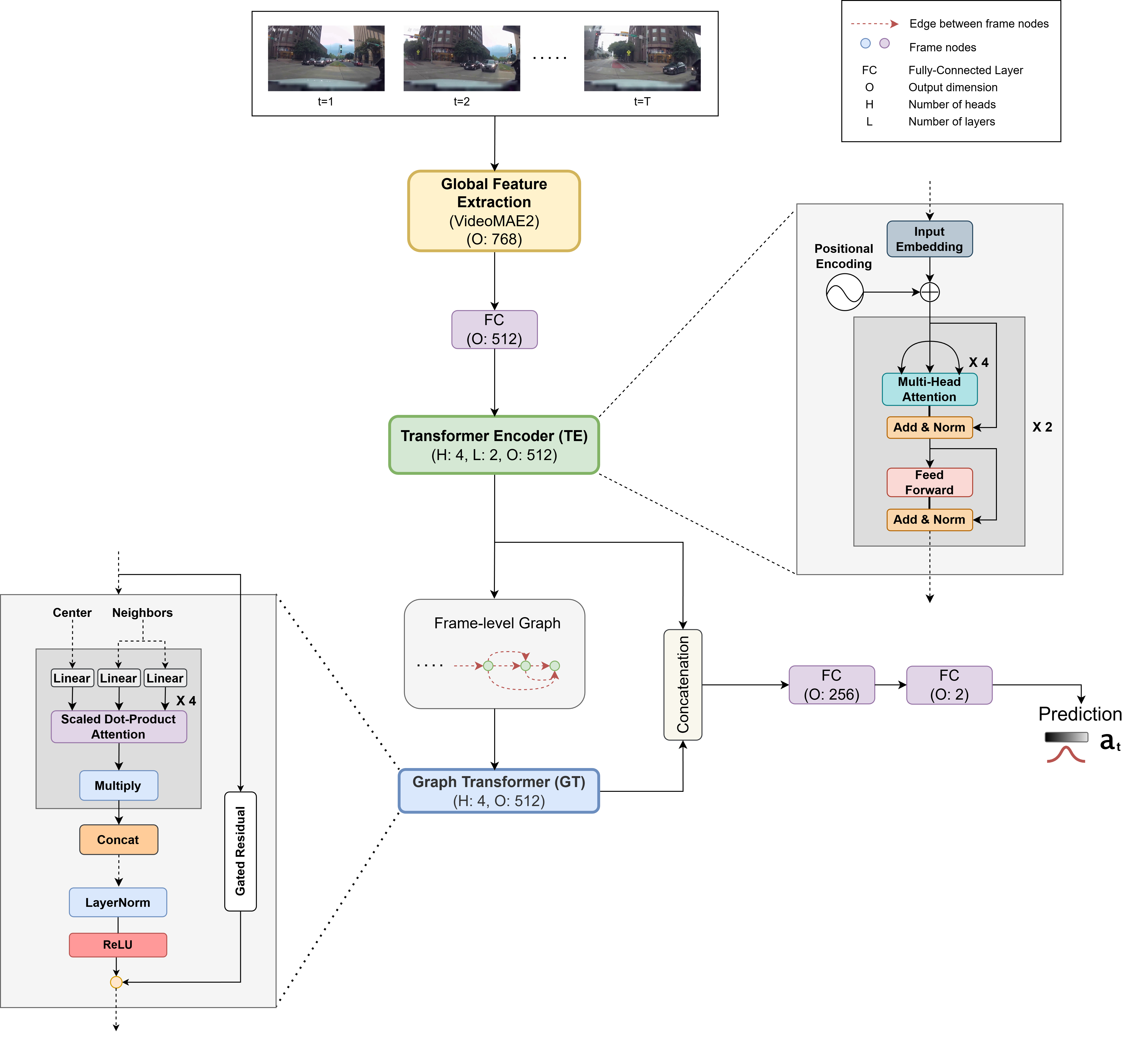
Figure 1: Architecture of the proposed VAGNet accident anticipation framework.
For each input frame at time t, a sequence of u+1 frames (from t−u to t) is passed through VideoMAE-V2, generating a global video-level representation. This embedding is linearly projected and input to a two-layer, multi-head self-attention Transformer Encoder to model local temporal context. The resulting features are then structured as nodes in a directed temporal graph, where edges capture causal dependencies over a fixed window (v previous frames per node). These frame-level features are further processed by a graph transformer, which facilitates dynamic weighting of temporally significant frames for anticipation. Finally, the concatenated representations are fed to a classifier for framewise accident probability estimation.
