- The paper introduces a comprehensive dataset (CAD 100K) that supports classification, detection, and segmentation tasks for car anomalies.
- It employs a hierarchical annotation scheme across seven vehicular domains to enable fine-grained analysis and effective domain adaptation.
- The study demonstrates adaptive multi-task learning using the Convergence Balancer to achieve robust performance on real-world data.
Motivation and Overview
Visual anomaly detection in the automotive industry necessitates robust multi-task learning (MTL) frameworks capable of addressing highly diverse real-world manufacturing defects. Existing benchmarks are inherently limited—either single-task, biased toward exterior damage, or lacking comprehensive hierarchical annotation—thereby impeding the extension and generalization necessary for practical deployment in smart manufacturing. "CAD 100K: A Comprehensive Multi-Task Dataset for Car Related Visual Anomaly Detection" (2604.09023) systematically addresses these limitations by introducing CAD 100K, a benchmark containing 100,000+ images, organized over seven vehicular domains and annotated for three orthogonal tasks: classification, object detection, and semantic segmentation.
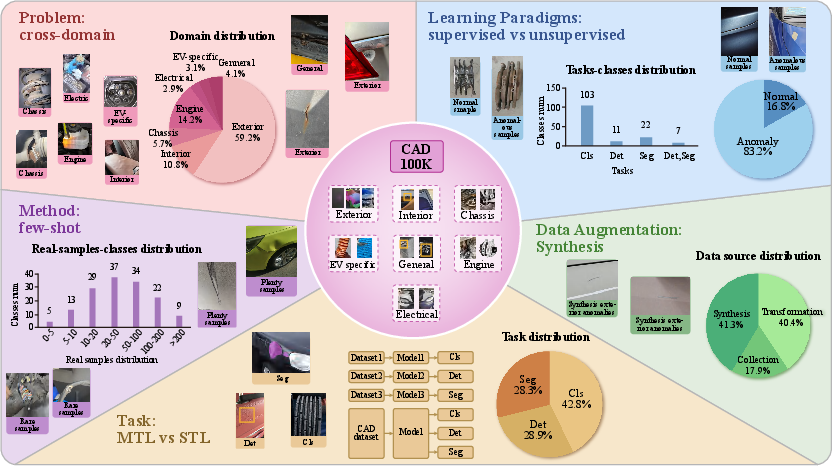
Figure 1: CAD 100K provides a large-scale, multi-domain, multi-task dataset with synthesized data augmentation and support for both supervised and unsupervised learning.
Dataset Structure and Hierarchical Annotation
CAD 100K is uniquely structured to ensure semantic consistency and extensibility, leveraging a three-level domain–system–part hierarchy. This allows for fine-grained and scalable anomaly analysis while maintaining annotation compatibility across tasks and supporting domain adaptation research. The dataset spans seven key domains—Exterior, Interior, Chassis, Engine Bay, Electrical, EV-specific, and General—covering 23 vehicle systems and 78 part categories, with each instance annotated for its anomaly type and the associated vision tasks.
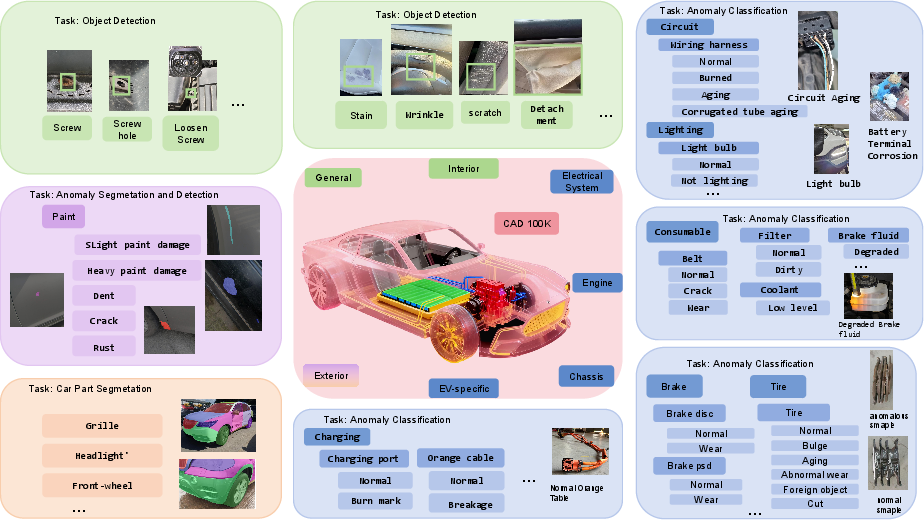
Figure 2: The hierarchical design of CAD 100K supports broad semantic coverage across domains, systems, parts, and anomaly types.
