- The paper introduces a BVH-accelerated framework that dramatically speeds up shooting-and-bouncing ray tracing for high-frequency electromagnetic backscattering.
- It employs rigorous validation against analytic models, achieving RCS accuracy within ±2.5% for electrically large metallic objects.
- The study highlights efficient parallel GPU implementations and excellent scaling performance, enabling extensive high-frequency CEM parameter studies.
BVH-Accelerated Ray Tracing for High-Frequency Electromagnetic Backscattering
Introduction
The paper "BVH-Accelerated Ray Tracing for High-Frequency Electromagnetic Backscattering" (2604.09243) addresses the computational bottlenecks in high-frequency computational electromagnetics (CEM), specifically the modeling of electromagnetic backscattering from electrically large metallic objects. The work develops a shooting and bouncing rays (SBR) framework, optimized through the use of a bounding volume hierarchy (BVH) to accelerate repeated ray-triangle intersection queries. The SBR pipeline is designed for efficient radar cross-section (RCS) computations in the high-frequency (HF) regime, targeting massively parallel and heterogeneous architectures, with validation against analytic solutions and demonstration on complex geometries such as a full-scale aircraft.
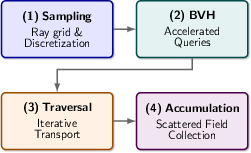
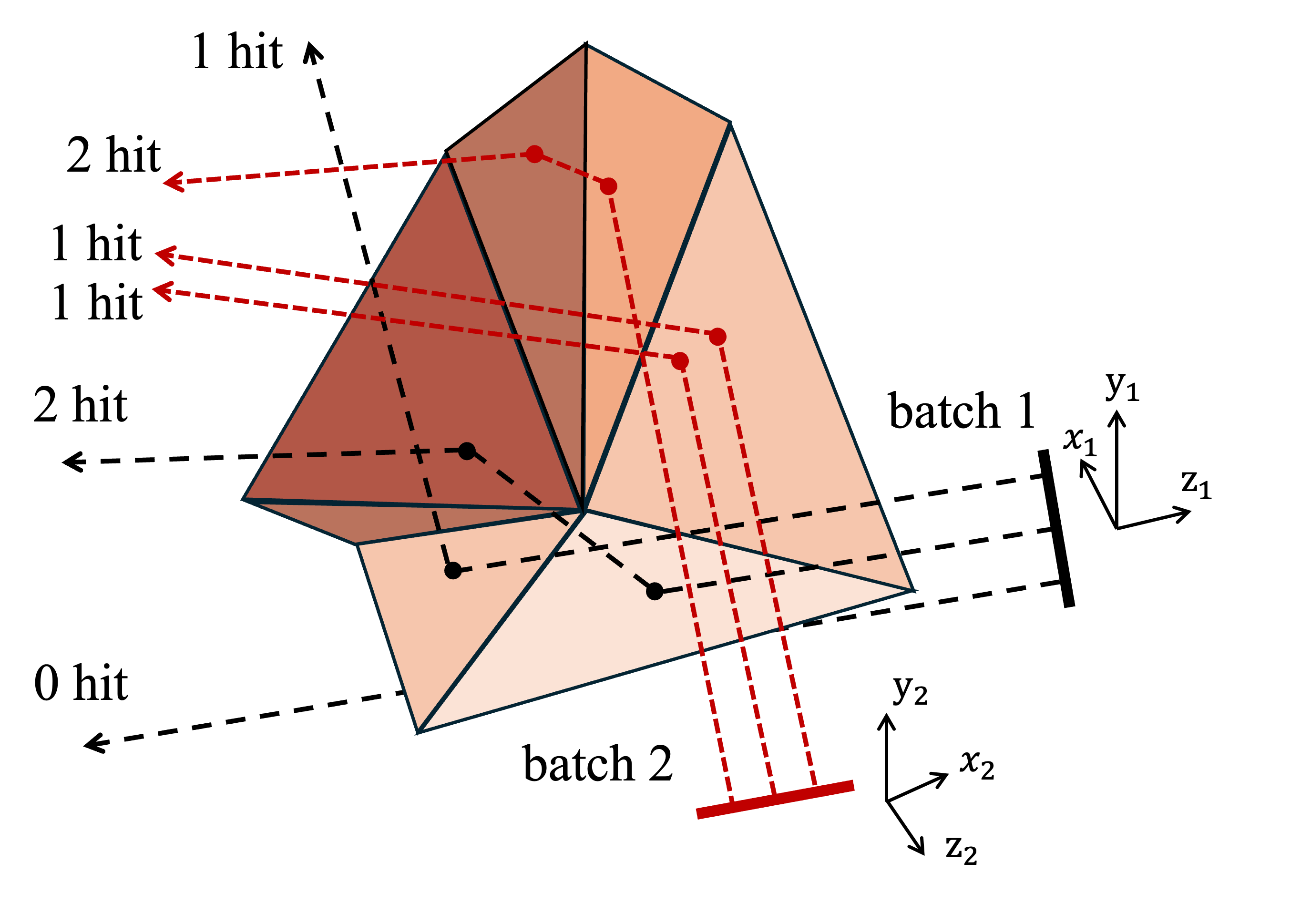
Figure 1: Summary of the SBR pipeline, where rays are launched from an orthographic grid, the BVH accelerates hit detection, and scattered field contributions are accumulated to compute the RCS.
