- The paper introduces a closed-loop dynamic network (CLDyN) that decouples fusion from task-specific constraints by integrating explicit downstream semantic feedback.
- The methodology employs a two-stage process with a frozen vision-guided fusion network and a Requirement-driven Semantic Compensation (RSC) module to dynamically adjust fusion based on task semantics.
- Experimental results demonstrate that CLDyN achieves superior mutual information and task-constrained metrics across diverse datasets with a minimal computational footprint.
Customized Fusion: A Closed-Loop Dynamic Network for Adaptive Multi-Task-Aware Infrared-Visible Image Fusion
Introduction
The paper "Customized Fusion: A Closed-Loop Dynamic Network for Adaptive Multi-Task-Aware Infrared-Visible Image Fusion" (2604.08924) introduces a new paradigm to address the limitations of prior task-aware infrared-visible image fusion methods, which traditionally couple the fusion process to particular downstream tasks and deteriorate when exposed to tasks outside of their training regime. The proposed Closed-Loop Dynamic Network (CLDyN) establishes an architecture with explicit feedback from downstream tasks, supporting robust semantic adaptation and optimal fusion across heterogeneous tasks, without retraining the fusion backbone.
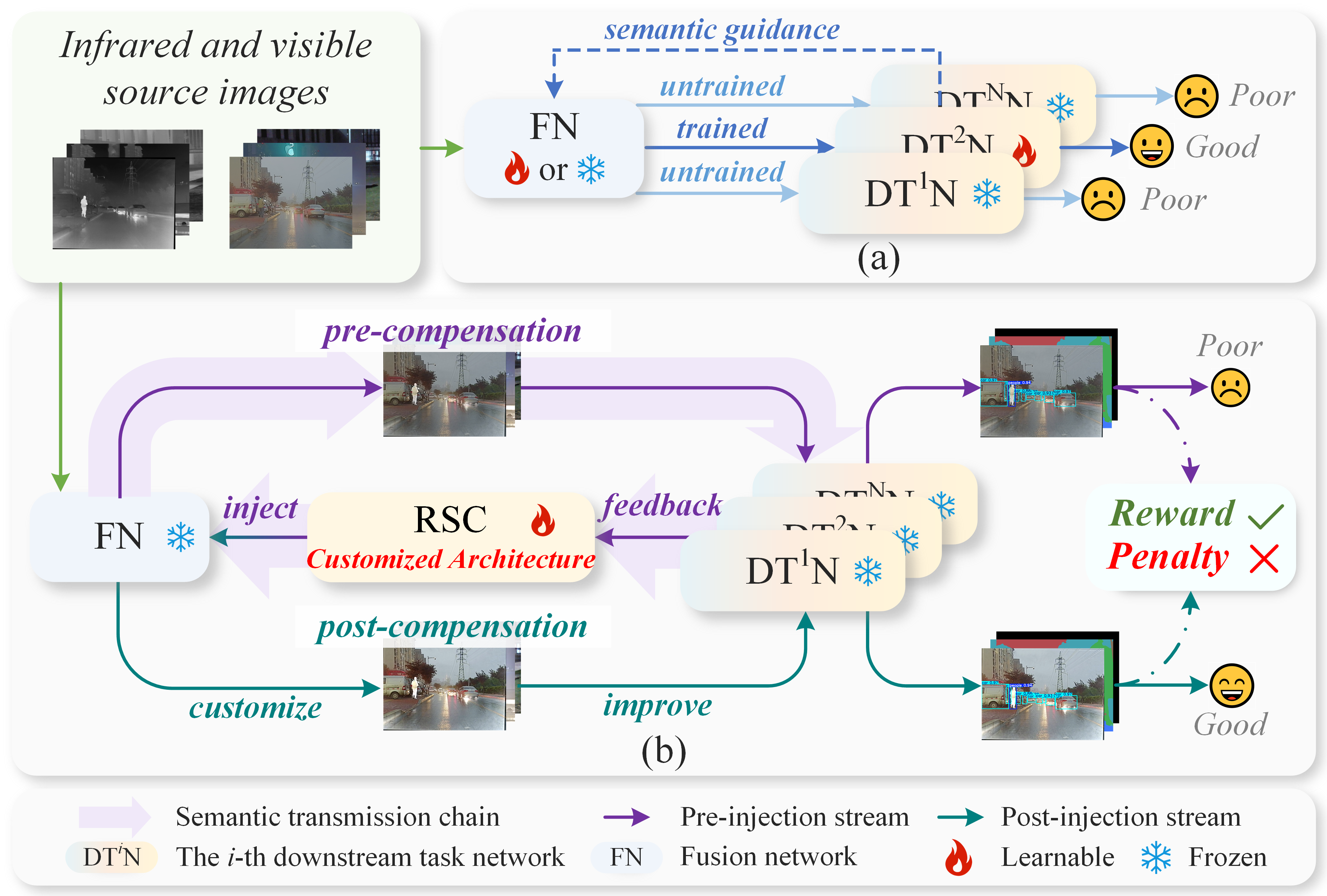
Figure 1: Comparison of processing paradigms between existing downstream task-aware image fusion methods (a) and the proposed closed-loop dynamic network (b).
