- The paper introduces BIAS, a computationally efficient, biologically inspired algorithm that fuses static and dynamic cues for real-time video saliency detection.
- It employs a retina-inspired motion detector and a Gaussian Winner-Take-All module to integrate and quickly process visual features on the DHF1K dataset.
- The study demonstrates practical utility in traffic accident anticipation by achieving predictive lead times of 0.72 seconds with state-of-the-art accuracy.
BIAS: A Biologically Inspired Algorithm for Video Saliency Detection
Introduction
The BIAS model (Biologically Inspired Algorithm for video Saliency detection) introduces a computationally efficient framework for dynamic visual saliency detection in continuous video streams, synthesizing static and motion cues within a biologically plausible architecture. Rooted in the Itti–Koch framework, BIAS integrates a retina-inspired motion detector and a Gaussian Winner-Take-All (GWTA) mechanism for fixation selection, yielding interpretable spatiotemporal saliency maps at millisecond-scale latency. The framework is positioned to address real-time requirements, especially in domains such as traffic accident anticipation, where both speed and precision are critical.
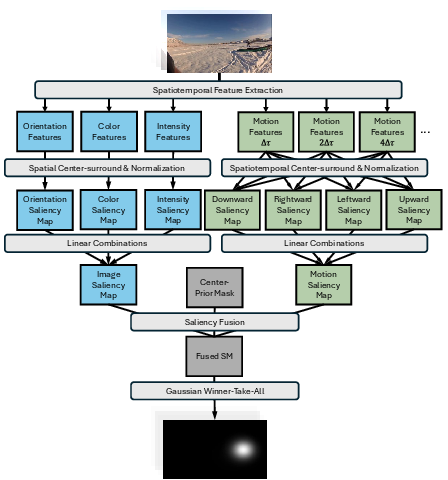
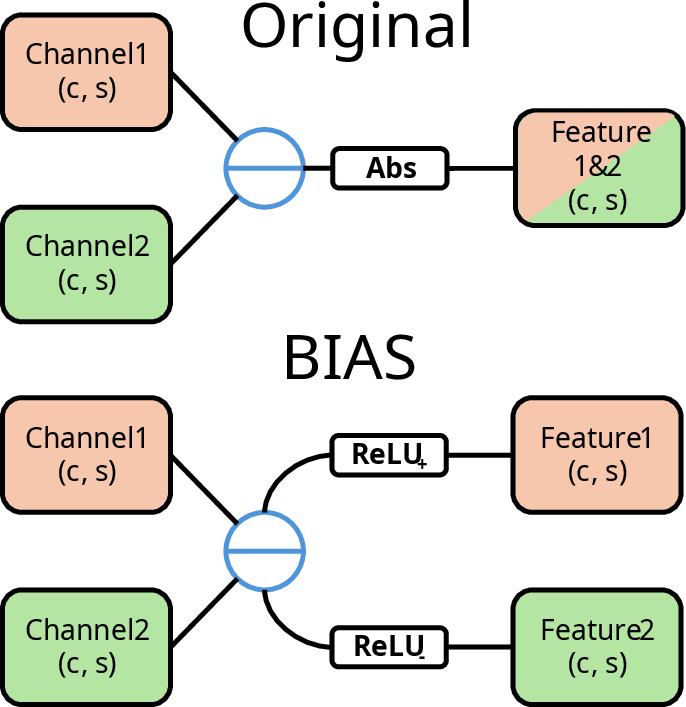
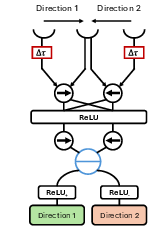
Figure 1: (a) General architecture of BIAS; (b) Comparison of center–surround computation between Itti's original model (top) and BIAS (bottom); (c) Motion computation inspired by direction-selective cells in the fly retina.
Model Architecture and Methods
Static Saliency Pathway
BIAS adapts the classical bottom-up saliency paradigm for images by generating pyramidal feature maps for intensity, color, and orientation, using efficient kernel-decomposed Gabor filters to accelerate orientation computation. Center–surround operations and rectifications preserve opponent polarities, followed by normalization and fusion to form the static saliency map.
Motion Saliency Pathway
Distinctively, BIAS introduces a motion saliency detector derived from the Hassenstein–Reichardt model, emulating direction-selective mechanisms observed in the fly retina. Motion responses are calculated over multiple directions and temporal offsets, forming multi-scale motion conspicuity maps.