The SBR approach is justified for problems where the characteristic object size D satisfies D/λ≫1, causing conventional full-wave methods to become computationally infeasible. In SBR, an orthographically launched grid of rays impinges on a triangulated mesh, each ray simulating specular multi-bounce propagation governed by the eikonal equations and local boundary conditions. The resulting scattered field is synthesized via a ray-induced discretization of the physical optics (PO) surface integral.
The manuscript formalizes the discrete mapping of the Stratton–Chu surface integral to a sum over ray tubes, with integral accuracy controlled through a conservative ray sampling rule (typically Δs≤λ/5). The implication is a quadratic growth in ray count with frequency, making intersection acceleration structures essential for tractable runtimes.
BVH Construction and Intersection Acceleration
The computational bottleneck in SBR is the O(Nrays⋅Ntriangles⋅Nbounces) cost of repeated ray-triangle queries. To address this, the method constructs a BVH over mesh triangles using either a median split or binned surface area heuristic (SAH). The BVH enables rapid culling of non-intersecting regions in the mesh, amortizing traversal costs over large ray batches with varying coherence. Parallel BVH build and explicit stack-based traversal are employed to support both NVIDIA and AMD GPUs, exploiting task-level parallelism in OpenMP and fine-grained data locality in device kernels.
Numerical Validation and Sampling Tradeoffs
Validation is carried out via frequency sweeps over monostatic RCS of a PEC sphere, compared to analytic Mie theory. Below kr≈30, SBR yields unphysical results due to unresolved wave effects; above this boundary, the approximation yields RCS values within ±2.5% of the analytic result—provided the incident ray grid satisfies the prescribed sampling condition. Aliasing artifacts emerge at high frequencies if Δs is underresolved, manifesting as nonphysical oscillations.
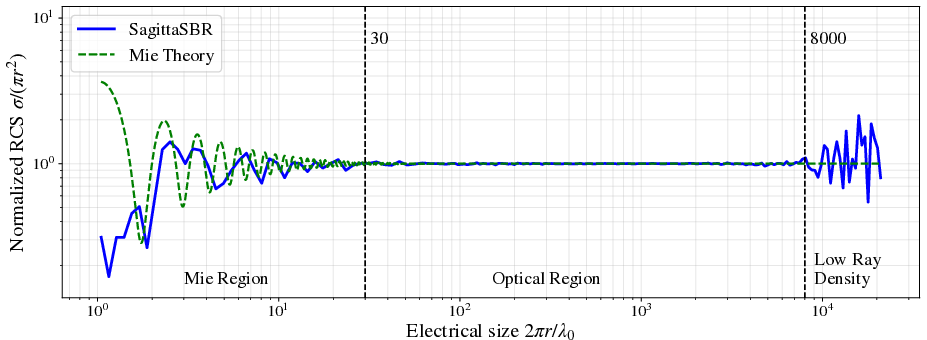
Figure 2: Frequency scan of monostatic RCS for a triangulated PEC sphere showing regions where ray tracing is invalid (Mie resonance), accurate (optical region), and aliased.