Methodology
The core methodology centers on a two-stage process. Initially, a vision-guided fusion network (VFN) is trained for visually coherent fusion. Here, the input multi-modal pairs (infrared, visible) are processed through feature extraction blocks and a fusion feature reconstruction block, using a fusion loss to enforce pixel- and gradient-level consistency between fused and source modalities.
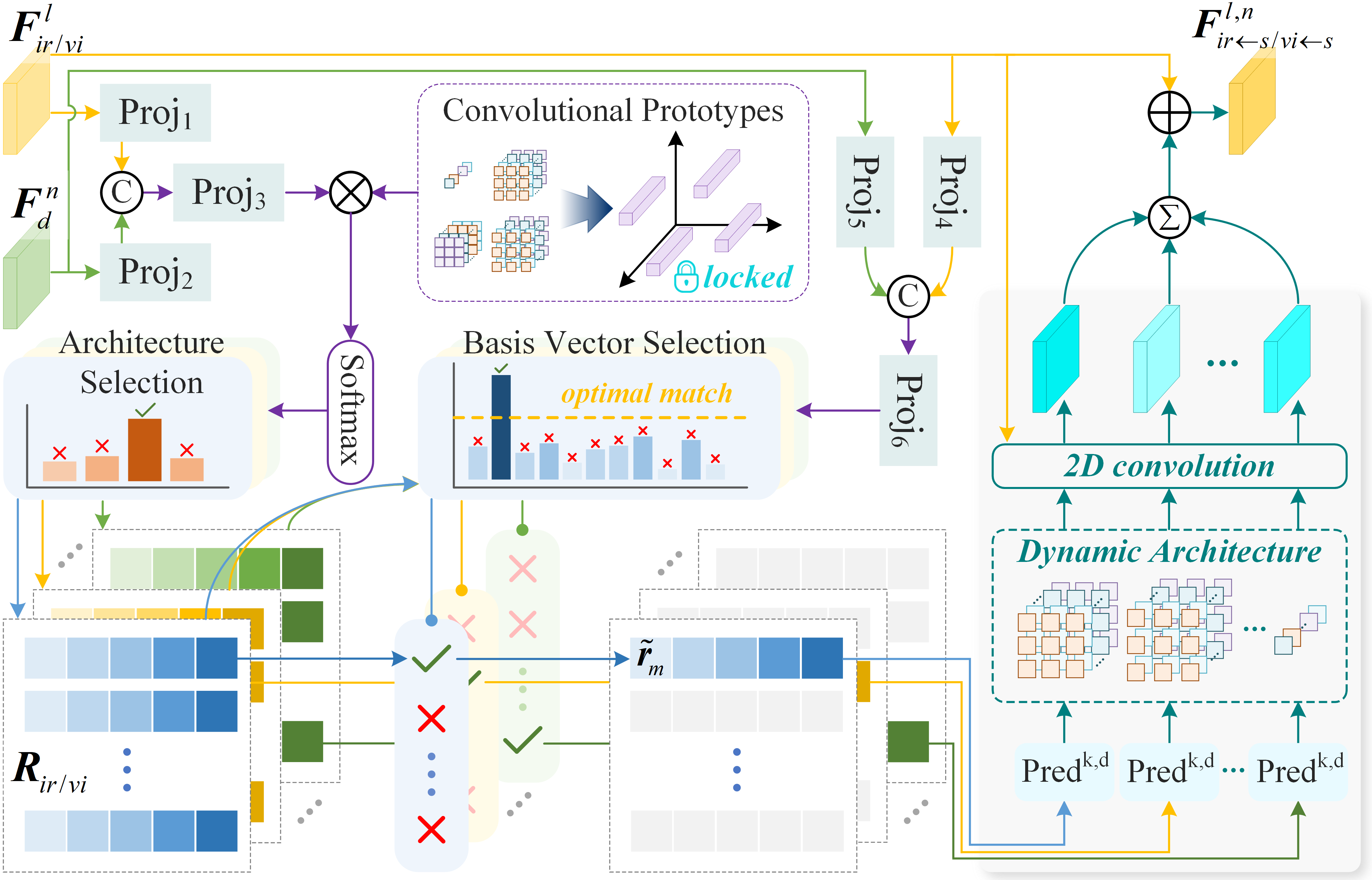
Subsequently, a closed-loop mechanism is introduced, freezing the VFN weights and attaching the Requirement-driven Semantic Compensation (RSC) module. This module, upon receiving semantic features propagated upstream from multiple downstream task networks (detection, segmentation, salient object detection), performs inference-time semantic compensation by augmenting VFN features in a task-specific manner.
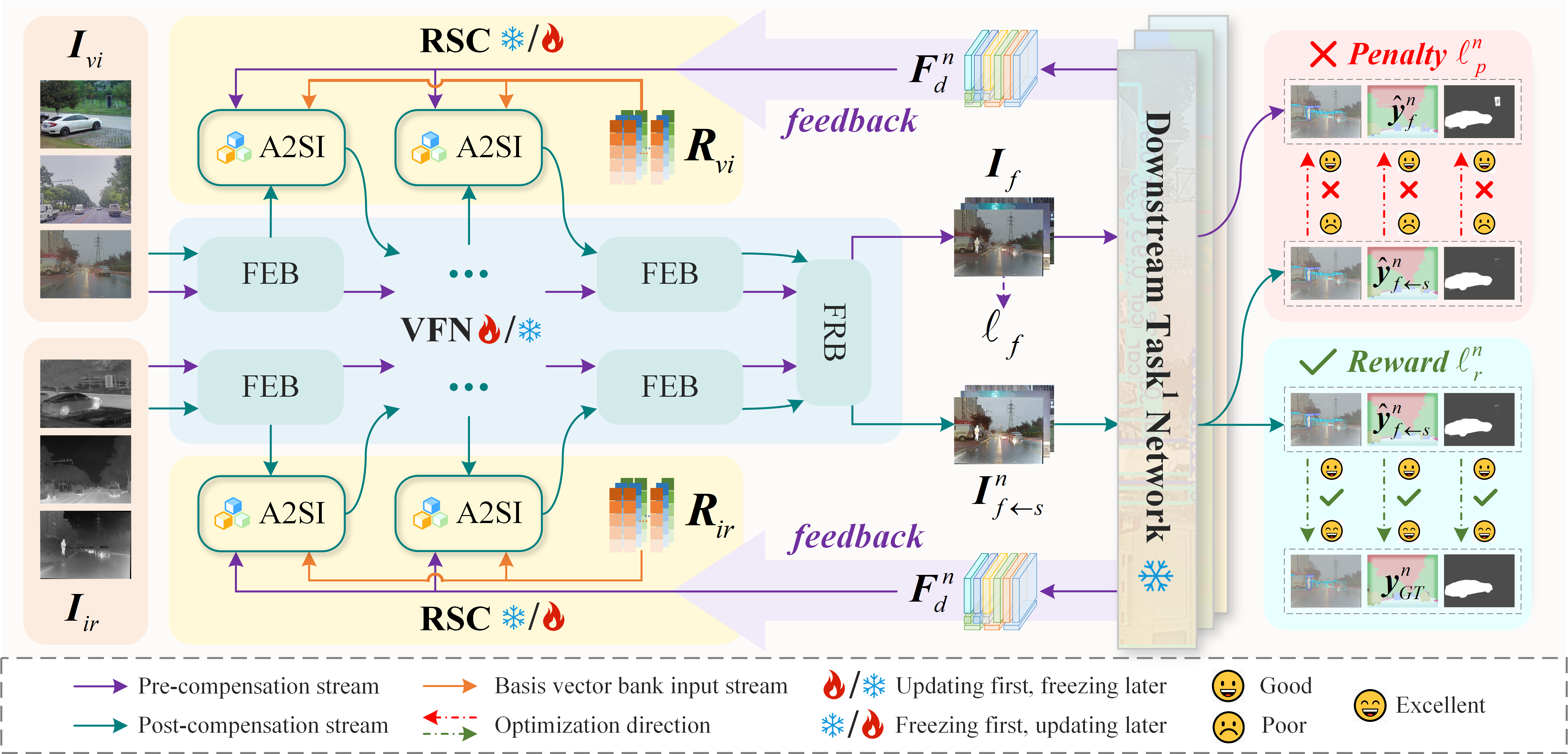
Figure 2: Overview of the adaptive multi-task-aware image fusion network with explicit semantic feedback and closed-loop reward-penalty compensation.
