- The paper presents a novel dataset that links explicit personality traits (via MBTI and BFI) to reader-based emotional appraisals over 3,111 curated events.
- It employs a rigorous multi-stage annotation and quality control process across diverse domains to capture systematic affective divergence.
- It reveals domain-specific emotion shifts and exposes the limitations of current LLMs in simulating fine-grained, trait-conditioned emotional responses.
Persona-E2: Human-Grounded Data for Personality-Shaped Emotional Event Response
Motivation and Context
Emotion elicitation from text is typically anchored in static, text-centric sentiment analysis, privileging the writer's perspective and collapsing reader diversity into consensus labels. This paradigm obscures systematic inter-individual appraisal variance—driven by stable personality traits—critical for modeling fine-grained empathetic response, affective personalization, and downstream tasks such as mental health support. Role-playing LLM research has attempted to simulate persona-conditioned affective shifts, yet remains restricted by superficial "personality illusion," frequently regressing to stereotyped behaviors without true cognitive grounding. The absence of large-scale, human-grounded data linking explicit personality traits to reader-based emotional reactions remains the major bottleneck.
Dataset Construction and Protocol
Persona-E2 addresses this gap by assembling a reader-centric dataset of 3,111 events—curated from news, social media, and life narrative domains—each paired with dense (36-fold) emotion annotations from uniquely profiled annotators. Personality profiles are measured using both the MBTI and the Big Five Inventory (BFI), ensuring both categorical and continuous trait coverage. The annotation prompt elicits authentic, non-role-played, first-person emotional appraisals, using a closed set of Ekman emotions (anger, disgust, fear, joy, sadness, surprise, neutral).
To guarantee data quality, a multi-stage process is implemented: NSFW filtration, LLM-based multi-dimensional psychological scoring (incorporating arousal, trait variance, implicitness, and source relevance), and expert audit for factual, linguistic, and bias integrity. This pipeline yields stimuli with maximal potential for personality-driven divergence.
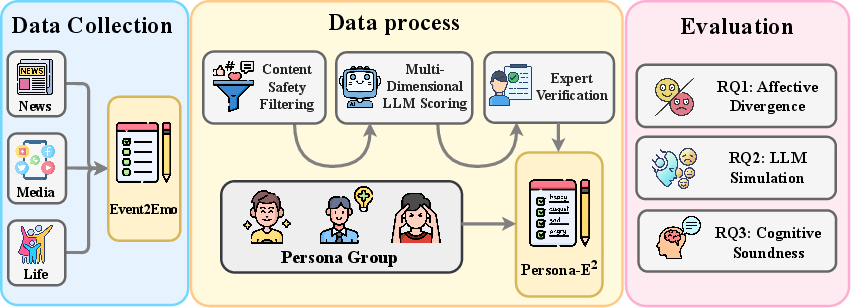
Figure 1: Overview of the Persona-E2 annotation and data processing pipeline integrating multi-domain events and trait-grounded reader annotation.
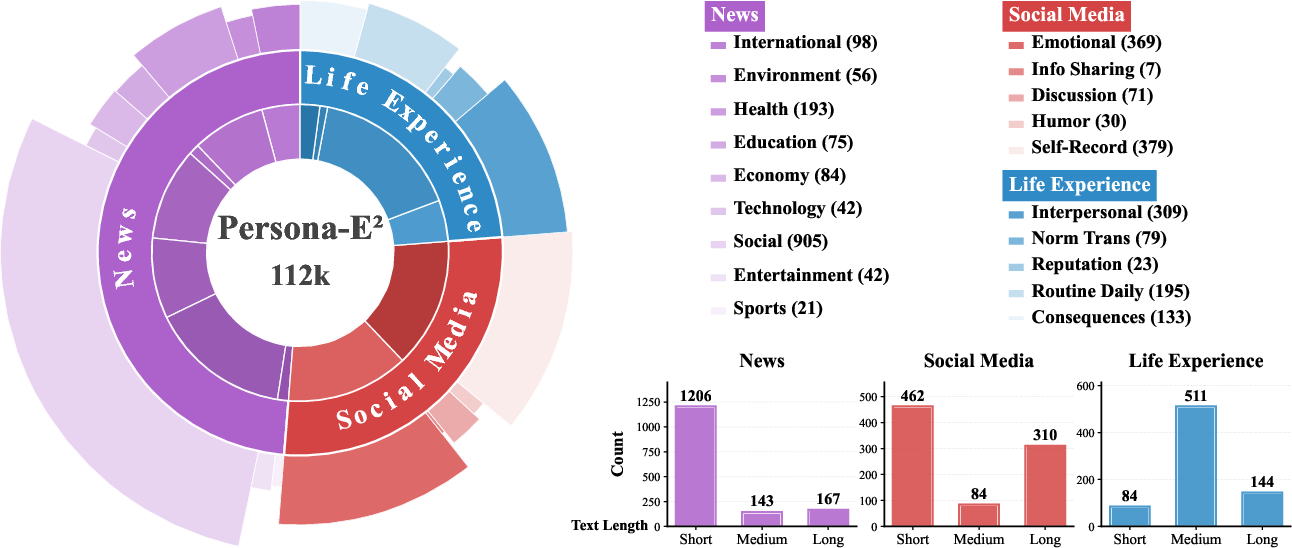
Figure 2: Hierarchical composition of the Persona-E2 dataset, showing source, domain, and semantic subcategory structure.
