- The paper introduces a novel feature-label modal alignment strategy that denoises spurious labels using low-rank orthogonal decomposition.
- It employs global and local alignment to project features and pseudo-labels into a shared subspace, enhancing discriminability.
- Empirical results on 13 datasets show that PML-MA outperforms state-of-the-art methods in ranking and average precision metrics.
Feature-Label Modal Alignment for Robust Partial Multi-Label Learning
Problem Setting and Methodological Motivation
Partial multi-label learning (PML) extends classic multi-label learning by associating each instance with a candidate set comprising both true and spurious labels, resulting from annotation errors and semantic ambiguities. Such scenarios are exemplified in tasks like image recognition, where, for instance, a scene’s candidate label set may include both relevant ("lake," "cloud," "tree") and irrelevant ("mountain," "bird") tags. The primary challenge in PML is to filter noisy labels and recover the underlying true multi-label assignments. Prior approaches ranging from label propagation to matrix decomposition, while effective in standard settings, often neglect the intricate couplings between the feature and label manifolds, leading to poor disambiguation in the presence of complex noise.
The proposed framework, Feature-Label Modal Alignment for Partial Multi-Label Learning (PML-MA), addresses this by explicitly treating features and labels as coupled modalities to enforce their consistency. The method systematically denoises the candidate label sets, aligns feature and pseudo-label representations globally and locally, and enhances discriminability via prototype-guided multi-peak learning.
Figure 1: An example of partial multi-label learning. The candidate label set contains both ground-truth labels (in black: "lake," "cloud," "sun," and "tree") and noisy labels (in red: "mountain," "sea," "grass," and "bird").
Core Framework and Algorithmic Details
Low-Rank Orthogonal Decomposition for Pseudo-Labels
PML-MA first targets the label noise by decomposing the candidate label matrix Y into a product RQ⊤ where Q is an orthogonal matrix and R encodes soft pseudo-labels. This orthogonal decomposition offers three advantages: (1) it decorrelates label noise, (2) stabilizes reconstruction compared to sparse decompositions, and (3) yields numerically stable updates. The decomposition is regularized via a nuclear norm on R, enforcing global correlation extraction but restricting the pseudo-labels to be consistent with the observable candidate labels.
Global and Local Modal Alignment
Pseudo-labels filtered by orthogonal decomposition are then projected alongside features into a common m-dimensional subspace using projection matrices P1 and P2. The optimization criterion includes:
- Global alignment: Minimizes the Frobenius norm ∥XP1−RP2∥F2, enforcing global proximity in the shared subspace.
- Local alignment: Regularizes local neighborhoods using a similarity matrix S, ensuring that local feature-label neighborhoods are preserved.
This formulation generalizes classic subspace methods like CCA/PLS by making RQ⊤0 a latent variable under cross-modal manifold constraints, jointly optimizing projections and pseudo-labels for cross-modality consistency.
Multi-Peak Prototype Learning
Contrary to single-peak clustering assumptions, multi-label PML instances generally correspond to multiple label prototypes. PML-MA models an instance’s soft assignment to multiple class prototypes, using pseudo-label weights as continuous soft memberships. The objective aligns each instance’s feature representation scaled by total label intensity to a convex combination of the corresponding class prototypes, reinforcing semantic consistency.
Unified Objective and Optimization
All tasks—pseudo-label denoising, cross-modal alignment, and prototype refinement—are integrated into a single objective comprising trade-off parameters for low-rank (RQ⊤1), local alignment (RQ⊤2), prototype guidance (RQ⊤3), and classifier complexity (RQ⊤4). An alternating minimization algorithm with closed-form updates (using Sylvester equations and singular value thresholding) enables efficient convergence.
Empirical Analysis
Quantitative Results and Statistical Significance
PML-MA is systematically evaluated on 13 datasets (real-world and synthetic) against eight state-of-the-art PML baselines across five established metrics (Hamming, Ranking, One-error, Coverage, Average precision). The results demonstrate that PML-MA achieves the best or runner-up performance in 88.7% of metric-dataset pairs, and statistical tests (Wilcoxon, Friedman) indicate that its improvements are significant at RQ⊤5.