The RSC module leverages two unique subcomponents:
The system enforces a reward-penalty strategy for self-adaptive closed-loop training. When semantic compensation improves task performance, the RSC receives a reward via ground-truth supervision; when compensation yields no benefit or degradation, a penalty term is applied, thereby regularizing compensation magnitude and averting overfitting or catastrophic drift.
Experimental Results
Experiments are conducted on M3FD, FMB, and VT5000, representing a diversity of scenes and tasks. Comparisons encompass loss-driven, semantic-guided, and instruction-driven fusion baselines—SeAFusion, MetaFusion, TDFu, MRFS, SAGE, IDF-TDDT, etc.
Quantitative metrics (MI, Q_AB/F, Q_CB, Q_CV, Q_CC) reveal that CLDyN outperforms all comparison baselines, with best or second-best scores across all datasets. Notably, the method achieves superior mutual information and task-constrained metrics, evidencing both semantic richness and visual fidelity.
Further, ablation studies detail that both the closed-loop mechanism and RSC are essential for multi-task adaptability; BVB and A2SI respectively drive robust semantic matching and architectural flexibility, crucial for adapting to diverse downstream requirements.
Figure 4: Qualitative comparison between the proposed method and "task network retraining" methods.
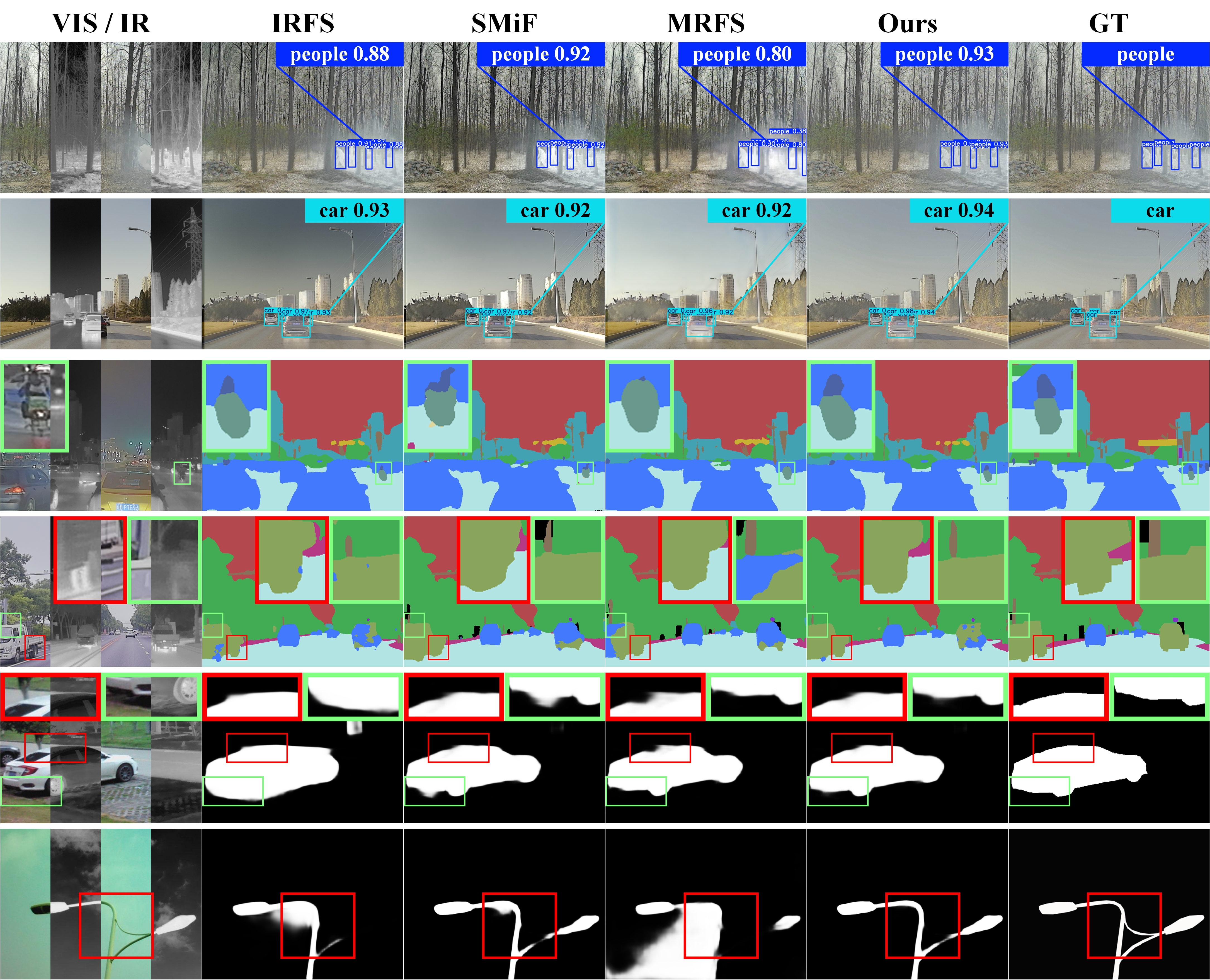
Figure 5: Qualitative comparison between the proposed method and "joint training" methods.
Cross-detector generalization is validated using different object detectors (YOLOv5, DETR), confirming high transferability without RSC retraining. The computational cost is highly efficient, with only ~0.46M parameters and ~174G FLOPs in the RSC module, outperforming significantly larger joint-training and retraining models.
Discussion
CLDyN makes several bold contributions. First, it is the only contemporary approach enabling plug-and-play adaptation of a frozen fusion network to multiple tasks with a single, compact RSC module. This is empirically validated across detection, segmentation, and SOD metrics.
Second, the closed-loop reward-penalty mechanism represents a robust, gradient-free semantic regularization, strictly outperforming open-loop or purely loss-based optimization strategies, as shown in head-to-head comparisons.
Theoretically, this work demonstrates that the introduction of explicit downstream feedback—rather than only fusing semantic priors in the forward pass—can solve longstanding generalization gaps in multi-modality fusion. Practically, the lightweight nature of CLDyN suggests utility in resource-constrained or embedded vision deployments, where retraining for downstream tasks is infeasible.
Importantly, as pre-trained foundation models for segmentation and detection (e.g., Segment Anything Model, LLaMA-encoded instruction guidance) become increasingly prevalent, CLDyN’s modality- and task-decoupled feedback mechanism provides a general template for broader multi-modal adaptation scenarios.