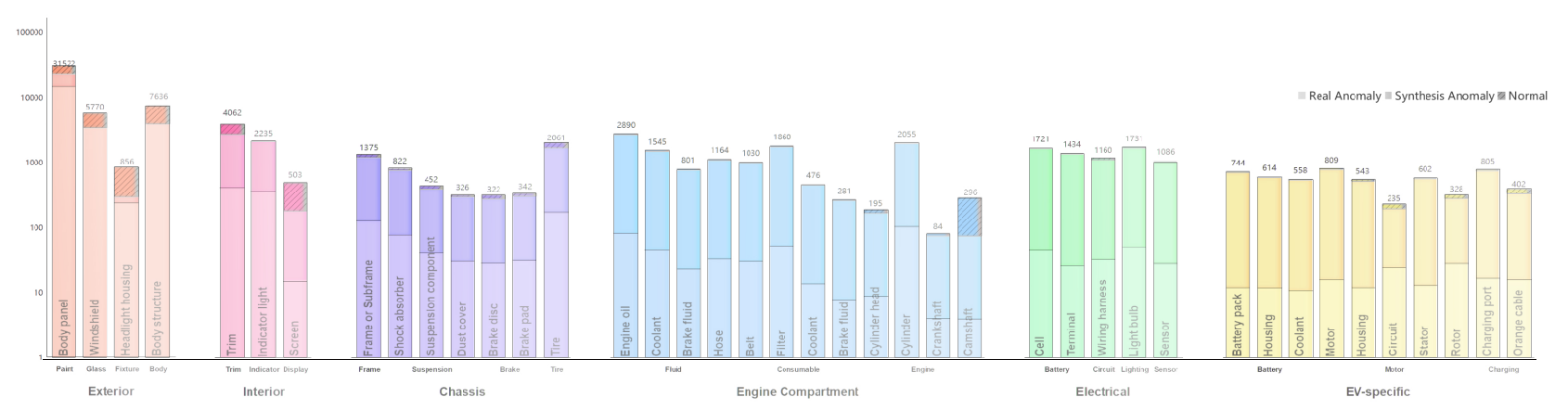
Figure 3: Diverse data composition in CAD 100K, with variability in domain coverage, image resolution, and a substantial proportion of synthetic samples to address long-tail and few-shot requirements.
This hierarchical organization mirrors real-world failures and visually observable defect rates—e.g., an exterior domain with higher anomaly frequency due to exposure, and an EV-specific domain for forward-compatible extension. Visual clarity and annotation feasibility also dictate the allocation of tasks per domain; for instance, segmentation is prioritized in the highly visible exterior, while classification is emphasized in visually complex or occluded domains.
Data Acquisition: Real, Synthetic, and Open-Source Integration
The dataset is constructed via a combination of controlled real-world capture, open-source dataset transformation, and an advanced generative diffusion-based pipeline for synthetic sample generation. Real images are acquired from service and assembly facilities, extensively annotated for fine localization. Open-source contributions are normalized through label re-mapping for hierarchical alignment, while generative models synthesize rare or subtle defects—expanding coverage of hard cases, facilitating robust few-shot learning, and balancing the class distribution. Automated and expert validation solidifies dataset integrity for rigorous benchmarking.
