- The paper introduces an active recognition framework that dynamically acquires local visual evidence through tool-augmented reasoning.
- It employs a hierarchical pipeline with FACS-based AU analysis and a novel RL algorithm (UC-GRPO) to optimize emotion detection.
- Experimental results show state-of-the-art performance on multiple FER benchmarks, particularly for subtle and ambiguous expressions.
Agentic Facial Expression Recognition via ActFER
Introduction and Motivation
Facial Expression Recognition (FER) has historically been constrained by passive paradigms, wherein models rely on externally preprocessed inputs and fixed, single-pass analysis pipelines. Recent advances in Multimodal LLMs (MLLMs) have enabled more interpretability and multimodal reasoning, yet most MLLM-based FER systems remain limited—they treat visual evidence as immutable, neglecting the critical need for active evidence acquisition, particularly in dynamic and ambiguous real-world conditions. "ActFER: Agentic Facial Expression Recognition via Active Tool-Augmented Visual Reasoning" (2604.08990) introduces a framework designed to overcome these deficiencies by reformulating FER as an active, agentic process: the model not only reasons over visual input but actively decides when and where to acquire additional local evidence through perceptual tools, thereby leveraging both agentic RL concepts and affective computing requirements.
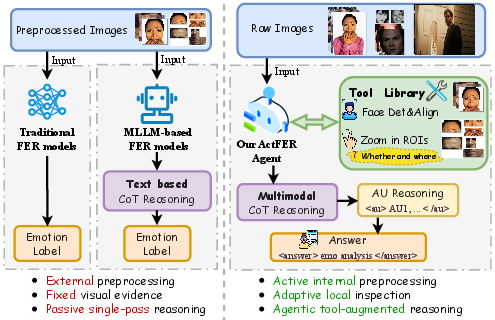
Figure 1: Comparison of passive FER paradigms with ActFER’s tool-augmented, agentic inspection loop.
ActFER System Architecture
ActFER features a hierarchical, visually-grounded reasoning pipeline that incorporates perceptual tool invocation, FACS-based AU analysis, and multimodal Chain-of-Thought (CoT) reasoning, optimized using a specialized RL algorithm. The model starts from raw facial images, dynamically invokes a suite of visual tools (face detection/alignment, adaptive ROI zoom-in), and builds a region-by-region evidence chain grounded in Action Unit (AU) detection before predicting emotions.
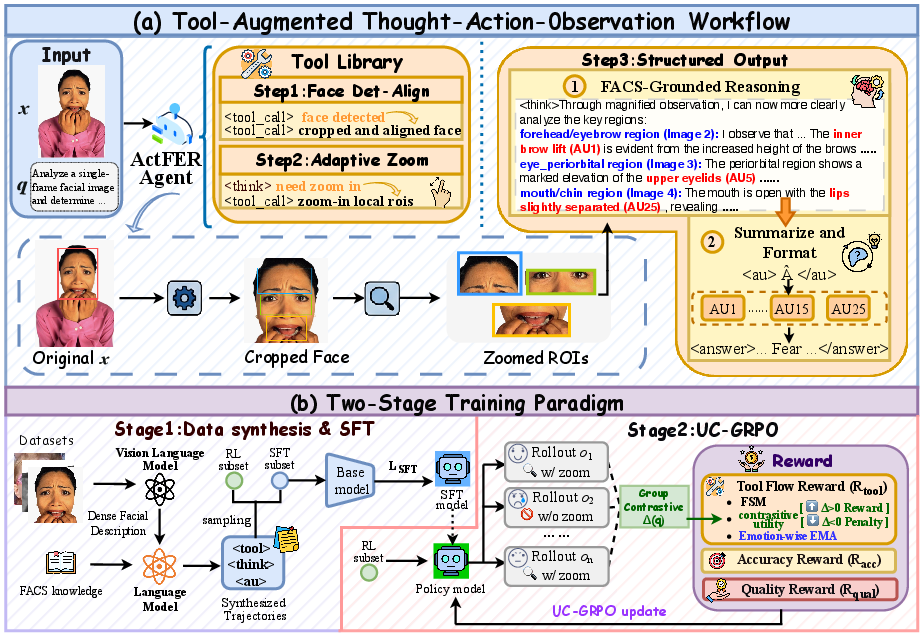
Figure 2: ActFER combines tool-driven visual reasoning, FACS-grounded inference, and two-stage SFT+UC-GRPO training.