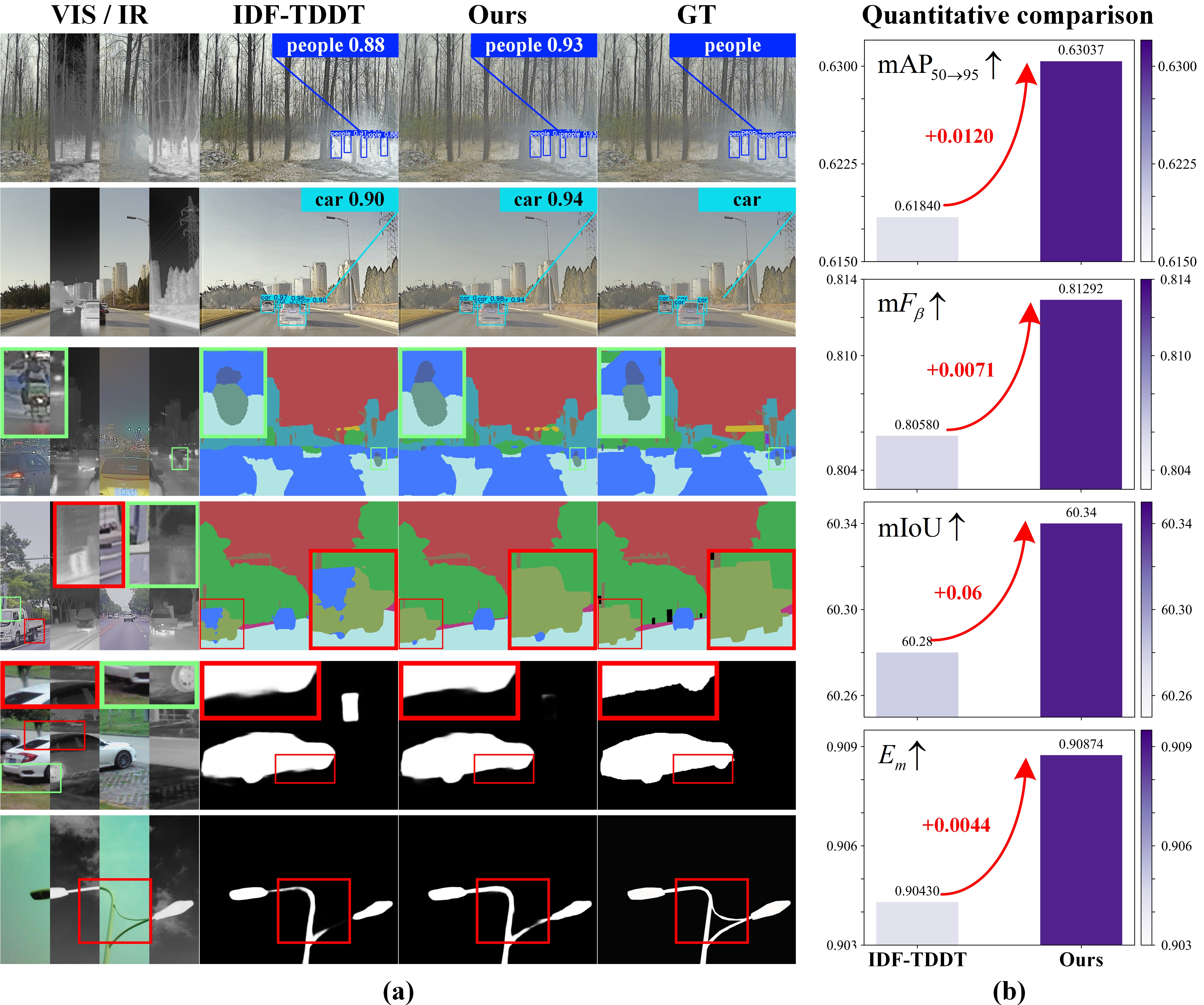
Figure 6: Qualitative and quantitative comparison between the proposed method and IDF-TDDT instruction-driven fusion.
Ablation and Component Analysis
Ablation studies verify that both BVB and A2SI are critical; removal of either leads to biased or degraded task-specific adaptation. The penalty loss acts as a critical regularizer to guarantee semantic balancing across tasks.
