- The paper introduces a coarse-to-fine 3D-guided framework that enforces multi-view mask consistency to overcome the limitations of 2D-only segmentation methods.
- It employs superpoint decomposition, SAM-based 2D mask acquisition, and depth consistency weighting to reliably lift 2D segmentation masks into coherent 3D segments.
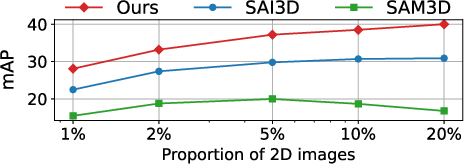
- Empirical results on ScanNet benchmarks show MV3DIS outperforming supervised models, especially in open-vocabulary and sparse view scenarios.
MV3DIS: Multi-View Mask Matching via 3D Guides for Zero-Shot 3D Instance Segmentation
Introduction and Motivation
Zero-shot 3D instance segmentation remains a central challenge in computer vision due to the cost-prohibitive nature of large-scale 3D annotation. Prevailing approaches attempt to leverage multi-view 2D segmentation masks, especially those generated by foundation models such as SAM, aggregating these cues into 3D via geometric reasoning. However, existing methods process 2D views independently and depend exclusively on per-frame, 2D-centric metrics—resulting in view-inconsistent masks and consequently fragmented 3D segmentation outputs. Such fragmentation reveals a key shortfall: the absence of explicit 3D priors and mechanisms to enforce cross-view mask agreement.
MV3DIS addresses these limitations. It introduces a coarse-to-fine, 3D-guided framework designed to enforce view consistency in mask assignment and improve the reliability of the 2D-to-3D lifting process. By leveraging 3D segments as common reference anchors for mask matching and incorporating a novel depth consistency weighting scheme, MV3DIS produces significantly more coherent 3D segmentations, as demonstrated empirically on ScanNetV2, ScanNet200, and ScanNet++. Notably, MV3DIS claims positive transfer even in open-vocabulary regimes, where supervised methods typically fail to generalize.

Figure 1: View inconsistency in existing methods versus view consistency with MV3DIS. Existing methods lead to significant mask fragmentation, while MV3DIS enforces multi-view alignment and produces coherent 3D instance segments.
Methodology
Coarse-to-Fine 3D Instance Segmentation Pipeline
MV3DIS proceeds in two main stages: a coarse, SAM-guided 3D segmentation phase and a subsequent 3D instance refinement phase. The framework's high-level strategy involves:
- Superpoint Decomposition and SAM Mask Acquisition: The point cloud is over-segmented into geometrically coherent superpoints using a graph-cut algorithm. For each RGB-D frame, SAM (or other 2D foundation models) predicts candidate masks, which are disambiguated and merged into per-frame 2D segmentation maps.
- Superpoint Merging for Coarse 3D Segmentation: A superpoint affinity graph is constructed using the 2D segmentation maps. Region growing—weighted by local affinity, spatial proximity, and superpoint size—merges superpoints into initial coarse 3D segments.
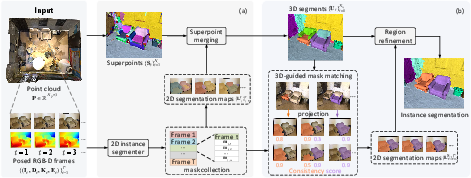
Figure 2: MV3DIS's two-stage pipeline: (a) Coarse segmentation via SAM-guided superpoint merging; (b) 3D-guided mask matching and iterative refinement via multi-view mask consistency.
3D-Guided Multi-View Mask Matching
To counteract view inconsistency, MV3DIS introduces a 3D-guided mechanism for mask matching:
Experimental Evaluation
MV3DIS is benchmarked against open-vocabulary and supervised closed-vocabulary baselines on ScanNetV2, ScanNet200, and ScanNet++. The evaluation considers class-agnostic and semantic instance segmentation, measuring AP at various IoU thresholds.
Key empirical findings:
Ablation studies isolate the contribution of each system component (region refinement, 3D mask matching, depth consistency weighting), with each intervention resulting in measurable mAP increases. The depth consistency weighting and 3D-guided mask matching are especially influential for view consistency and occlusion-handling.
Scalability Analysis:
Theoretical and Practical Implications
MV3DIS’s explicit enforcement of view-consistent mask matching via 3D priors and geometric reasoning signals a robust direction for zero-shot 3D instance segmentation. The method demonstrates that integrating geometric projection reliability can substantially close the gap between zero-shot and supervised approaches, particularly in open-vocabulary or long-tail class regimes. Furthermore, the absence of video-dependent tracking or temporal constraints renders the approach well-suited to static, arbitrarily captured multi-view datasets—broadening its practical deployment potential.
On the theoretical front, the results suggest that multi-view consistency is not simply a matter of effective 2D mask aggregation but requires consistent 3D referencing and error-aware projection models. The depth consistency weighting mechanism, in particular, may be extensible to other vision tasks involving noisy or uncertain geometric transformations.
Future Directions
Potential future research avenues include:
- Generalizing the 3D-guided mask matching paradigm to address category-level semantic segmentation or panoptic segmentation in zero-shot settings.
- Extending projection reliability modeling to dynamic scenes or outdoor environments exhibiting complex occlusion patterns and lighting/capture variance.
- Integrating language or multimodal cues into the mask matching process, enabling tighter coupling between 3D geometry and high-level semantic understanding.
Conclusion
MV3DIS establishes a new robustness baseline in zero-shot 3D instance segmentation by leveraging 3D-guided mask matching and projection reliability. Its strong empirical results, including superior performance to well-trained closed-set baselines in open-vocabulary and few-shot scenarios, substantiate the critical role of 3D priors and multi-view consistency practices. These findings underscore the necessity of principled 3D-2D aggregation in the design of scalable, annotation-efficient 3D scene understanding systems.