The agentic pipeline is characterized by an iterative thought–action–observation loop: starting from the raw image, ActFER decides on evidence acquisition actions (e.g., zooming into subtle mouth or brow regions), processes the updated input, and sequentially reasons at both local (AU-level) and global (emotion-label) scales. All observations and actions are structured and interpretable, enabling actionable introspection and verification.
Data Curation and Supervised Fine-Tuning
Training leverages a synthetic multi-turn trajectory dataset curated from AffectNet, FERPlus, RAF-DB, and SFEW2.0. For each sample, ActFER prepares multiple tool-grounded variants (with or without zoom, with failed alignment, etc.), using state-of-the-art MLLMs (e.g., Qwen3VL-235B-A22B-Instruct) and FACS-injected knowledge to densely annotate AU and emotion evidence. This enables robust supervised pretraining on 48K trajectories via autoregressive loss, with careful class and protocol balancing across samples.
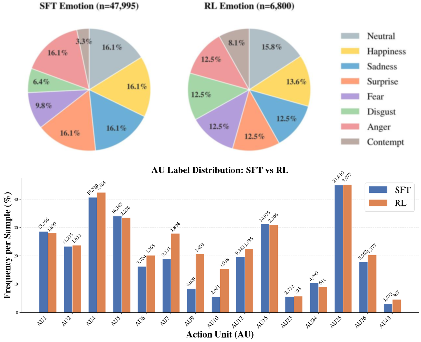
Figure 3: Curated training set statistics, showing emotion and AU distribution balance across supervised and RL subsets.