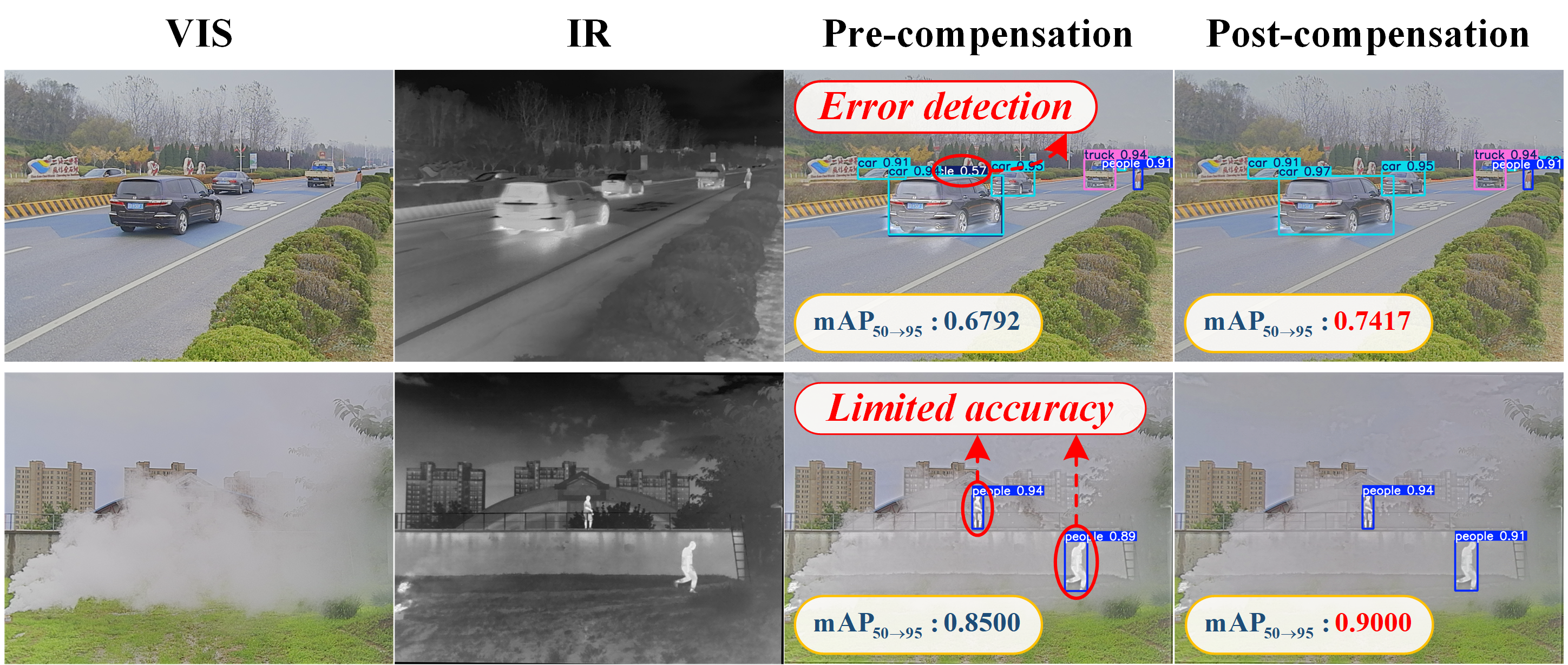
Figure 7: Qualitative and quantitative comparison between pre-compensation and post-compensation results, demonstrating improvement from closed-loop semantic compensation.
Additional complexity analysis establishes the method's scalability and efficiency, with robust convergence properties.
Training loss curves indicate stable, rapid convergence of both fusion and reward-penalty losses, highlighting strong optimization stability even when exposed to heterogeneous downstream gradients.