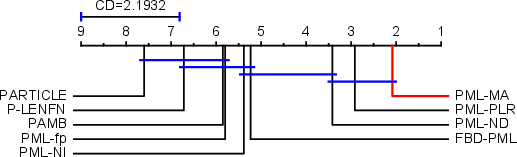
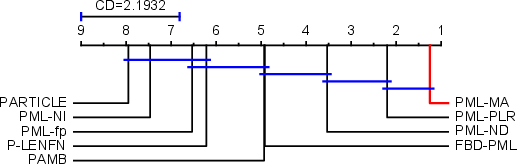
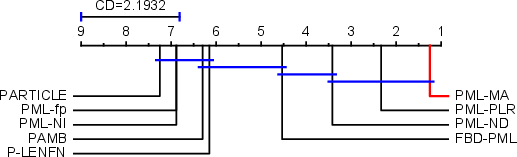
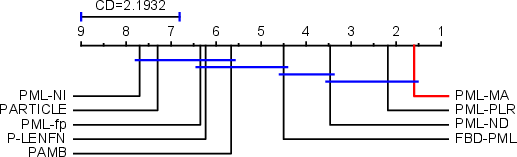
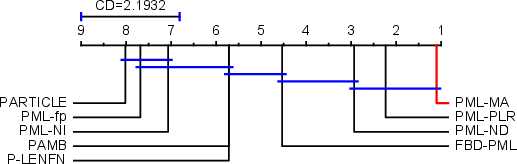
Figure 2: Results of PML-MA against other approaches with the Nemenyi test (CD = 2.1934 at 0.05 significance level).
PML-MA consistently outperforms SOTA competitors (e.g., PML-PLR, PML-ND, FBD-PML), especially in ranking-based and average precision metrics. It maintains stable accuracy even with severe label noise, while alternatives like PARTIAL and PML-NI degrade.
Ablation and Decomposition Analysis
Component ablations confirm the necessity of each module. Removing global-local alignment or prototype components sharply degrades average precision. Comparative analyses between the proposed low-rank orthogonal decomposition and classic low-rank sparse decomposition further show the superior robustness of the former in high-noise regimes.
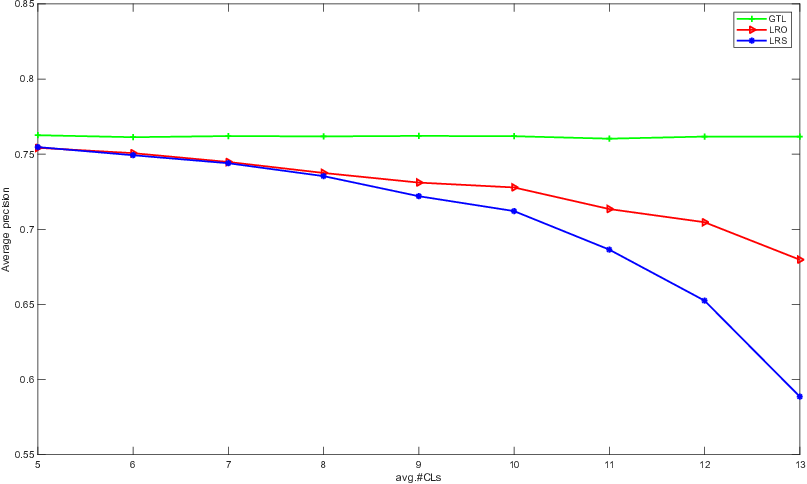
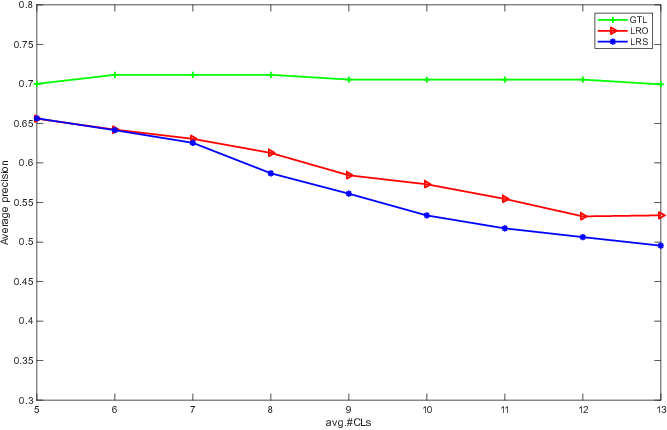
Figure 3: Comparative experiment of low rank orthogonal decomposition and low rank sparse decomposition on yeast and reference datasets.