Task Diversity and Subsets
CAD 100K supports three primary tasks, each with designated subsets:
- Detection and segmentation: The exterior domain subset features bounding box and pixel-level mask annotations on a wide spectrum of visual damage classes.

Figure 4: The exterior domain supports dense detection and segmentation with high annotation granularity.
- Detection: Interior and general (cross-system) subsets focus on localization of occluded, diverse, or complex defects without pixel-level masks.
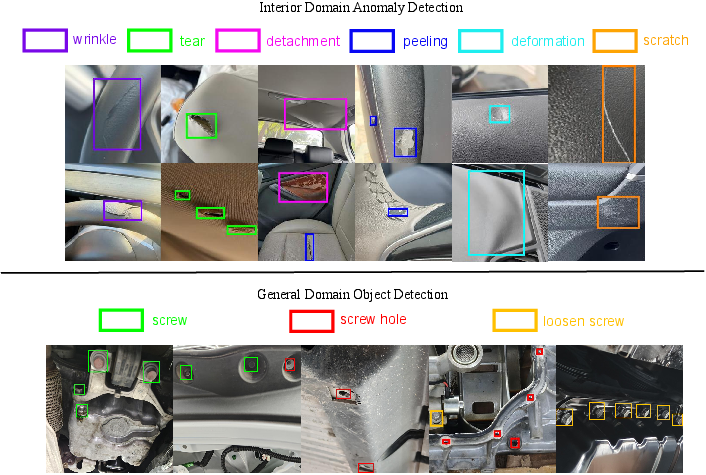
Figure 5: Diverse interior and cross-system anomaly detection examples indicative of real-world complexity.
- Classification: Specialized subsets for chassis, engine, electrical, and EV-specific domains enable anomaly type identification and normal/anomalous discrimination.
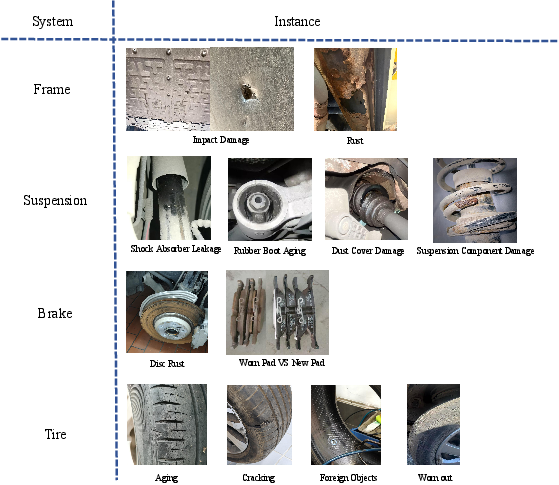
Figure 6: Chassis domain subset with labeled anomalies such as suspension and brake faults.

Figure 7: Engine domain subset encompassing fluids and mechanical components.

Figure 8: Electrical domain, including wiring harnesses and battery systems.

Figure 9: EV-specific domain, extending to high-voltage and charging-related anomalies.
This granularity supports hierarchical evaluation, domain adaptation, and the exploration of open-set and few-shot anomaly detection paradigms. For instance, the inclusion of rare part-level anomalies enables benchmarking data-efficient methods.
Baseline Methodology: Multi-Task Learning with Adaptive Task Scheduling
To facilitate cross-task comparison and set a strong reference, the authors present a shared-backbone, multi-head architecture baseline, supporting both ConvNeXt (CNN) and DINOv3 (ViT) encoders. Each head addresses either classification, detection, or segmentation, with task-specific decoders for efficient adaptation to resolution variability and complexity.