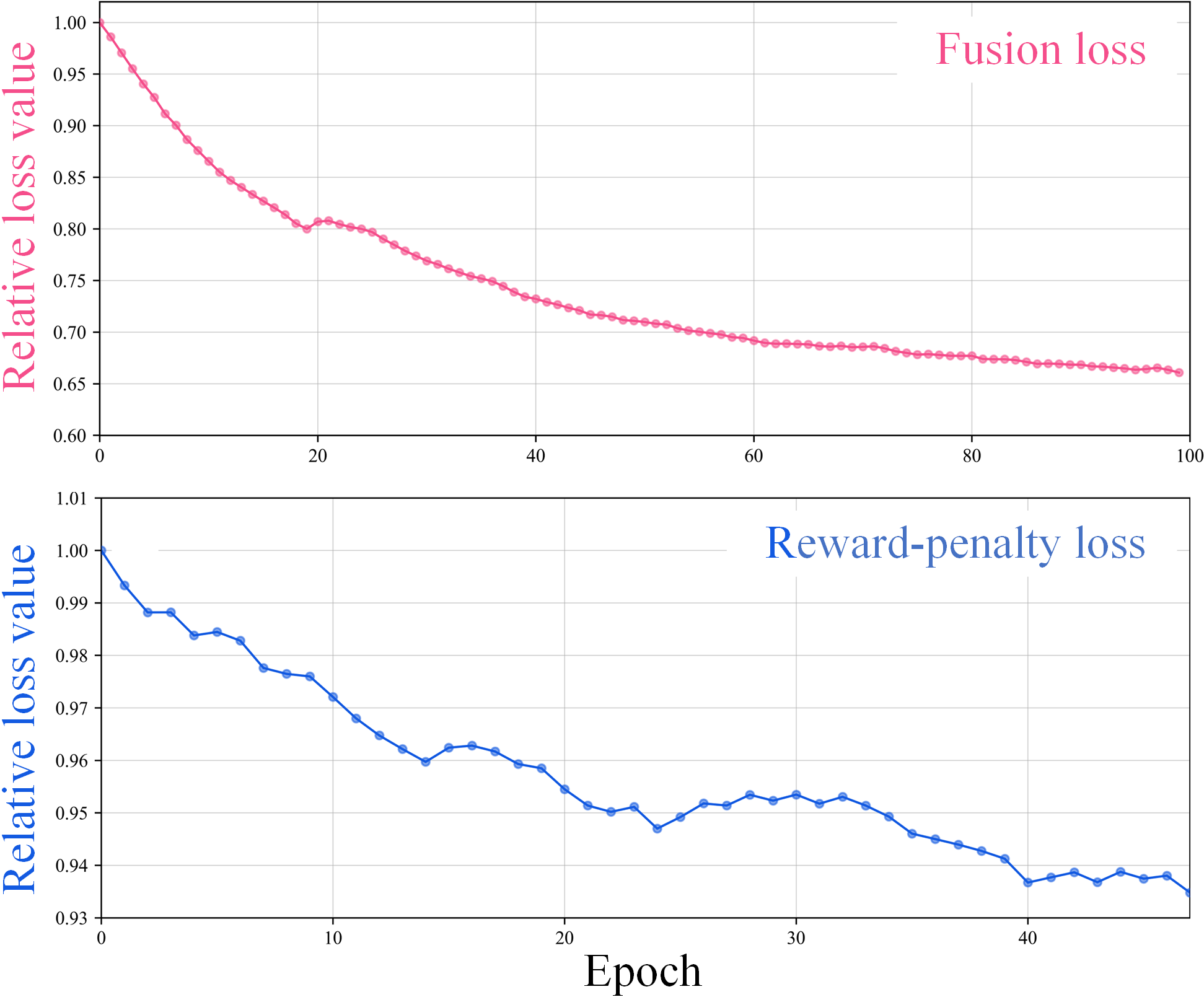
Figure 8: Training loss curves of the proposed method, illustrating convergence under the closed-loop reward-penalty regime.
Limitations and Future Directions
CLDyN currently assumes infrared and visible imagery captured in “normal” conditions. Performance may degrade in heavy weather, extreme low light, or when confronted with severe sensor-level degradation. Future extensions should address robust multi-degradation handling and fusion in open-world photometric domains, possibly combining RSC with domain adaptation or foundation model-driven pre-alignment.
Conclusion
CLDyN establishes a task-decoupled, closed-loop architecture for multi-task-aware image fusion, yielding state-of-the-art performance while requiring minimal adaptation or retraining effort. The explicit semantic feedback and reward-penalty controlled RSC module drive adaptation to downstream requirements beyond the reach of conventional loss or semi-supervised strategies. The modular design and low complexity of CLDyN indicate its high potential as a foundation for robust perception pipelines in multi-task, multi-modality AI systems.
(2604.08924)