Application to Electrically Large Geometries
To demonstrate applicability on complex targets, the authors compute a full-sphere monostatic RCS of an A380 aircraft (modeled as PEC). The simulation leverages a 30,000×30,000 incident ray grid, 100 possible specular bounces per ray, and evaluates 1.125×1014 rays across 125,000 parameter settings. Critical strong specular zones and complex multi-path scattering regions are unambiguously resolved, confirming both the physical modeling capability and computational throughput of the presented pipeline.
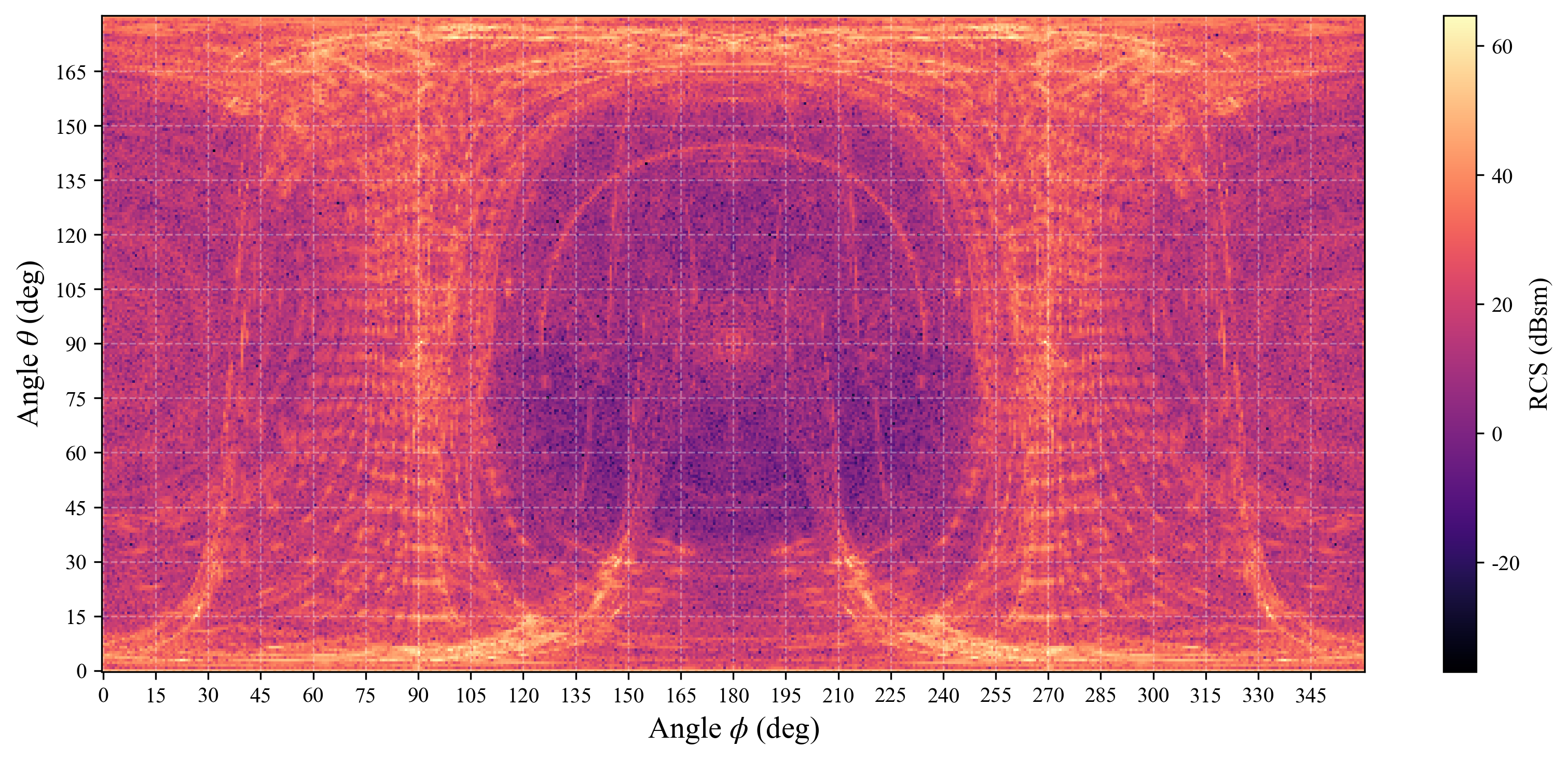
Figure 3: RCS calculation for an A380 aircraft over a dense angular sweep, using 500 samples in ϕ and 250 in D/λ≫10 at 10 GHz.