Saliency Fusion and Fixation Selection
A second-order fusion of static and motion saliency maps is performed, with optimal linear weightings determined empirically. Fixation selection is handled by the GWTA module, which fits Gaussian peaks via gradient ascent, balancing winner-take-all competition and spatial information maximization. The fixation maps are updated with a Gaussian center prior and temporally smoothed using an EWMA filter.

Figure 2: Predicted saliency maps for a sample DHF1K video clip: original frame, image-based saliency, motion-based saliency, combined master map, GWTA-predicted fixations, and human fixation ground truth.
Empirical Evaluation
BIAS was benchmarked on DHF1K, a large-scale dynamic eye-tracking dataset, using standard metrics: NSS, SIM, CC, AUC-Judd, and s-AUC. BIAS demonstrates superior performance relative to all heuristic-based models and is competitive with a significant proportion of deep learning-based models, while operating at orders of magnitude faster runtime on CPU.
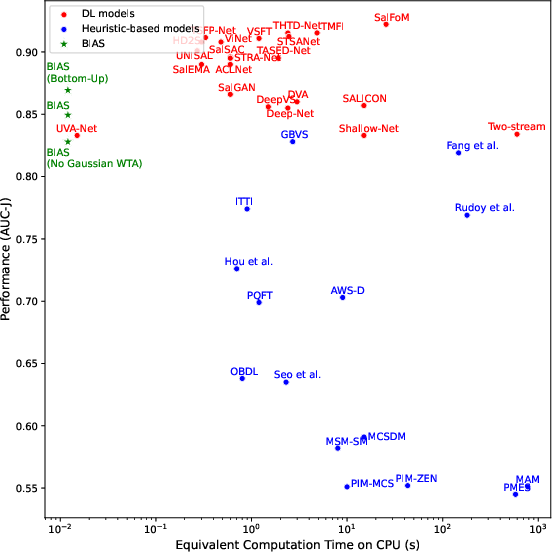
Figure 3: Performance and runtime comparison between BIAS and competing saliency models.
Ablation studies confirm the significant impact of GWTA and EWMA on performance, with minimal sensitivity to the number of center–surround scale pairs, allowing for significant inference acceleration. The flicker motion cue was found marginal in this setting.
Figure 4: (a) Correlation metrics for center–delta pairs; (b) EWMA impact; (c) GWTA impact across scale combinations.
Content Analysis and Error Modes
On the DHF1K dataset, BIAS achieves highest accuracy on stimuli dominated by strong, low-level motion cues—such as animal-rich scenes or segments exhibiting rapid object displacement. Performance consistently decreases with scene complexity as measured by object count, fixation cluster entropy, and semantic clutter, reflecting the model’s strict bottom-up prescription.

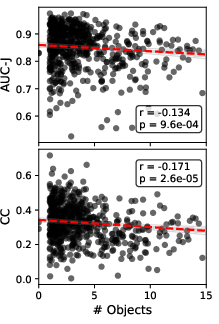
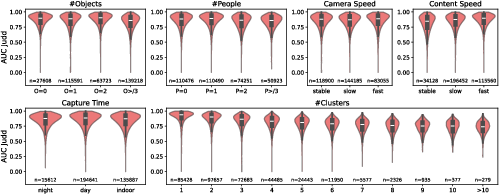
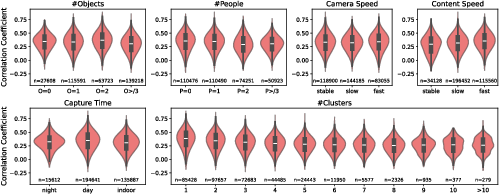
Figure 5: (a) Qualitative examples: rows exemplify strong, moderate, and low BIAS performance; (b–e) Correlations between model accuracy, semantic content categories, object/person count, camera/content speed, and fixation cluster statistics.
Real-World Utility: Traffic Accident Anticipation
A key practical contribution of BIAS is its application to traffic accident anticipation. Using the Traffic Accident Benchmark for Causality Recognition, BIAS-generated saliency maps, processed via SparK feature extraction and an MS-TCN module, enable accident segmentation and anticipation.
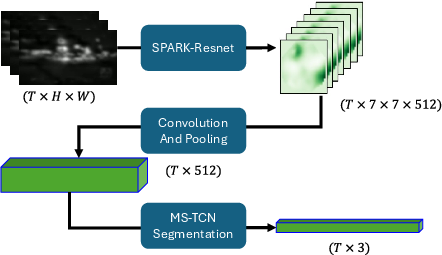
Figure 6: BIAS-SparK architecture—saliency maps are compressed and temporally modeled for accident segmentation.
