- The paper proposes a focal adapter with TB-SSM that decouples spatial and temporal features to enhance action boundary detection and achieve higher mAP scores.
- It employs 2D depthwise convolutions for spatial cues and 1D convolutions with directional state dynamics for precise temporal modeling.
- Experimental results on THUMOS14, ActivityNet, and Charades demonstrate significant performance improvements over standard SSM and Transformer methods.
Efficient Spatial-Temporal Focal Adapter with SSM for Temporal Action Detection
Introduction and Motivation
Temporal Action Detection (TAD) is a central task in video understanding, requiring accurate identification and localization of action intervals within untrimmed videos. While convolutional and Transformer architectures have advanced this field, they encounter challenges in modeling long-range dependencies and face significant efficiency bottlenecks, such as feature redundancy and quadratic complexity in sequence length. State Space Models (SSMs), particularly those inspired by Mamba architecture, offer a promising alternative: they deliver linear scaling for long-term sequence modeling. However, their straightforward application can oversmooth feature representations, compromising boundary precision crucial for action localization.
This work addresses these limitations by proposing the Efficient Spatial-Temporal Focal Adapter (ESTF), which incorporates a novel Temporal Boundary-aware SSM (TB-SSM) for robust and fine-grained temporal feature modeling. The ESTF Adapter is integrated into pretrained video backbone layers, enabling efficient and parameter-light adaptation for video TAD.
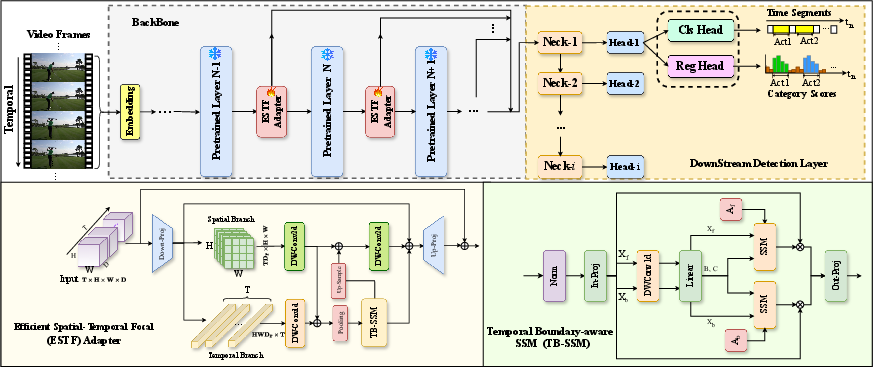
Figure 1: The ESTF Adapter framework utilizes dual spatial and temporal branches, with TB-SSM enabling directional state dynamics for improved temporal boundary regression.
Methodology
Overall Architecture
The proposed framework incorporates ESTF Adapters into selected layers of a frozen, pretrained video backbone. Each ESTF Adapter decouples spatial and temporal modeling into two branches:
- Spatial Branch: Utilizes 2D depthwise separable convolutions to extract localized spatial cues, followed by spatial downsampling to reduce feature redundancy.
- Temporal Branch: Applies 1D convolutions and the TB-SSM mechanism to model global, long-range temporal dependencies while maintaining sensitivity to action boundary asymmetries.
Spatial and temporal features are adaptively fused and projected back to the original channel dimensionality, achieving efficient joint modeling while constraining computational cost.
Temporal Boundary-aware SSM (TB-SSM)
The TB-SSM component adapts the Mamba SSM for temporal boundary detection by introducing direction-specific state transition matrices for forward and backward temporal scans. This architectural choice is specifically designed to address the asymmetric nature of action onsets and offsets. Forward and backward latent states are updated with independent transition matrices, and their outputs are concatenated and projected to produce the final temporal representation.
This selective state update mechanism provides a strong inductive bias favoring sharp and accurate boundary localization, directly addressing the oversmoothing encountered in prior SSM models.
Experimental Results
Comprehensive evaluation was conducted on three standard TAD benchmarks: THUMOS14, ActivityNet-1.3, and Charades. Results indicate significant improvements over prior SSM-based and Transformer-based methods. In particular:
- THUMOS14: ESTF-SSM achieves higher average mAP across all tIoU thresholds, with marked gains at high tIoU values, underscoring superior boundary regression.
- ActivityNet-1.3: Consistent improvements in mAP, reflecting strong generalization over diverse and long video sequences.
- Charades: Outperforms all baselines, especially at tight tIoU thresholds, demonstrating efficacy in complex, multi-activity environments.
Ablation studies confirm the complementary importance of both spatial and temporal branches, the explicit spatial-temporal feature fusion mechanism, and the unique boundary-aware dynamics of TB-SSM. Substituting TB-SSM with standard SSMs or Transformers yields notably degraded detection accuracy.

Figure 2: Qualitative comparison on THUMOS14 shows superior detection of action boundaries by ESTF-SSM compared to previous SSM-based methods.
Implications and Future Directions
The ESTF framework demonstrates that decoupled and lightweight spatial-temporal adaptation, coupled with boundary-sensitive SSMs, is effective for scalable TAD in resource-constrained settings. The strong empirical results suggest this paradigm can be extended to:
- Online action detection, where adaptive, low-latency processing is mandatory;
- Multi-modal video understanding, integrating textual or audio cues using similar adapter-based strategies;
- Transfer to other domains where temporal boundaries are critical (e.g., event segmentation in time-series data).
Theoretically, the approach provides evidence for the utility of direction-specific latent state dynamics within the SSM paradigm, opening new avenues for fine-grained temporal reasoning in sequence modeling tasks.
Conclusion
The introduction of the Efficient Spatial-Temporal Focal Adapter with TB-SSM sets a new standard for temporal action detection in long untrimmed videos. By leveraging parameter-efficient adapters, explicit spatial-temporal decoupling, and directional state-space modeling, the approach overcomes both the representational and computational limitations of previous architectures. The framework’s scalability and strong performance across diverse scenarios indicate substantial promise for broader adoption and cross-domain extensions.