Utility-Calibrated RL: The UC-GRPO Algorithm
The central challenge in agentic FER is that active local inspection is non-uniformly beneficial—its utility depends on the sample, expression category, and image quality. The authors develop Utility-Calibrated Group Relative Policy Optimization (UC-GRPO), a domain-adapted RL technique, to train the ActFER policy. Key innovations:
Experimental Results
Benchmark Emotion Recognition
Evaluations on FERBench (AffectNet, RAF-DB, FERPlus, SFEW2.0) establish ActFER (UC-GRPO trained) as state-of-the-art among MLLM-based FER frameworks. ActFER achieves 73.89% accuracy and 67.45% macro-F1, outperforming both general-purpose MLLMs and previous FER-optimized models. Notably, gains are largest for subtle or ambiguous emotions (e.g., contempt), indicating proper utilization of category-specific inspection.
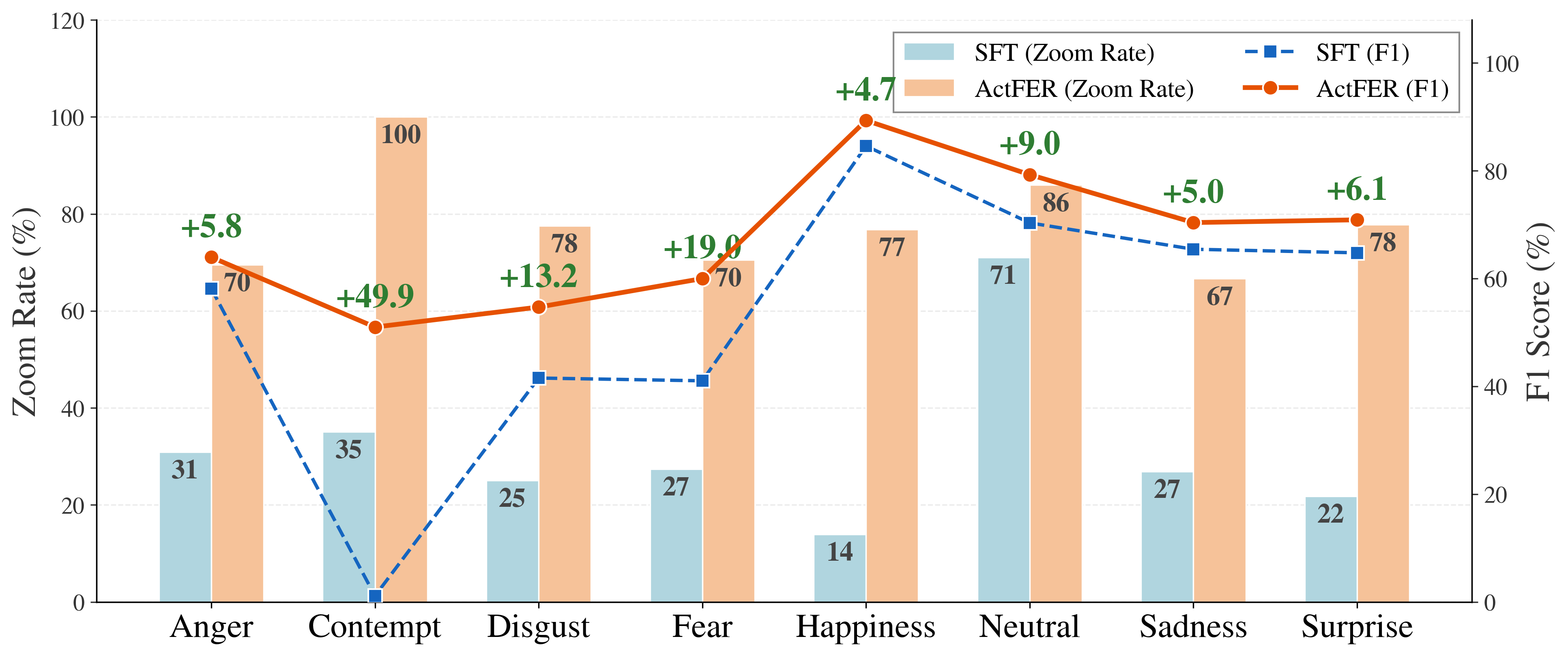
Figure 5: Per-emotion F1 and zoom ratios, evidencing category-dependent tool usage.
Zero-Shot AU Detection
On the DISFA test set (no fine-tuning), ActFER attains 58.2% average AU F1—unmatched among contemporary MLLM-based or FER-dedicated models. Gains are especially prominent for AUs that necessitate fine local scrutiny (AUs 6, 12, 25), demonstrating that the agentic zoom-in consistently improves structured local evidence formation.
