- The paper introduces a dual-headed regression architecture using a fine-tuned XLM-RoBERTa-base model to predict continuous valence-arousal scores.
- The paper demonstrates significant performance gains, with up to 46% RMSE reduction compared to LLM-based prompting, especially on Chinese datasets.
- The paper highlights challenges from imbalanced sentiment distributions, noting that valence prediction is more complex due to sparse negative cases.
Fine-tuning XLM-RoBERTa for Multilingual Dimensional Aspect-Based Sentiment Regression
This study addresses SemEval-2026 Task 3 - Dimensional Aspect-Based Sentiment Analysis (DimABSA), focusing on the regression of valence-arousal (VA) scores for given aspects within text, in both English and Chinese, across restaurant, laptop, and finance domains. DimABSA expands aspect-based sentiment analysis (ABSA) from coarse categorical polarity annotations to the continuous ∈[1,9] VA space, leveraging the circumplex model of affect for more nuanced sentiment representation.
The core problem requires, given a sentence T and aspect ai, predicting a valence Vi and arousal Ai for each aspect-text pair. Each VA score is constrained within [1,9], supporting fine-grained modeling of both emotional positivity/negativity and intensity at the aspect level.
Model Architecture
The solution employs a fine-tuned XLM-RoBERTa-base model as the backbone. Inputs are constructed as [CLS] T [SEP] ai T0 sequences. The [CLS] token embedding is used as the input to a dual-headed regression architecture:
T1
Both regression heads are two-layer MLPs with Tanh activations and dropout. The affinity transformation ensures predictions remain within the valid VA interval.
Data Distribution and Linguistic Bias
Training data for each language-domain combination is sourced from DimABSA-annotated ABSA corpora, yielding variable training set sizes (notably larger for Chinese domains). Distribution analysis in VA space reveals a pronounced skew in English domains toward high-valence, high-arousal sentiments, while Chinese datasets demonstrate a more centered VA distribution.
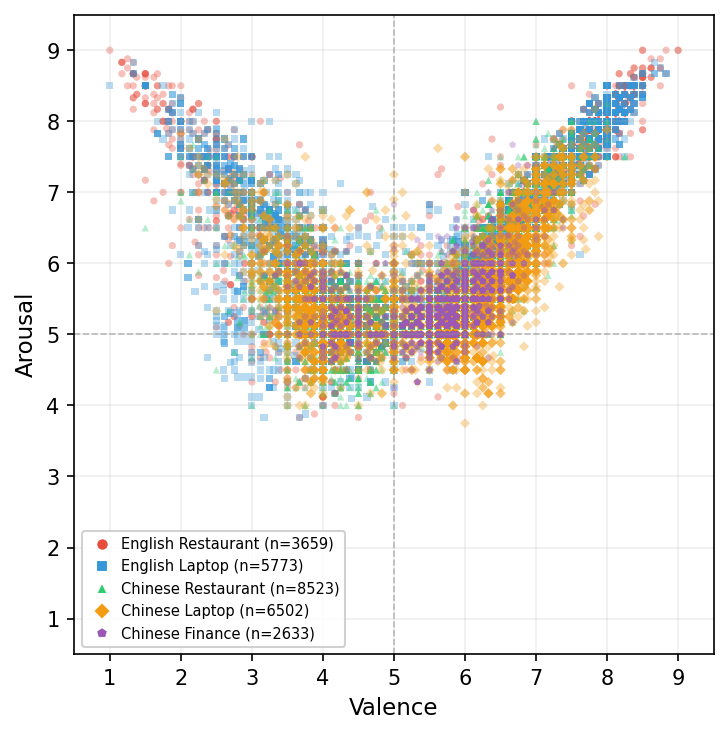
Figure 2: Training data distribution in VA space. English datasets cluster in the high-valence, high-arousal region, while Chinese datasets are more centered.
This distributional bias has direct implications on model generalization and prediction calibration, particularly affecting the capacity to accurately model negative valence or extreme arousal cases given sparse supervision in those regions for English.
Experimental Evaluation and Results
Comparative Analysis with LLM-Based Prompting
A comprehensive evaluation is conducted comparing the fine-tuned XLM-RoBERTa architecture against prominent LLMs—GPT-5.2, LLaMA-3-70B, LLaMA-3.3-70B, and LLaMA-4-Maverick—in few-shot prompting regimes. Each LLM receives a task-specific prompt template with 6 examples, outputting VA predictions under low-temperature (T2) decoding.
The fine-tuned XLM-RoBERTa model achieves substantially lower RMSET3 across all domains and languages compared to LLMs, with an average reduction over the best LLM baseline of 0.77 RMSET4, equating to ~46% relative improvement. The performance gap is especially pronounced on Chinese datasets, indicating that LLMs, even with strong cross-lingual pretraining, underperform in this precise regression task.
Test set results further confirm the superiority of the fine-tuning paradigm. On all five language-domain test sets, the XLM-RoBERTa-based solution surpasses the Kimi-K2 Thinking baseline and the QLoRA-finetuned Qwen-3-14B model, with relative improvements ranging from 31% to 63% in RMSET5. Chinese Finance achieves the lowest test error (0.5391 RMSET6), while English domains remain the most challenging, primarily due to the aforementioned label skew.
