- The paper demonstrates a novel OCR pipeline using vision language models and parameter-efficient fine-tuning on Qwen2.5-VL 3B for robust Darija text recognition.
- The model achieves state-of-the-art results with optimal LoRA hyperparameters, significantly reducing evaluation loss and resource consumption.
- The hybrid synthetic-real dataset and the dedicated AtlasOCRBench benchmark validate the system’s effectiveness for both Darija and standard Arabic OCR tasks.
Expert Summary of "AtlasOCR: Building the First Open-Source Darija OCR Model with Vision LLMs" (2604.08070)
Introduction and Motivation
AtlasOCR addresses a substantial gap in automatic text recognition for Darija, the Moroccan Arabic dialect, which is underrepresented in OCR and NLP research. The paper formally introduces the AtlasOCR system, a Vision LLM (VLM)-driven OCR pipeline specialized for Darija and standard Arabic, leveraging a parameter-efficient fine-tuning strategy on Qwen2.5-VL 3B. The authors identify the lack of curated data and dialect-specific modeling as key barriers and tackle these issues through methodological dataset design, innovative model training, and rigorous evaluation.
Model Architecture and Fine-Tuning Approach
AtlasOCR's architecture is grounded in the contemporary VLM paradigm, integrating a vision encoder, modality projection module, and a LLM, facilitating robust multimodal feature aggregation and linguistic contextualization. The vision encoder processes input images into embeddings, which are projected into the LLM's space for joint text generation and recognition tasks. The selection of Qwen2.5-VL 3B was informed by comparative benchmarking, demonstrating superior generalization for Darija and Arabic OCR.
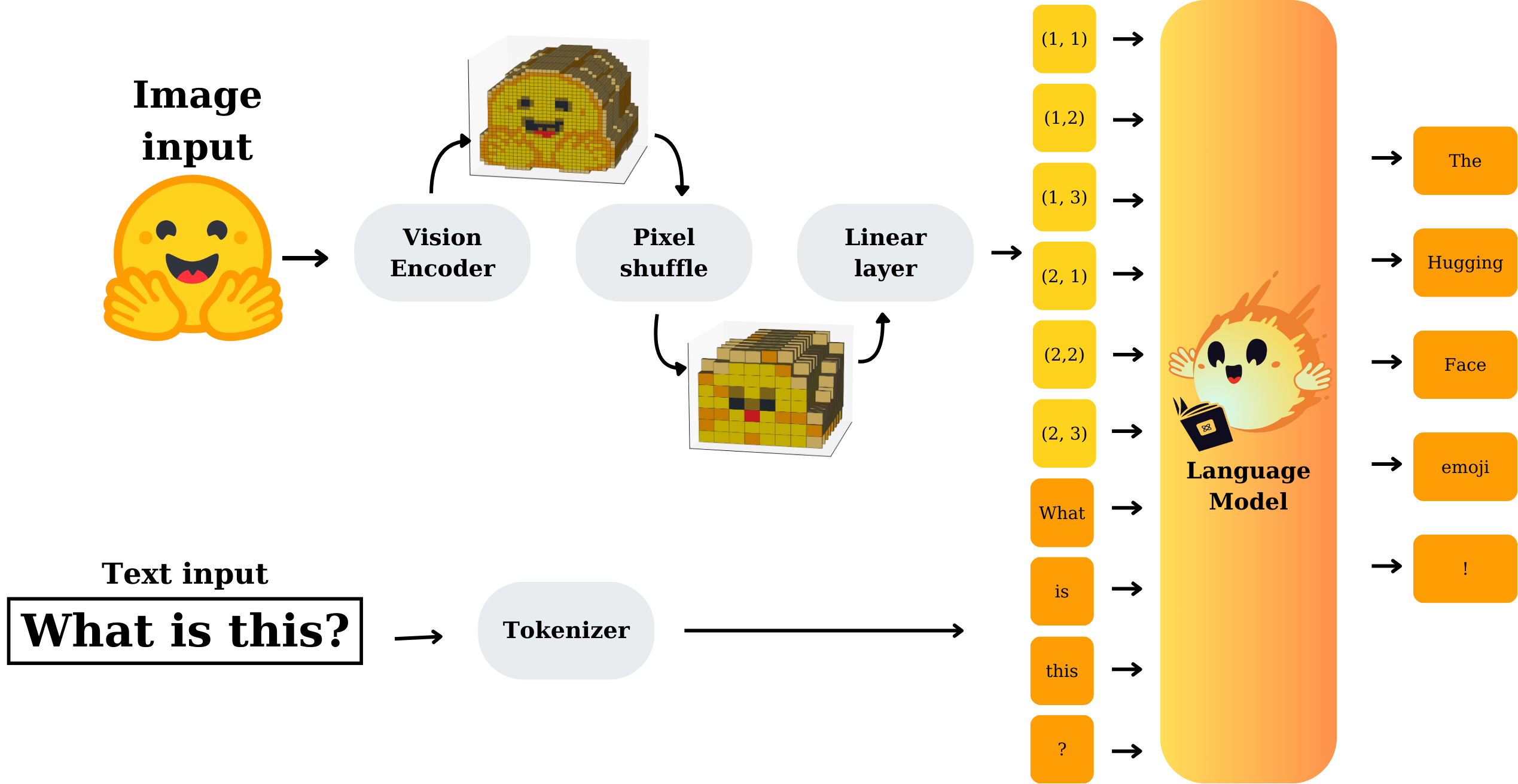
Figure 1: VLM architecture outlining the interplay of vision encoding and language modeling for multimodal text recognition.
