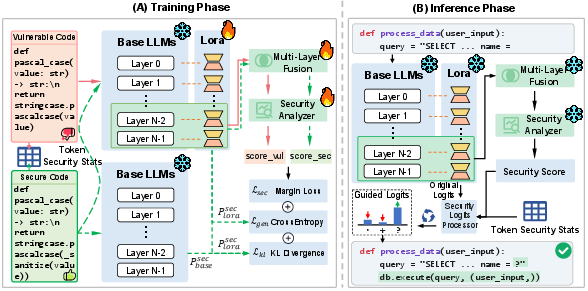
- The paper introduces DeepGuard, which aggregates multi-layer semantic cues to overcome the final-layer bottleneck in secure code generation.
- It employs an attention-based aggregator and guided inference strategy to improve vulnerability discrimination and maintain functional correctness.
- Empirical results show an average 11.9% security gain across models and robust generalization to unseen vulnerability types with minimal overhead.
DeepGuard: Secure Code Generation via Multi-Layer Semantic Aggregation
Introduction and Motivation
The adoption of LLMs for code generation, such as those underpinning systems like GitHub Copilot, introduces significant software security challenges. LLMs can propagate insecure coding patterns present in training data, thereby automating vulnerability introduction into production code. A key limitation of most extant security-hardening approaches for LLMs lies in their reliance on final-layer-only supervision. This incurs a final-layer bottleneck: critical vulnerability-discriminative signals, which are hierarchically distributed across transformer layers, become less accessible for training objectives when the model’s output is optimized for next-token prediction rather than for fine-grained security detection.
Layer-wise probing conducted by the authors demonstrates that vulnerability signals tend to peak in intermediate-to-upper layers and attenuate near the output—evidence supporting the inadequacy of final-layer-only strategies.
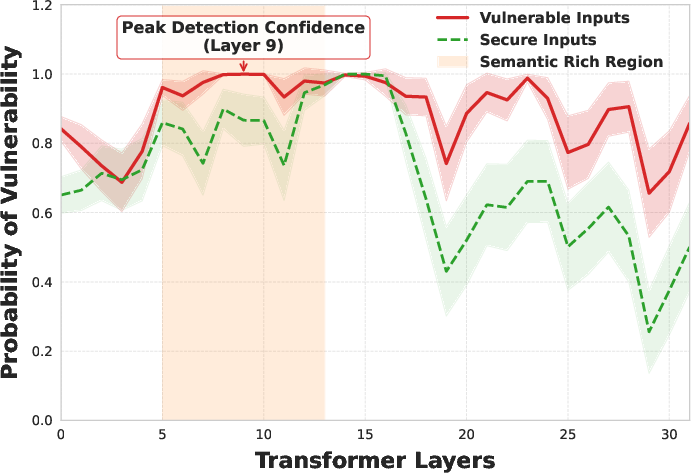
Figure 1: Layer-wise diagnostic evidence on Seed-Coder-8B. Linear probing indicates vulnerability signal strength peaks in intermediate-to-upper layers and attenuates toward the final layers.
DeepGuard: Architecture and Methodology
DeepGuard addresses the final-layer bottleneck by explicitly aggregating multi-layer semantic information and incorporating it into a multi-objective adaptation and lightweight inference-time steering framework. The core technical contribution is the use of an attention-based multi-layer aggregator to dynamically fuse upper-layer representations, exploiting the distributed nature of vulnerability cues.
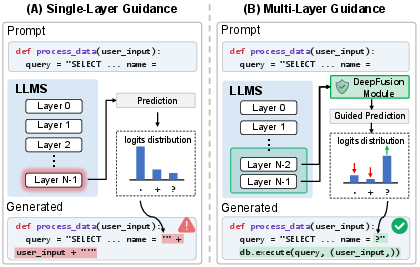
Figure 2: Comparison of security guidance paradigms. Unlike single-layer methods that suffer from final-layer signal degradation, DeepGuard aggregates cues across upper layers.
The learning process is comprised of the following components:
Empirical Results and Ablation
DeepGuard was evaluated on five code LLMs (Qwen2.5-Coder 3B/7B, DeepSeek-Coder 1.3B/6.7B, and Seed-Coder 8B) across established benchmarks (2604.09089). Key evaluation metrics include pass@1, sec-pass@1 (fraction of generations that are both secure and functionally correct), and sec@1_{pass} (conditional security among correct generations).
Main Findings:
Ablation Studies:
- Removing the contrastive security objective yields the largest degradation in secure code generation, validating the necessity of explicit security supervision.
- Disabling inference-time guidance or using only final-layer aggregation significantly reduces security alignment, confirming the effectiveness of the multi-layer aggregation and lightweight biasing mechanism.