The entire network, except for the frozen VideoMAE-V2 backbone, is trained end-to-end using supervised cross-entropy loss.
Dataset Design and Crash-Object Analysis
The empirical study uses four established benchmarks: DAD, DADA, DoTA, and Nexar. VAGNet's evaluation prioritizes ego-involved accidents due to their direct relevance for collision avoidance in ADAS and autonomous driving. Negative samples are sampled strictly from non-accident footage in the same source dataset to robustly control for potential domain and quality biases—a common confound in prior work.
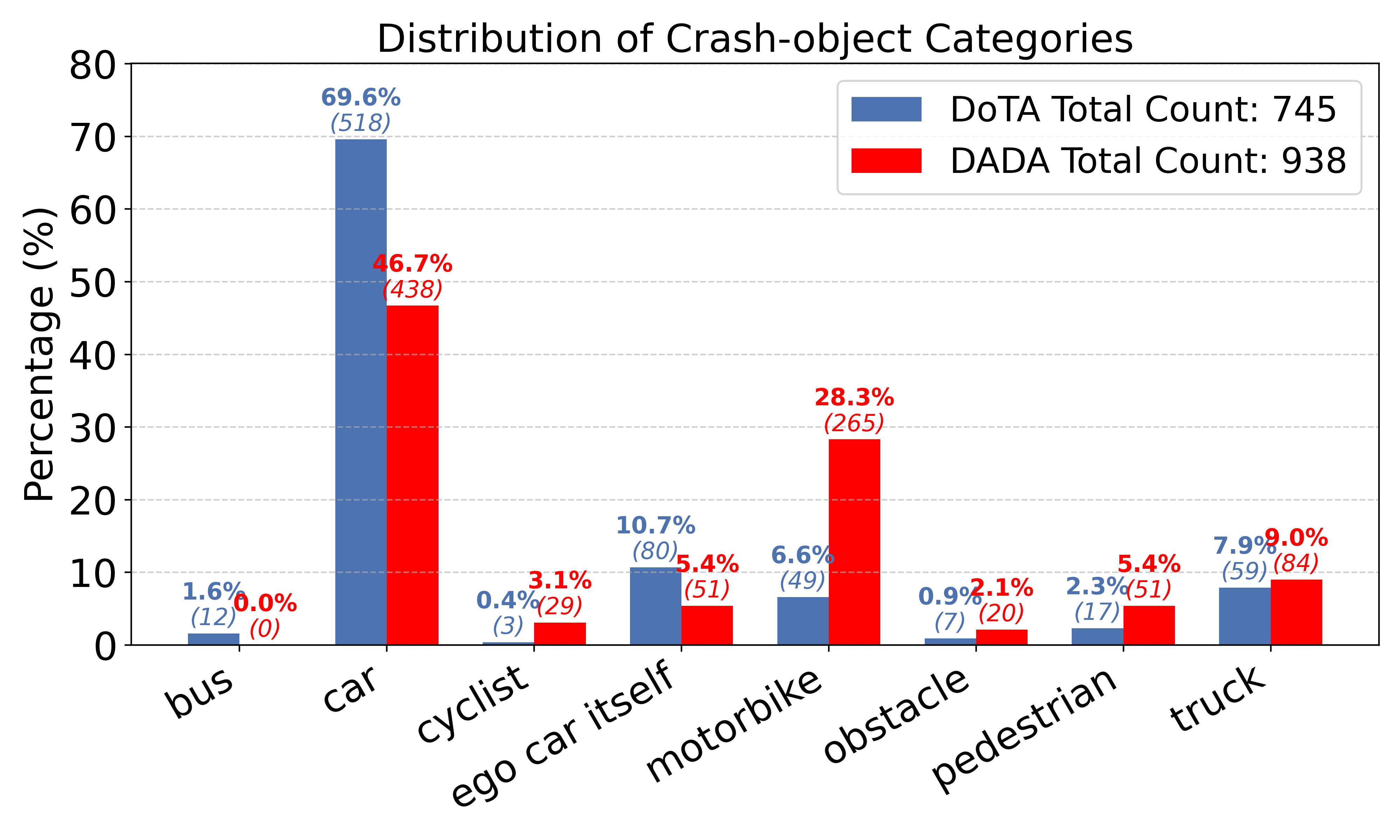
Figure 2: Distribution of crash-object categories in the DoTA and DADA datasets. Crash-object category annotations are not available for the Nexar dataset.