The pipeline is implemented in SagittaSBR, a C++/CUDA codebase that offloads BVH traversal and field accumulation to GPUs, and orchestrates angular parameter sweeps with MPI parallelism. Each process owns a full copy of geometry and BVH to facilitate embarrassingly-parallel sweeps. Device utilization is maximized by mapping incident rays to threads at launch; divergence after multiple bounces is mitigated by explicit stack management and careful buffer allocation.
Profiling reveals that the ray-intersection kernel is the primary runtime consumer, followed by the PO accumulation kernel. Strong and weak scaling studies on LUMI’s AMD MI250X GPU partition demonstrate 88% and 96% parallel efficiency, respectively, when scaling to 256 GCDs.
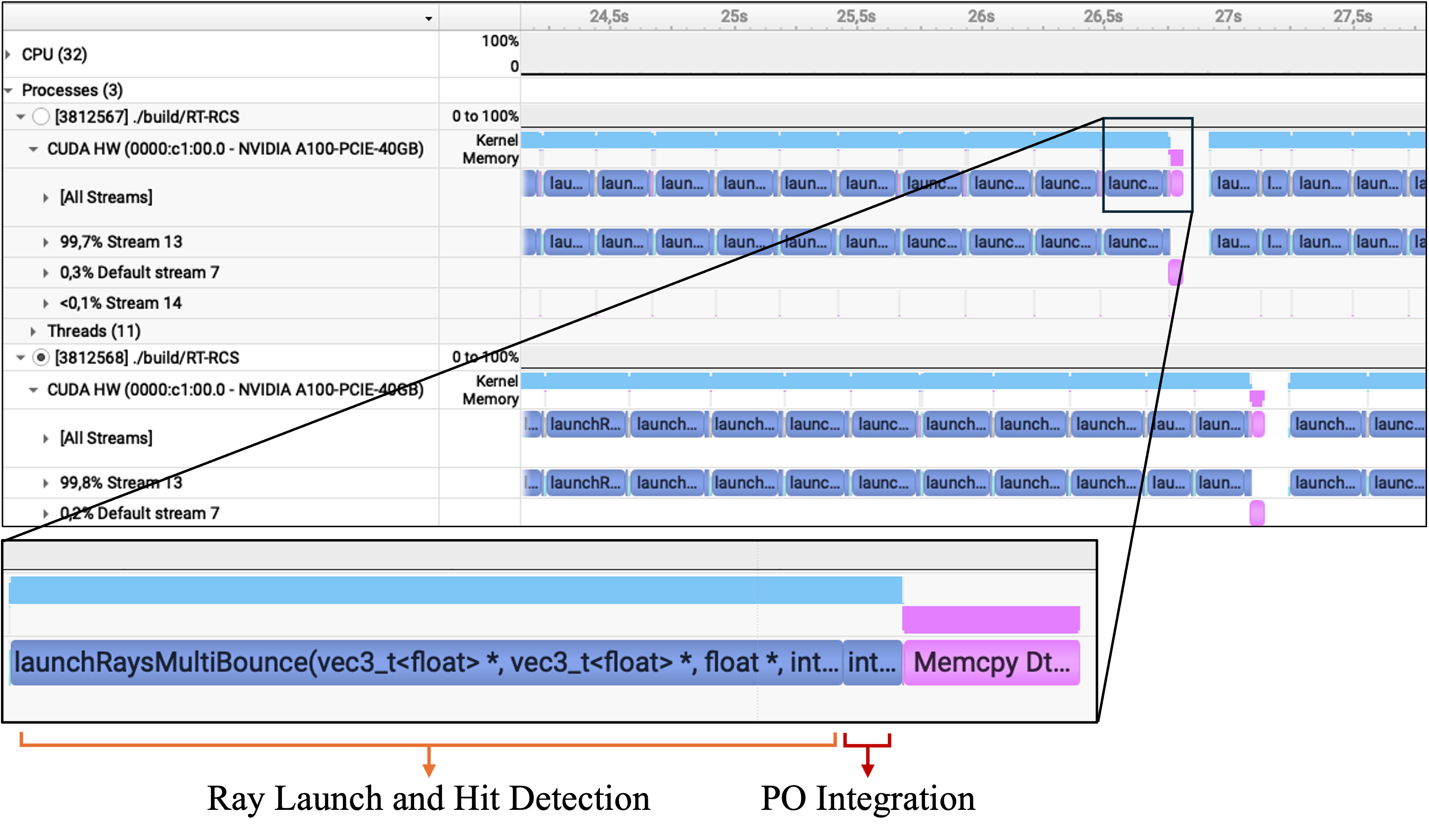
Figure 4: Execution trace on 2 MPI processes with one NVIDIA A100 each, showing pipeline kernel breakdown and intersection cost dominance.
