- The paper introduces a novel RAG-based pipeline to generate knowledge-aware reasoning traces for fundus image interpretation using public data.
- It demonstrates improved diagnostic performance through a two-stage SFT + RLVR training pipeline with a unique answer-dependent process reward for reasoning validation.
- Empirical evaluations show Fundus-R1 surpasses existing MLLMs on benchmarks, offering reproducible and accessible ophthalmic AI research.
Fundus-R1: Knowledge-Aware Reasoning for Fundus-Reading MLLMs Using Public Data
Fundus imaging modalities such as CFP, OCT, and UWF are indispensable for the early detection and diagnosis of retinal diseases. The complexity and knowledge-intensive nature of fundus image interpretation make it a challenging vision-language task; expert-level reading requires both identification of subtle visual findings and structured reasoning grounded in domain-specific clinical knowledge. Prior advancements in fundus-reading MLLMs have relied heavily on proprietary datasets containing detailed clinical reports or reasoning traces, effectively limiting reproducibility and broad progress. This work addresses whether it is possible to train a reasoning-enhanced fundus-reading MLLM using only publicly available datasets, more than 94% of which provide merely image-level annotations.
Knowledge-Aware Reasoning Trace Generation
The key innovation introduced is a RAG-based pipeline for composing image-specific, knowledge-aware reasoning traces to supplement public data with intermediate supervision. The process involves three stages:
- Label- and Modality-Specific Domain Knowledge Acquisition: Authoritative references (EyeWiki, AAO, PMC) are queried via RAG and structured using a generic LLM to construct domain knowledge records DK[y,m]—where y is a disease label and m is an imaging modality. A vocabulary of visual findings (VF) is derived from the synthesized knowledge, partitioned as required and supportive findings.

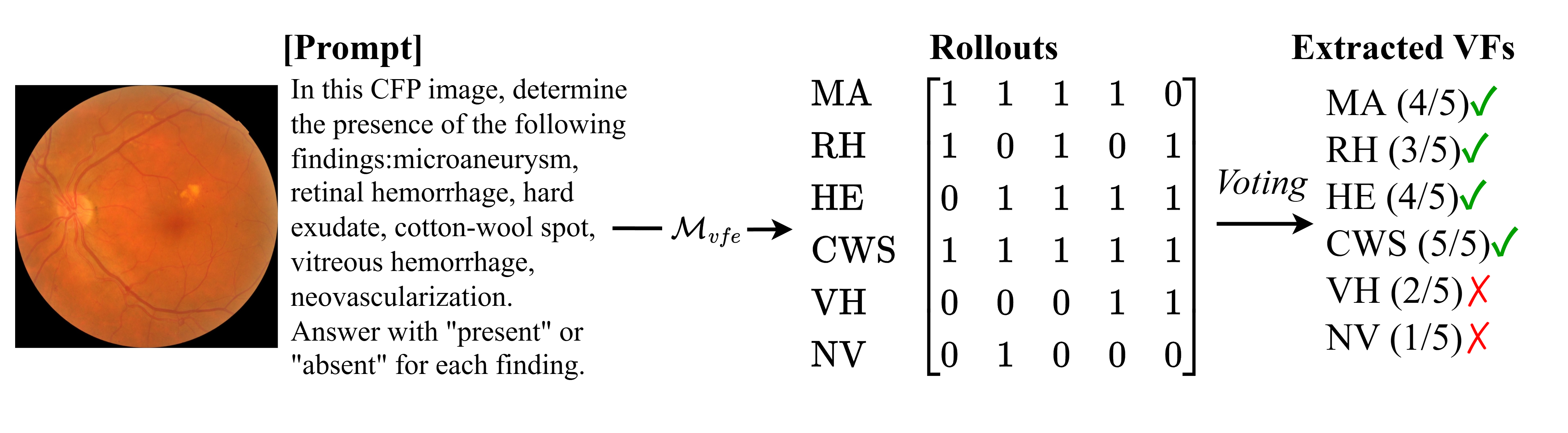

Figure 1: Label-and-modality-specific domain knowledge acquisition and VF vocabulary formation, emphasizing the structured capture of clinical evidence.