Ablations and Policy Analysis
Ablation studies reveal that:
- Dense AU grounding in rewards is necessary but insufficient to induce tool use.
- Indiscriminate zooming leads to performance degradation and resource waste; adaptive, utility-driven policies outperform zoom-biased strategies.
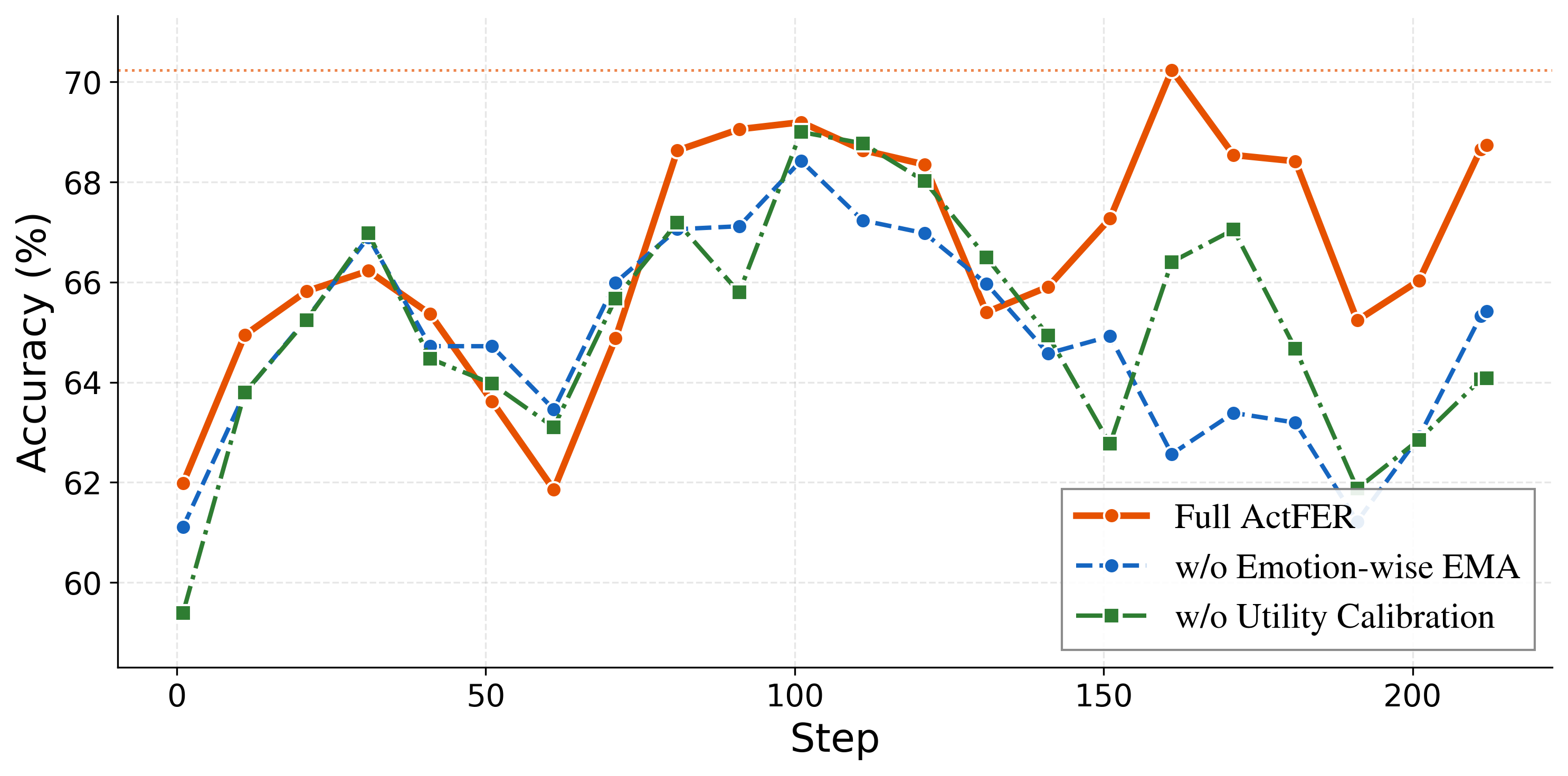
- Absence of emotion-wise EMA causes policy oscillations or collapse, highlighting the necessity of emotion-level utility aggregation for robust RL.
- The full training pipeline optimizes both tool efficiency and accuracy, converging on a high-performing, balanced inspection strategy.
Qualitative Evidence
Qualitative analyses illustrate explicit agentic reasoning: ActFER autonomously sequences face alignment, adaptive zoom-in to ambiguous facial regions, interprets local AU cues in context, and then integrates them into the final structured emotion prediction.
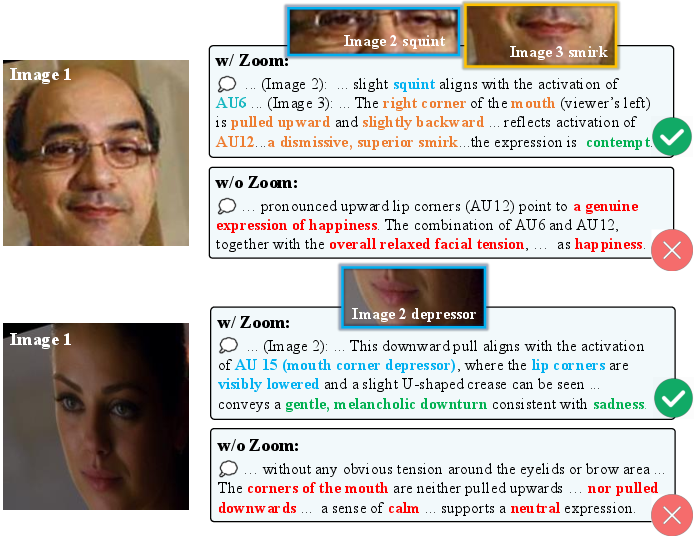
Figure 6: Subtle expressions resolved by adaptive zoom-in, reducing confusion on fine-grained cues.