Parameter and Convergence Analysis
Parameter sweeps demonstrate that all trade-off parameters possess clear optimal ranges and the method is not excessively sensitive. Convergence plots confirm rapid stabilization of the loss in under 10 iterations on all datasets.
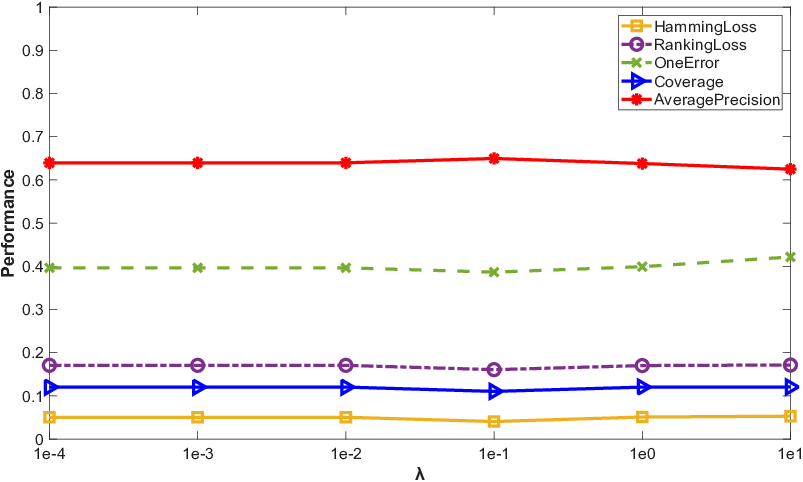
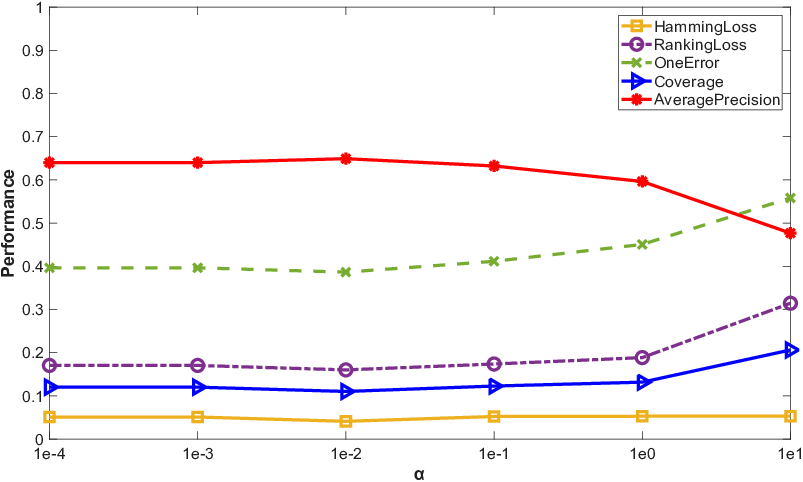
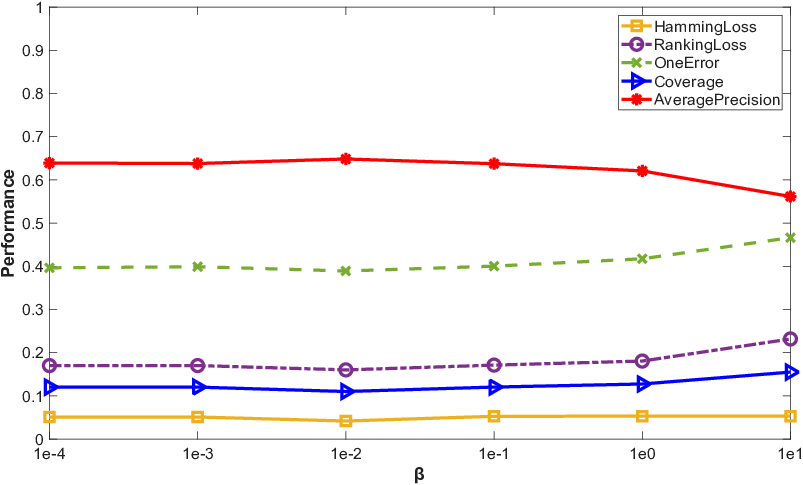
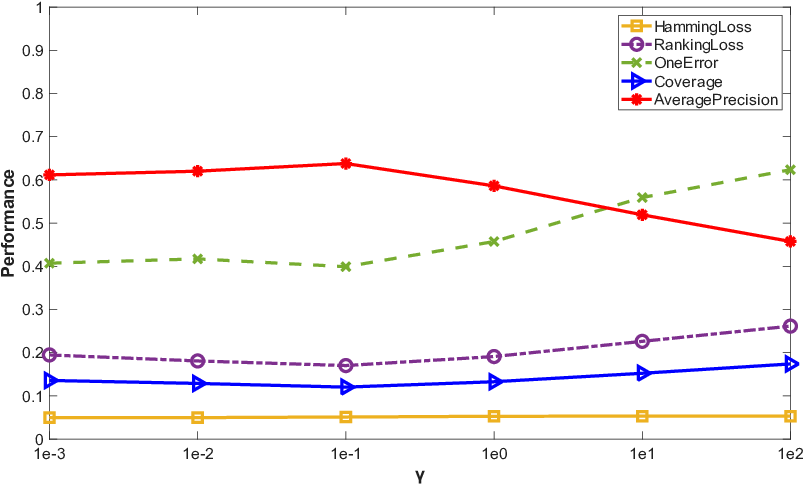
Figure 4: Results of PML-MA with varying values of trade-off parameters on birds dataset.
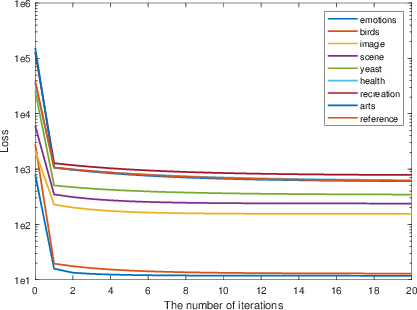
Figure 5: The convergence curves of PML-MA on the synthetic datasets.
Theoretical and Practical Implications
Theoretically, PML-MA’s complete objective and update rules are rigorously analyzed for consistency, complexity, and generalization, including a formal Rademacher complexity bound and proof that the pseudo-label matrix RQ⊤6 closely approximates the true labels under mild noise assumptions. This cross-modal alignment mechanism distinguishes PML-MA from both prior PML and subspace learning methods.
Practically, the method’s explicit modeling of feature-label correlation, robust label denoising, and multi-peak prototype learning collectively advance the reliable deployment of machine learning systems in annotation-scarce or error-prone environments. The modular objective and alternating optimization make it readily extensible.
Limitations and Future Directions
Despite strong empirical and theoretical performance, PML-MA currently requires grid-search parameter tuning and is limited to linear projections and single-modality features. Future work should explore:
- Adaptive parameter selection mechanisms based on noise levels or data statistics
- Nonlinear (deep) generalizations for enhanced representation power
- Multi-modal feature integration (e.g., vision, text, audio)
- Scalability optimizations via mini-batching and approximate SVDs
Conclusion
PML-MA establishes a benchmark for robust, structure-aware partial multi-label learning by integrating orthogonal label denoising, cross-modal alignment, and prototype modeling. Its systematic advances in both noise robustness and discriminability are demonstrated quantitatively and supported with solid theoretical analysis. Future extensions—especially toward deep and multimodal settings—could further enhance both empirical performance and domain applicability.
References
See "Feature-Label Modal Alignment for Robust Partial Multi-Label Learning" (2604.09064) for full methodological, theoretical, and experimental details.