- Image-Specific Visual Finding Extraction: Generic MLLMs are prompted with the VF vocabulary for a given image, using rollouts and majority voting to reliably detect and aggregate present findings.
- Knowledge-Aware Reasoning Trace Composition: The LLM generates a structured reasoning trace for each image-label pair, conditioned explicitly on detected visual findings and modality-specific domain knowledge. Empirically, this yields traces that are more diagnostic, logically consistent, and verification-friendly compared to naïve chain-of-thought generations by generic MLLMs.
Through this pipeline, the authors automatically generate over 80k high-quality reasoning traces for public fundus datasets, providing a crucial intermediate supervision signal.
Reinforcement Learning with Process Reward
The second principal contribution is an enhancement of RLVR training by introducing an answer-dependent process reward rpro. Standard RLVR in prior work (e.g., OphthaReason) rewards correct answers and proper formatting but does not directly incentivize the faithfulness and diagnostic validity of the reasoning process. The Fundus-R1 framework addresses this by including a process reward computed as follows:
- For correct answers y^i=y, rpro verifies the logical plausibility and self-consistency of the reasoning trace τ w.r.t. the extracted visual findings VF[I].
- For incorrect answers, rpro checks trace plausibility against domain knowledge DK[y^i,m] associated with the predicted label.
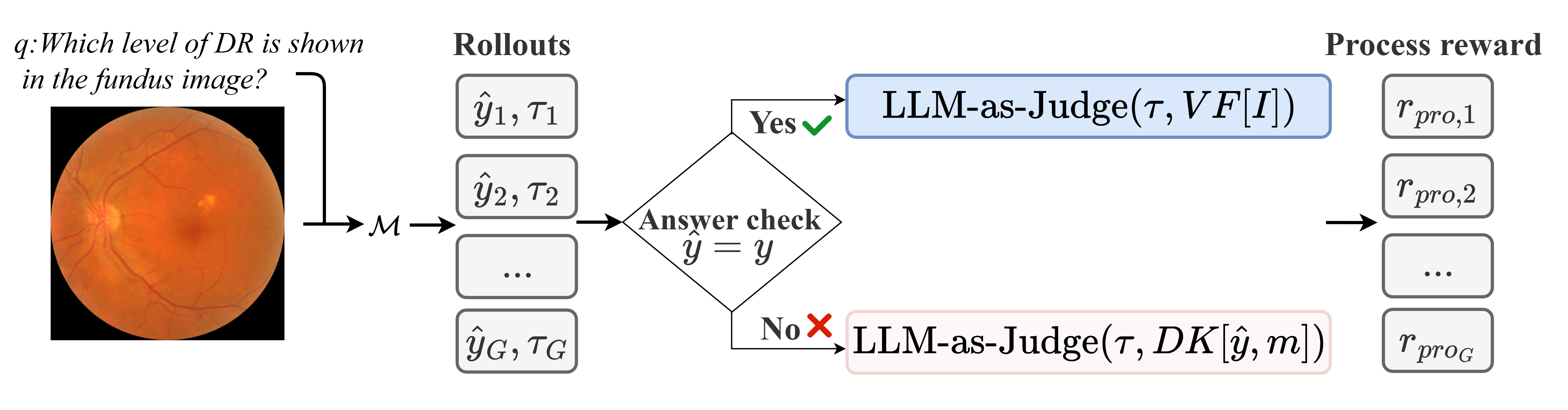





Figure 2: Answer-dependent process reward computation, operationalizing trace quality assessment via LLM-as-judge.
This reward is implemented through LLM-as-judge prompts that annotate traces as plausible, tenuous, or flawed, and assigns reward values accordingly. This approach encourages the model to align its reasoning processes with expert clinical patterns, even for intermediate (incorrect) outputs—addressing reward hacking and optimizing diagnostic reasoning.