Error Characterization in VA Space
Spatial error analysis performed via VA binning on the test set demonstrates that out-of-distribution regions—chiefly low-valence bins—exhibit the largest errors, with RMSET7 exceeding 2.0 in the English domains. This directly correlates with data sparsity in those bins, signifying a limitation of supervised fine-tuning in the absence of uniform coverage across the sentiment spectrum.
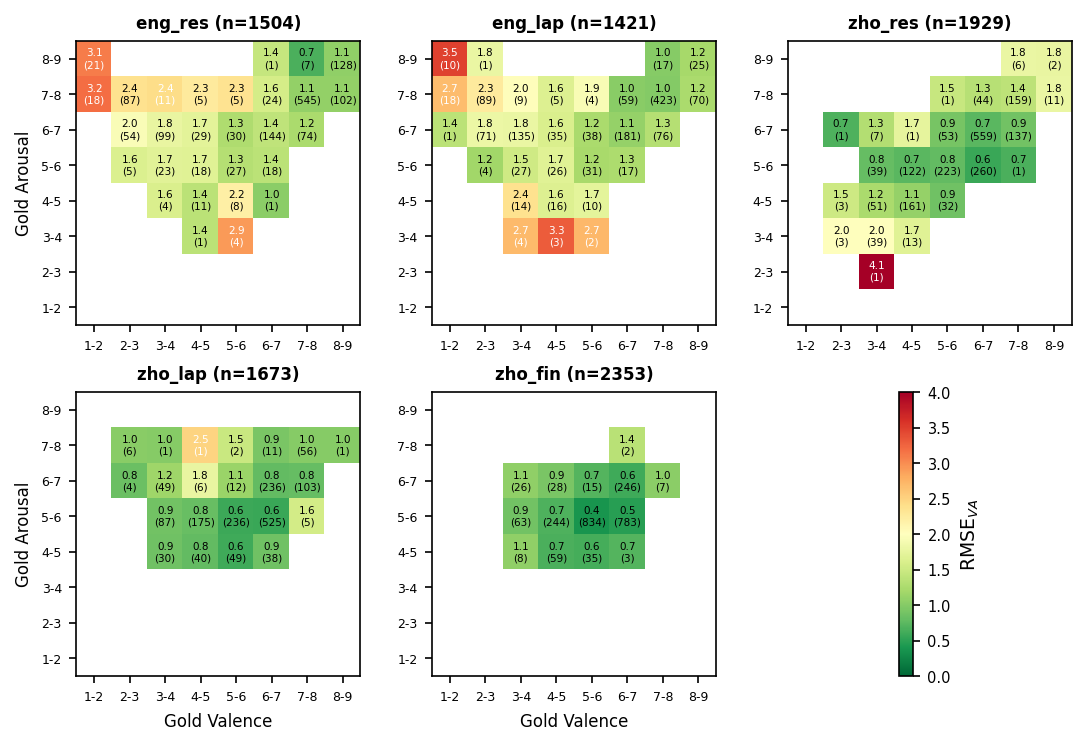
Figure 4: Test-set RMSET8 heatmap across the valence-arousal space. Red bins denote higher errors, which concentrate in low-valence (negative) regions.
Per-dimension decomposition shows that valence prediction is consistently more difficult than arousal (e.g., on English Laptop: RMSET9 = 1.25 vs. RMSEai0 = 0.75). This suggests that arousal cues are more readily captured by surface-level features, while valence inference necessitates deeper semantic understanding and disambiguation.
Implications and Future Directions
The results underscore the value of discriminative fine-tuning for multidomain, multilingual dimensional sentiment regression, particularly when sufficient task-specific annotated data is available. LLMs, even with best-in-class prompting, lag in predictive precision—likely due to token-based output dynamics, limited calibration capability with small demonstration sets, and suboptimal mapping from text generation to real-valued regression tasks.
Theoretical implications include the observation that cross-lingual and cross-domain VA regression benefits from both pretraining scale and distributional alignment between source data and target test points. For practical applications—such as dialogue systems, reputation management, or financial market sentiment tracking—these results favor explicit fine-tuning over prompt engineering, provided label resources can be curated.
For future research, directions include experimenting with larger encoder models (e.g., XLM-RoBERTa-large), integrating multi-task objectives across related sentiment subtasks, and leveraging affective lexicons or data augmentation to address data sparsity in underrepresented VA regions. Modeling explicit aspect-level attention and exploring more advanced representations for aspect conditioning could further benefit hard cases involving sarcasm, negation, or implicit sentiment.
Conclusion
This work validates a fine-tuned XLM-RoBERTa-base model with dual regression heads as an effective approach for multilingual, multidomain dimensional aspect sentiment regression. The fine-tuning paradigm consistently outperforms state-of-the-art LLM-based prompting approaches, highlighting current limitations of LLMs in precise regression tasks requiring calibrated numeric predictions. Data distribution remains a primary limiting factor, especially for low-frequency sentiment extremes. Future work should address these distributional gaps and consider architectural enhancements for deeper aspect-level sentiment modeling.
References:
For detailed citations, refer to the original paper (2604.08923).