Dataset Analysis: Affective Divergence and Trait Structure
A core finding is the domain- and trait-dependence of affective appraisal. Across news, social media, and life narrative domains, systematic shifts emerge between writer-labeled, general-reader-majority, and persona-conditioned emotion distributions. Notably, social media exhibits an 81.6% neutral-to-negative and 59.35% positive-to-negative transition from writer to reader—a marked negativity bias indicative of hostile ambiguity filling ("Emotional Black Hole"). Conversely, life narratives induce a 43.28% negative-to-positive shift, signaling a psychological immune response—optimism predominates empathetic projection.
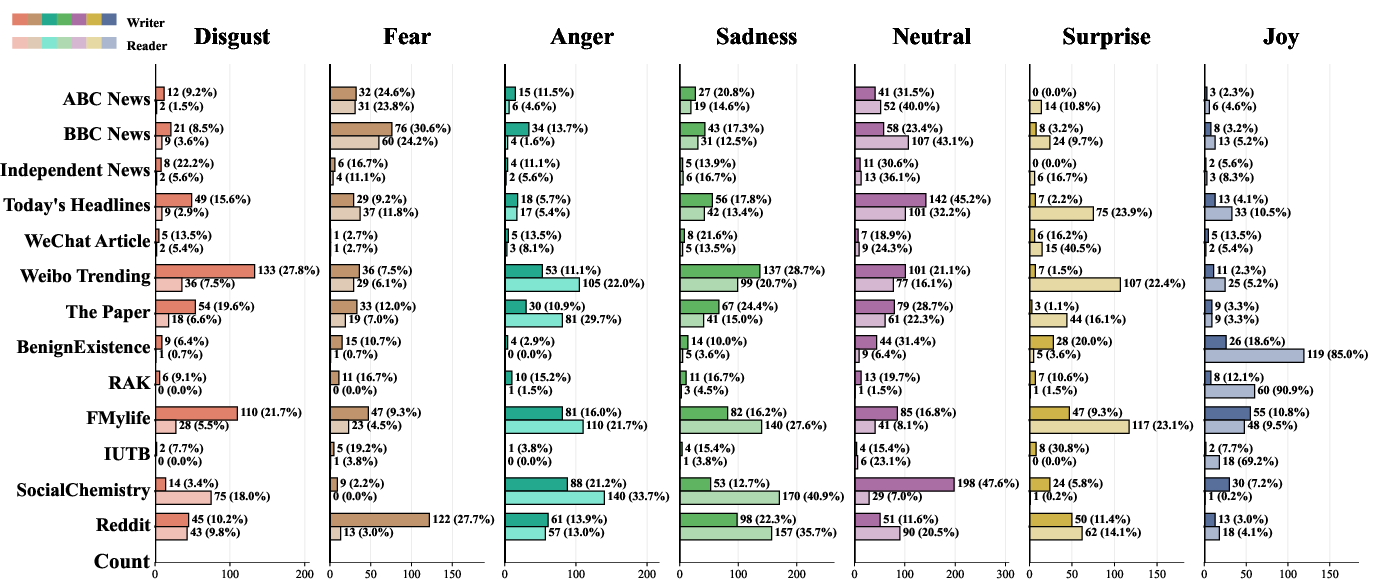
Figure 3: Distributional comparison of writer and reader emotion labels across news and social domains, exposing systematic divergence and domain bias.
Trait-based clustering reveals robust agreement gaps (PAG) between in-group (trait-homogeneous) and out-group annotator subsets, with BFI clusters achieving up to +25.96% Top-1 agreement gain over global baselines. In particular, high Conscientiousness/Openness clusters evidence convergent appraisal logic, and neuroticism/agreeableness axes modulate negativity/sensitivity transitions. This provides empirical support for the structured—not simply random—nature of cross-person affective disagreement.