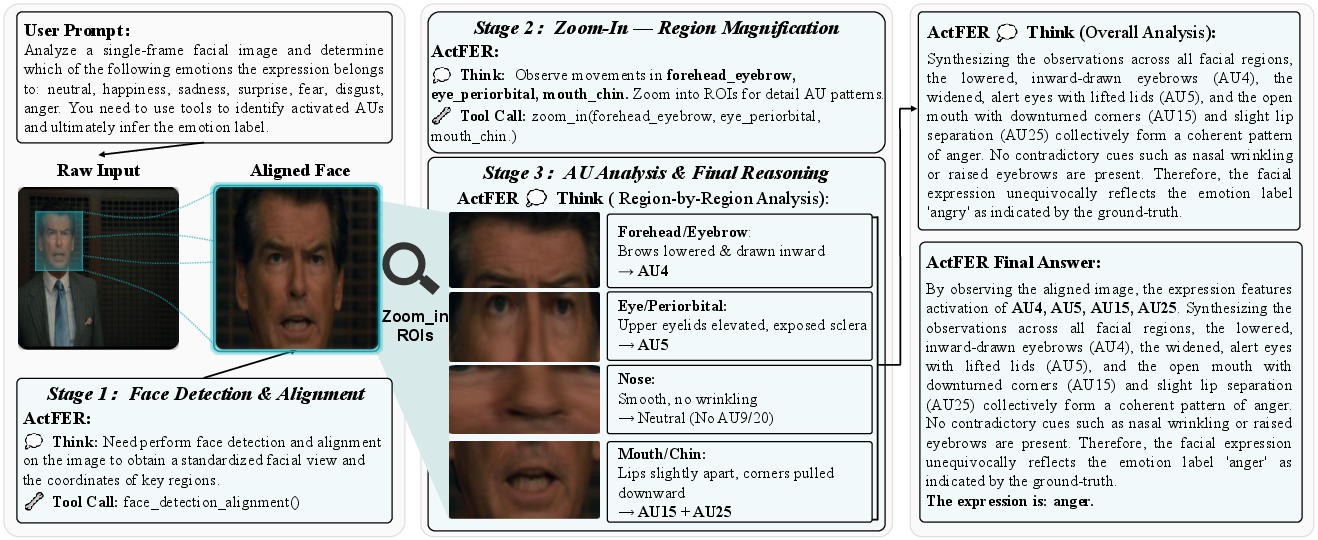
Figure 7: Stepwise case study—a complete agentic interaction, with region-wise tool invocation, AU reasoning, and emotion synthesis.
Theoretical and Practical Implications
ActFER’s architecture embodies a shift from passive visual understanding to agentic reasoning pipelines, closely aligning with cognitive models of human affect inference. The demonstrated sample-efficient, category-adaptive tool utilization results from utility-calibrated RL mechanisms, which could generalize to other vision-language reasoning domains. Practically, these innovations make ActFER robust to input variation and effective in real-world, safety-critical emotional understanding scenarios, such as assistive HCI or diagnostic support.
Furthermore, by operationalizing interpretable, FACS-grounded AUs as dense supervision, ActFER supports improved model transparency and actionable error analysis in affective computing pipelines, addressing demands for explainability in high-stakes AI.
Conclusion
ActFER sets a new standard for FER in MLLM contexts by integrating tool-augmented perception, agentic RL-based decision-making, and structured, interpretable reasoning grounded in facial Action Units. The framework realizes both superior empirical results—especially on challenging categories and zero-shot AU transfer—and an inherently transparent, modular inspection protocol. Looking forward, this approach provides a template for more generally agentic multimodal systems, where sequential evidence acquisition, localized reasoning, and dense reward shaping are synergistically employed for complex human-centric understanding tasks.