Mechanistic Interpretability
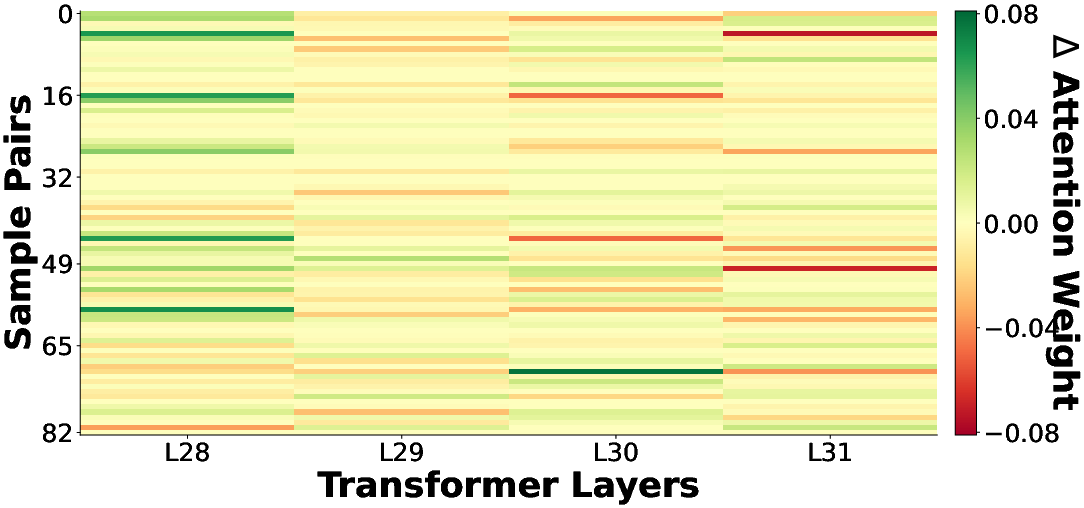
Mechanistic analysis (Figure 5) on classic vulnerabilities such as SQL injection demonstrates that DeepGuard’s attention aggregator places the strongest weight on layers and token positions corresponding to security-escalating operations (e.g., string concatenation in SQL query construction). The analyzer outputs sharp drops in security scores for high-risk token spans while correctly maintaining high scores elsewhere, evidencing precise vulnerability localization capabilities.
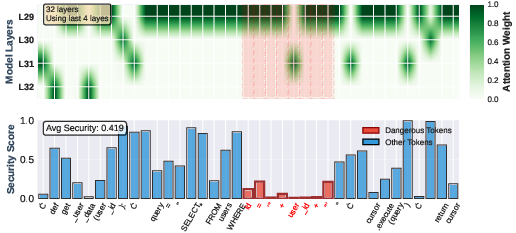
Figure 5: Visualization of DeepGuard processing an SQL Injection vulnerability. Strong attention to intermediate layers and targeted security score drops align with dangerous tokens.
Efficiency
The guided inference mechanism requires only a single forward pass per prompt for bias computation, incurring negligible (sub-2.1%) computational overhead across evaluated models. This stands in contrast to substantial latency introduced by post-hoc rescoring or co-decoding methods.
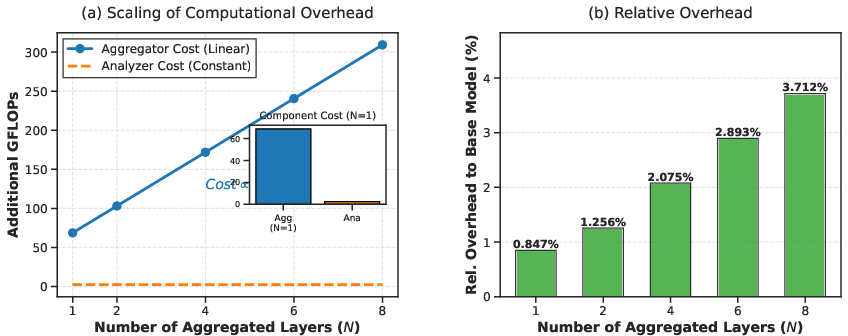
Figure 6: Aggregation cost has linear scaling in N but with negligible relative overhead using N=4, enabling efficient deployment.
Limitations and Implications
DeepGuard’s primary constraint is its reliance on internal model states, restricting applicability to open-weight or white-box LLMs; extension to black-box or API-only environments remains an open problem. The method also depends on paired vulnerable/secure supervision, which may be labor-intensive at scale.
Practically, DeepGuard enables the deployment of code LLMs with enhanced security postures and minimal overhead, applicable in CI/CD pipelines or real-time IDE assistance. Theoretically, the work demonstrates the necessity of moving beyond pointwise, final-layer methodologies for nuanced, distributed phenomena like software vulnerabilities. Future directions include adaptive layer selection, extension to multi-file and multi-language contexts, and minimizing supervision requirements via semi-supervised or self-supervised correspondence mining.
Conclusion
DeepGuard introduces a robust, multi-layer aggregation-based framework for improving secure code generation in LLMs. Its technical contributions empirically and mechanistically validate the significance of harnessing hierarchically distributed internal representations, setting a new direction for research on reliable and safe machine programming. The synergy of adaptation and inference-time steering in DeepGuard offers generalizable insights for enhancing security (and other distributed-signal properties) in generative LLMs.
Reference:
"DeepGuard: Secure Code Generation via Multi-Layer Semantic Aggregation" (2604.09089)