In causality recognition and effect segmentation, BIAS-SparK achieves state-of-the-art IoU scores, surpassing both backbone deep feature models (Kinetics-I3D) and alternative saliency methods (Itti, SalFoM), particularly for effect localization. Notably, BIAS-SparK anticipates accident causes 0.72 seconds ahead of manual annotation with reliable accuracy—a quantitatively strong result for anticipatory tasks.
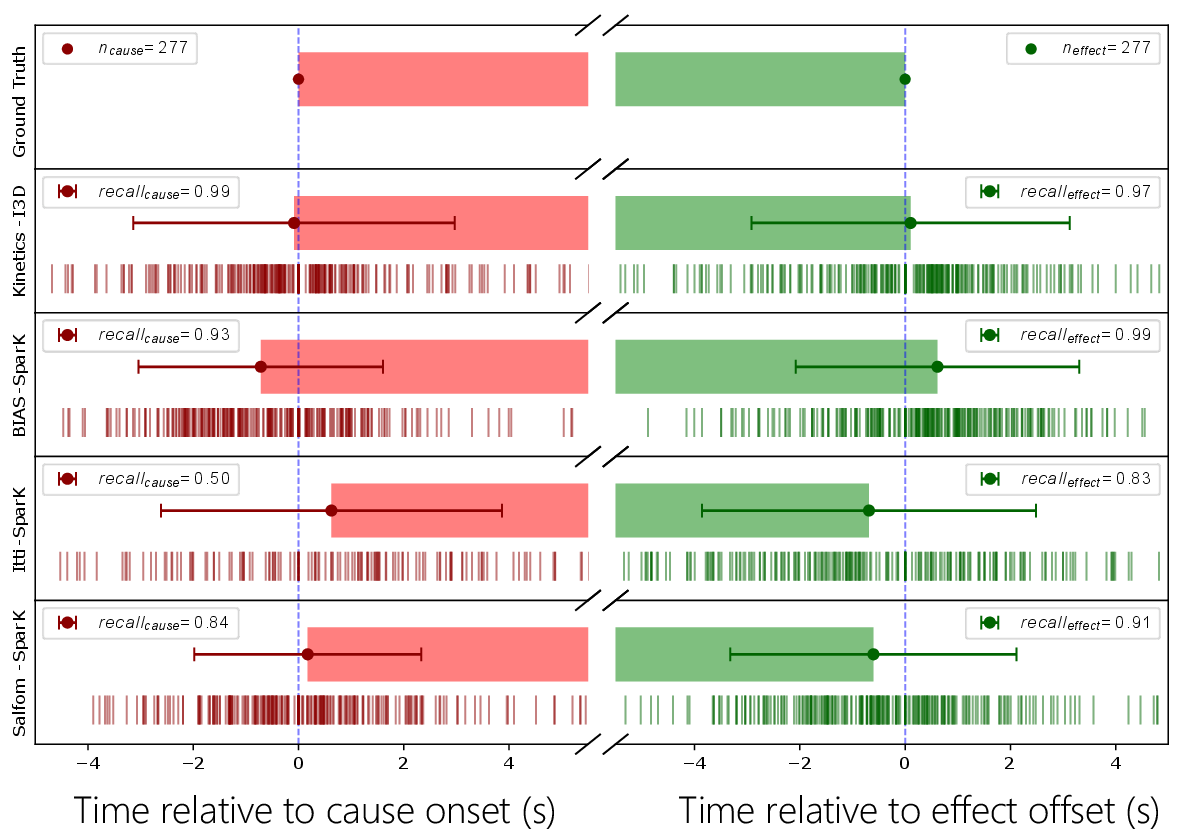
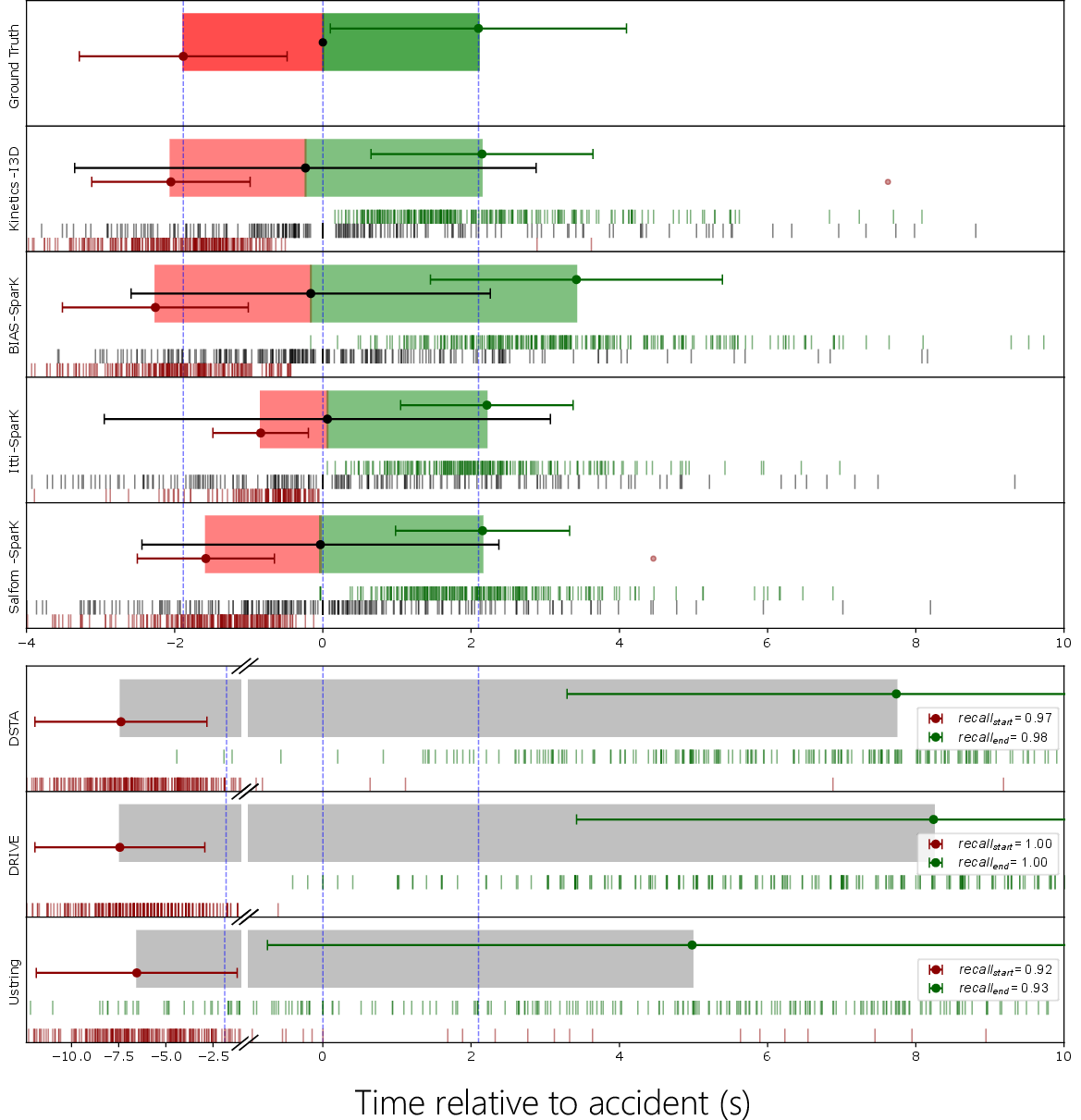
Figure 7: (a) Lead time of predicted cause/effect events (negative = earlier than ground truth); (b) Predicted time to accident (TTA) comparison across models.
Analysis attributes the lower IoU for cause localization to earlier detection, with BIAS providing predictive signals that precede the semantic (label-defined) event—corroborated by statistically significant negative lead times versus alternatives.
Theoretical and Practical Implications
The results substantiate the hypothesis that low-level, bottom-up saliency is a sufficient and efficient driver for dynamic attentional allocation in a variety of real-world settings, including demanding safety-critical domains. The model’s extreme computational efficiency and interpretable feature construction position it for deployment on resource-constrained hardware and in areas requiring low latency, including robotics, surveillance, and advanced driver-assistance systems.
However, empirical limitations were observed for complex scenes requiring high-level semantic integration, multivariate object interactions, or scenes where top-down attentional signals predominate. These limitations highlight avenues for future work—principally, hybridization with goal-driven or semantic modules that retain the biological interpretability and velocity of BIAS’s pipeline.
Conclusion
BIAS introduces a biologically constrained, computationally efficient framework for dynamic saliency detection, narrowing the gap between biological plausibility and practical application. The integration of fast motion detectors, efficient scale selection, and the GWTA mechanism allows BIAS to match or exceed deep models in bottom-up-dominated scenes at a fraction of the computational cost. Its strong anticipatory performance in accident detection tasks demonstrates the continued relevance of bottom-up attention mechanisms in both the study and application of visual cognition. Future developments should explore multi-pathway (bottom-up and top-down) integrations to expand the applicability of this approach in more complex, semantic-rich visual environments.
Reference: "BIAS: A Biologically Inspired Algorithm for Video Saliency Detection" (2604.08858)