Empirical Results and Analysis
Fundus-R1 is trained in a two-stage SFT + RLVR pipeline on public datasets. Evaluations on three fundus-reading benchmarks: FunBench, Omni-Fundus, and GMAI-Fundus, demonstrate the following:
- Incorporation of Reasoning Traces: Models trained with the reasoning-trace-augmented pipeline consistently outperform those using answer-only supervision, with Fundus-R1 achieving substantial performance boosts, especially in high-level reasoning tasks such as disease diagnosis and lesion analysis.
- Process Reward Efficacy: The process reward proves particularly effective in diagnosis and lesion-oriented subtasks, improving both answer quality and reasoning trace conciseness. Removal or simplistic summation of VF and DK items in reward computation leads to clear performance degradation.
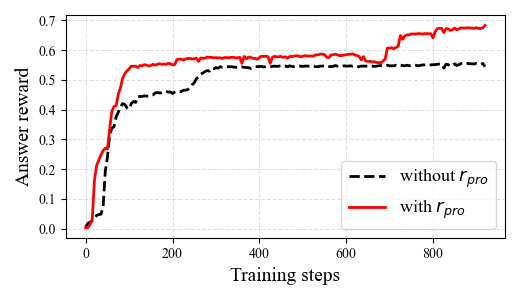
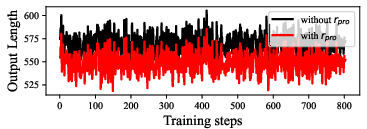
Figure 3: Influence of process reward y0 on answer reward and output length—demonstrating improved learning dynamics and efficiency.
- Benchmark Comparison: Fundus-R1 surpasses generic MLLMs (Qwen2.5-VL, InternVL2.5-8B), SFT-based medical MLLMs (HealthGPT-M3-7B, Lingshu-7B), and RLVR-based specialized models (Med-R1-fundus, FundusExpert-8B, OphthaReason). Fundus-R1-7B pushes overall benchmark scores into the 70+ range, despite training on public data and modest (3B/7B) backbone capacity.
- VF Extraction Quality: The pipeline for visual finding extraction delivers higher sensitivity and specificity compared to naïve chain-of-thought approaches, indicating effective knowledge grounding for trace generation.
Practical and Theoretical Implications
This work establishes that knowledge-aware reasoning traces can be auto-generated from public image-label pairs via RAG and LLM extraction, and that RLVR training with process rewards can substantially improve the reasoning capability of fundus-reading MLLMs. Practically, this opens the possibility for reproducible, accessible ophthalmic AI research—reducing dependence on proprietary data. Theoretically, the framework demonstrates the value of disentangling visual evidence from domain knowledge and incorporating trace verification into RL pipelines.
These principles are directly extensible to other knowledge-intensive medical imaging domains, and the solution is anticipated to generalize to larger-scale, more powerful MLLM backbones. The approach aligns with emerging research directions in process reward modeling [zhang2025r1], multimodal reasoning [wang2025visualprm, hu2025prm], and data-efficient medical LLM adaptation [xu2025lingshu, pan2025medvlm].
Future Directions
The demonstrated process reward mechanism invites further exploration of more granular or task-adaptive process supervision, potentially integrating external expert judgments or leveraging new forms of automated trace verification. Expanding the VF vocabulary to cover other modalities or rare pathologies, and scaling the approach to larger MLLM architectures, will drive advances in automated medical reasoning. The pipeline suggests principled avenues for auto-generating domain-specific reasoning traces when only coarse public labels exist, leveraging retrieval, extraction, and RL at scale.
Conclusion
Fundus-R1 offers a knowledge-aware, process-reward-enhanced framework to train fundus-reading MLLMs exclusively on public datasets. By systematically generating intermediate reasoning traces and leveraging answer-dependent process rewards, Fundus-R1 achieves diagnostic reasoning capabilities that notably surpass generic and specialized baselines. The approach advances reproducible multimodal clinical AI and sets new benchmarks for trace-driven RLVR in medical imaging domains (2604.08322).