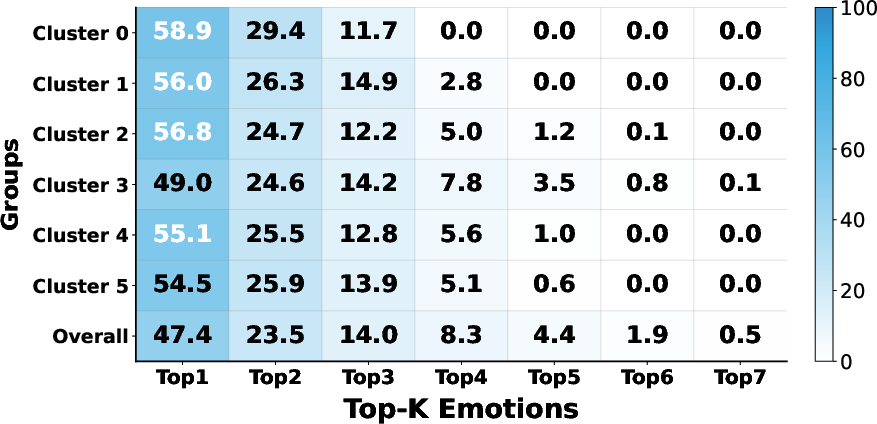
Figure 4: Top-K emotion distribution heatmap across BFI clusters, illustrating trait-structured consensus and divergence patterns in appraisal.
Evaluation: LLM Persona Simulation and Cognitive Soundness
Experiments with state-of-the-art LLMs (#1{GPT-5.1}, #1{Llama-3-8B}, #1{Gemma-3-12B}, et al.) assess their ability to simulate persona-driven emotion labeling under three prompting paradigms: general, persona-profiled (BFI vectors), and CoT-augmented persona. On a subset emphasizing high group-consensus but high inter-group-divergence ("Subjective Divergence Subset," SDS), strong evidence emerges that existing models are limited to capturing broad affective neighborhoods. Top-1 accuracy plateaus at ∼25%, with a performance surge to ∼45% at Top-2—demonstrating semantic proximity but poor granularity in trait-driven shifts. The impact of persona prompting is positive in larger models, but negative in smaller ones, indicating attention/contextual bottlenecks with complex conditioning.
Accuracy in the social media domain is especially deficient (e.g., #1{GPT-5.1}: 18.2–27.3%), highlighting a persistent cyber-social gap in LLM affective simulation capacity. The findings strongly suggest that current affective pretraining regimes and model architectures are insufficient for capturing nuanced, personality-driven reader appraisals, especially in less structured, ambiguous domains.
Rationale Generation and Personality Representation
Assessment of LLM-generated rationales by human judges (metrics: persona consistency, plausibility, emotion specificity) further supports this conclusion. BFI profiles consistently outperform MBTI and baseline (no-personality) prompts in producing rationales that align with human cognitive and trait-grounded patterns, with win rates up to 78.8% (#1{GPT-5.1}, BFI, persona consistency). MBTI prompts, despite surface-level personality cues, often lag in plausibility and emotional specificity, confirming theoretical arguments regarding the inadequacy of binary and coarse typologies for fine-grained cognitive emulation.
Larger parameter models (e.g., #1{Gemma-3-12B}) show greater robustness and higher cognitive soundness scores, implicating scale as a requirement for internally-consistent affective reasoning chains in personality-shaped contexts.
Implications and Future Directions
Persona-E2 provides a comprehensive, multi-domain, high-density, trait-anchored dataset, enabling rigorous verification and future pretraining of affect-induction models beyond writer-centric and consensus-labeled paradigms. The explicit linking of appraisals to continuous trait vectors unlocks research on the causal interplay between stable personality structure and context-driven emotion. These results cast doubt on the sufficiency of role-playing prompts and categorical typologies (MBTI) within current LLM simulation paradigms, and emphasize the importance of explicit, trait-dense grounding (BFI, IPIP). There is a marked need for targeted human feedback, cyber-social domain adaptation, and capacity scaling to reduce personality illusion and achieve genuine trait-aligned emotion simulation.
Potential extensions include integrating dynamic or context-specific traits, expansion to broader demographic and linguistic strata, and fine-grained, dimensional emotion models (e.g., valence-arousal-dominance). Applications in AI mental health, personalized tutoring, and autonomous assistants will benefit directly from robust simulation of nuanced, trait-driven affective responses and rationales.
Conclusion
Persona-E2 conclusively demonstrates that inter-individual emotion elicitation is systematically structured by personality, with both theoretical and practical implications for personalized affective computing. The dataset establishes empirically that current LLMs, despite progress, fail to consistently simulate fine-grained, trait-conditioned emotional appraisals, especially in cyber-social contexts and under cognitive plausible rationales. The superiority of BFI-driven modeling over MBTI offers clear direction for future research and deployment in trait-conditioned NLU and affective AI. The release of Persona-E2 provides an essential benchmark and springboard for next-generation research in emotion–personality interplay and human-grounded AI affect modeling.
Figure 5: The annotation platform supporting trait-conditioned multi-label emotion acquisition, real-time visualization, and annotation monitoring.