The object category distributions in DoTA and DADA highlight coverage over vehicle, pedestrian, and static-object collisions, benchmarking generalization across practical accident scenarios.
Experimental Results
Accuracy and Early Anticipation
VAGNet attains superior Average Precision (AP) and mean Time-to-Accident (mTTA) across all considered datasets, outstripping both object-centric and multi-modal approaches. For example, VAGNet achieves 97.82% AP and 3.09s mTTA on DADA, and 96.66% AP and 3.22s mTTA on DoTA. Notably, this improvement occurs without auxiliary streams such as 3D depth estimation or driver gaze, underscoring the representational efficacy of global scene features—contradicting the prevailing notion that explicit object-level reasoning is essential for high anticipation accuracy.
The method delivers robust positive and negative case classification throughout video sequences, as illustrated by the temporal evolution of predicted accident probabilities over sequential frames. True positive samples show early and sustained high confidence, whereas false positives/negatives exemplify the fine-grained complexity of real-world scenes near accident boundaries.








Figure 3: Samples showing the variation of predicted accident probability across time/frames for (a) True positive, (b) True negative, (c) False positive, and (d) False negative cases.
Visual Explanation and Model Focus
Application of Grad-CAM to various weather and lighting conditions reveals that VAGNet, despite dispensing with explicit object detectors, reliably localizes salient crash-prone objects and regions in diverse environments. The attention visualizations confirm that global features, when modeled with sufficiently expressive architectures, can recapitulate the spatial selectivity traditionally delivered by bounding box-based feature streams.








Figure 4: Samples of visual explanations for accidents across different weather/lighting conditions. For each condition, the top row shows the original video frames in temporal order, and the bottom row shows the corresponding Grad-CAM maps highlighting areas of high model attention.
Analysis of Feature Backbones and Architecture
A systematic ablation demonstrates that global spatiotemporal features (VideoMAE-V2) consistently outperform 2D and less temporally aware backbones (VGG16, I3D, SlowFast), with the transformer encoder and graph transformer offering strong complementary benefits. The elimination of either temporal processing stage degrades AP and mTTA, confirming the criticality of local and global temporal context modeling. The model's robust performance generalizes across diverse datasets without dependence on per-object or scene attribute heuristics.
Computational Efficiency
Avoiding explicit object detection yields significant improvements in computational efficiency, reducing total FLOPs per frame versus representative baselines. The remaining bottleneck is the VideoMAE-V2 backbone; however, the end-to-end pipeline is more tractable for deployment, and inference throughput approaches require near-real-time rates on current GPU hardware. Object-centric methods incur costs scaling with scene density, whereas VAGNet's complexity is agnostic to the number of visible agents or objects, facilitating deployment in crowded, urban scenarios.
Implications and Future Developments
Practically, VAGNet’s foundation model-based global feature paradigm enables scalable and efficient deployment on embedded vehicle compute resources. The empirical results show that the reliance on foundation models for spatiotemporal abstraction not only removes the need for expensive object pipelines but also confers strong transfer across variable conditions, accident types, and visual domains. Theoretically, these findings contest the long-standing assumption in the vision-ADAS field that cascaded detection and tracking modules must precede anticipation reasoning. As increasingly powerful video foundation models become available, further efficiency gains can be achieved via distillation, quantization, or curriculum-based backbone compression.
The architectural principles underlying VAGNet—temporal self-attention over global features, causal graph-based recurrence, and direct accident probability estimation—are extensible to other real-time risk forecasting tasks in robotics and safety-critical AI. Future directions include end-to-end foundation model fine-tuning for anticipation, cross-modal fusion (e.g., with radar or language), and improved model interpretability via spatiotemporal saliency explanations.
Conclusion
VAGNet substantiates a global-feature, transformer-graph approach for vision-based accident anticipation, establishing new state-of-the-art AP and early-warning metrics on multiple real-world dashcam datasets (2604.09305). Its design bypasses explicit object-centric modeling, achieving both higher computational efficiency and accuracy. The approach illustrates the growing applicability and power of large-scale video foundation models for critical real-time perception tasks and motivates further research into efficient, interpretable, and transferable accident anticipation systems.