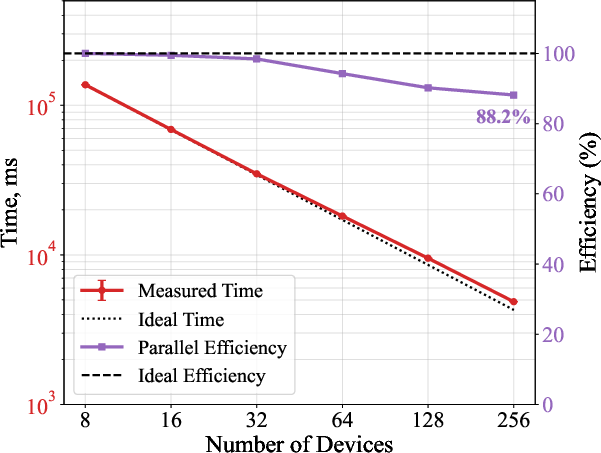
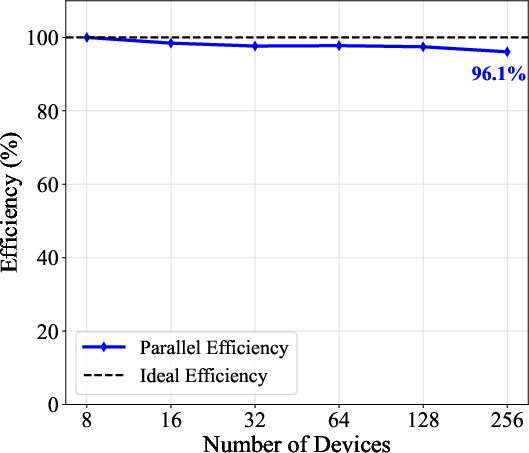
Figure 5: Scaling performance on LUMI (FP32), showing excellent strong and weak scaling with average measurements over 3 trials for D/λ≫11 rays per scan.
Precision and Hardware Considerations
A unique observation is that, on AMD MI250X, FP64 execution is 20% faster than FP32 for these custom workloads, while NVIDIA A100 shows the expected FP64 performance penalty. Choice of numerical precision thus becomes hardware-dependent: FP32 suffices for dBsm accuracy on NVIDIA; FP64 is recommended on AMD.
Discussion
The methodology is robust for high-throughput RCS parameter studies in the GHz regime. The separation of intersection-dominated and reduction-dominated phases, enabled by the trace-integrate decomposition, facilitates both vectorization and node-level parallelization. Architecture-aware kernel tuning is shown to be crucial for throughput, as instruction mix and device microarchitecture yield nontrivial runtime dependencies.
While the GO+PO SBR is restricted to specular mechanisms, the outlined BVH-accelerated framework is ready for integration of higher-fidelity mechanisms (GTD, UTD, PTD) that would further generalize its applicability in CEM—at the cost of increased transport path diversity and per-ray work variance.
Conclusion
The presented BVH-accelerated SBR pipeline materially advances the computational feasibility of high-frequency RCS analysis for electrically large metallic objects, balancing physical fidelity with algorithmic throughput. The approach is rigorously validated, exposes explicit tradeoffs between sampling density, numerical fidelity, and runtime, and exhibits strong scaling on state-of-the-art heterogeneous clusters. The work provides a reference channel for future development of CEM techniques targeting exascale resources, especially those that require tight coupling of parallel spatial acceleration, explicit path sampling control, and hardware-aware performance tuning.
Future directions include algorithmic integration of diffraction, polarization, and dielectric effects, as well as further optimizations in pre-launch filtering, directionally adaptive BVHs, and workload scheduling for complex multi-path interactions. This positions the approach as a scalable platform for advanced electromagnetic backscattering modeling in radar and sensing applications.