A critical methodological contribution is the Convergence Balancer (CoBa): a dynamic task scheduler and loss weight allocator that leverages convergence rate metrics to prioritize underperforming or harder tasks during training. By modulating both gradient flow and data sampling distribution in response to task-specific convergence scores, the adaptive strategy addresses negative transfer and resource allocation imbalance—crucial in settings with significant domain and task heterogeneity.
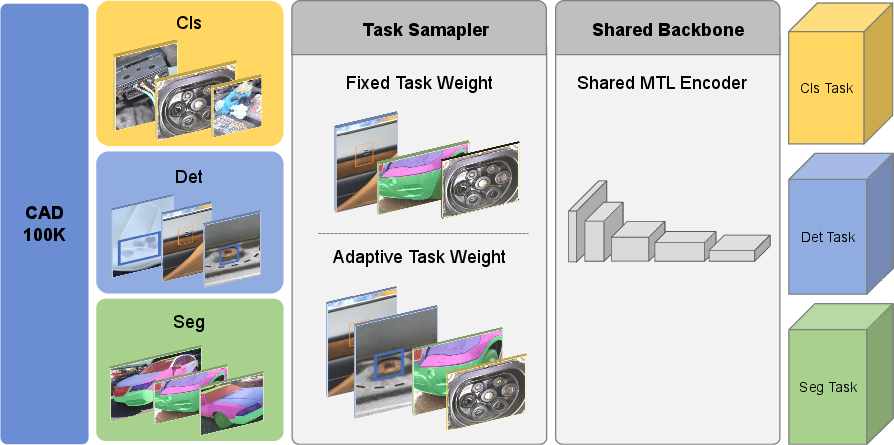
Figure 10: The multi-task learning baseline leverages a shared visual encoder and adaptive multi-head configuration for all car-related anomaly tasks.
Experimental Analysis
Empirical studies compare single-task learning (STL), static MTL, and adaptive MTL approaches with both transformer and CNN backbones on public benchmarks and the new dataset. Several patterns emerge:
- Classification performance saturates (accuracy >98% in most settings), highlighting the inherent simplicity of this subtask relative to detection and segmentation.
- Multi-task learning induces minor to moderate performance tradeoffs—notably, naive MTL degrades segmentation and detection more in transformer settings (e.g., DINOv3), whereas adaptive MTL with CoBa sometimes recovers or slightly outperforms base MTL in CNN architectures.
- Backbone-dependent effects: ConvNeXt demonstrates more stable multi-task behavior and adaptive gains, while ViT is more sensitive to inter-task interference, reflecting differences in how architectures represent and share visual features.
Evaluation on the CAD 100K dataset demonstrates that adaptive MTL maintains robust performance in real-world scenarios, where annotation ambiguity, lighting variability, and domain imbalance are more pronounced.
Practical and Theoretical Implications
The CAD 100K benchmark establishes a rigorous, extensible platform for the automotive anomaly detection community. It enables:
- Standardized MTL evaluation—critical for scalable deployment in manufacturing, reducing dependence on task-fragmented STL models.
- Benchmarking of advanced task coordination strategies, such as gradient surgery, dynamic weighting, and hierarchical loss composition, under realistic data conditions.
- Incentivizing research into few-shot, open-set, and data-efficient anomaly detection using robust synthetic augmentation.
- Facilitating transfer learning studies across domains (e.g., ICE vs. EV components) and anomaly types, directly linking performance to practical industrial relevance.
The demonstrated importance of backbone and scheduler co-design underscores the need for further investigation into architecture-aware optimization and more nuanced multi-task synergy regularization. The adaptation of advanced foundation and pre-trained visual-LLMs to this hierarchical, high-diversity setting poses a compelling future research direction.
Conclusion
CAD 100K is a comprehensive, ambitious benchmark for unified car-related anomaly detection, characterized by its hierarchical organization, cross-domain extensibility, and compatibility with modern MTL methods. The dataset and its baseline facilitate systematic study of task interactions under real-world constraints, supporting ongoing progress toward efficient, versatile, and resilient visual inspection systems in the automotive industry.