The training routine utilized QLoRA (4-bit quantization with low-rank adaptation) paired with Unsloth optimization to maximize training efficiency and minimize resource consumption. Ablation studies reveal the benefit of increased LoRA rank and scaling factor (r=128, α=128), as well as the importance of fine-tuning vision layers; freezing these layers substantively degraded minimum evaluation loss. RSLoRA was found detrimental within this task's operational regime.
Dataset Acquisition and Synthetic Data Generation
A robust dataset is a cornerstone of successful OCR for low-resource languages. The AtlasOCR dataset was constructed using a hybrid approach, combining synthetic Darija text generated by the OCRSmith toolkit and diverse real-world samples including scanned literature, educational materials, social media posters, and recipe collections. The synthetic component constitutes a dominant fraction, enabling scale and controllable variation, while real-world samples capture authentic character distributions and fonts.
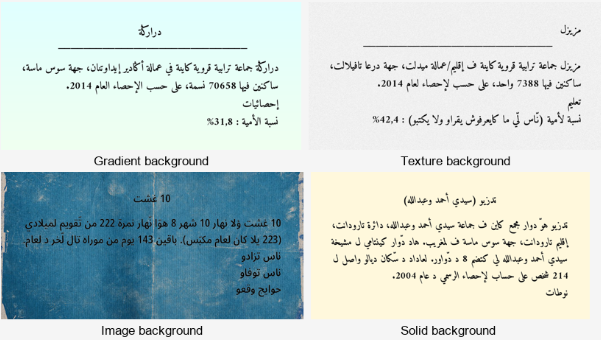
Figure 2: Synthetic Darija text examples produced with OCRSmith, illustrating controlled variability in font, layout, and distortion.



Figure 3: Scanned literary excerpts, representing high-quality print content for real-world authenticity.
Benchmark and Evaluation Pipeline
The authors developed AtlasOCRBench, the first benchmark designed for evaluating Darija OCR, encompassing both synthetic and real scanned samples. The benchmark creation pipeline involves Gemini 2.0 Flash pseudo-labeling followed by manual annotation, ensuring high fidelity in the ground truth.

Figure 4: Benchmark pipeline, combining automated pseudo-labeling and collaborative human correction for comprehensive coverage.
Character Error Rate (CER) is prioritized as the main metric due to Darija's lack of orthographic standardization. Rigorous preprocessing (diacritic removal, whitespace normalization) ensures comparability across evaluation splits.
Experimental Results
AtlasOCR demonstrates state-of-the-art CER on AtlasOCRBench, outperforming all open-source baselines. On the established KITAB-Bench for standard Arabic, AtlasOCR's performance is competitive with substantially larger models (Gemma3 12B, Qwen2.5-VL 7B), validating both the parameter-efficient methodology and cross-dialect transfer.
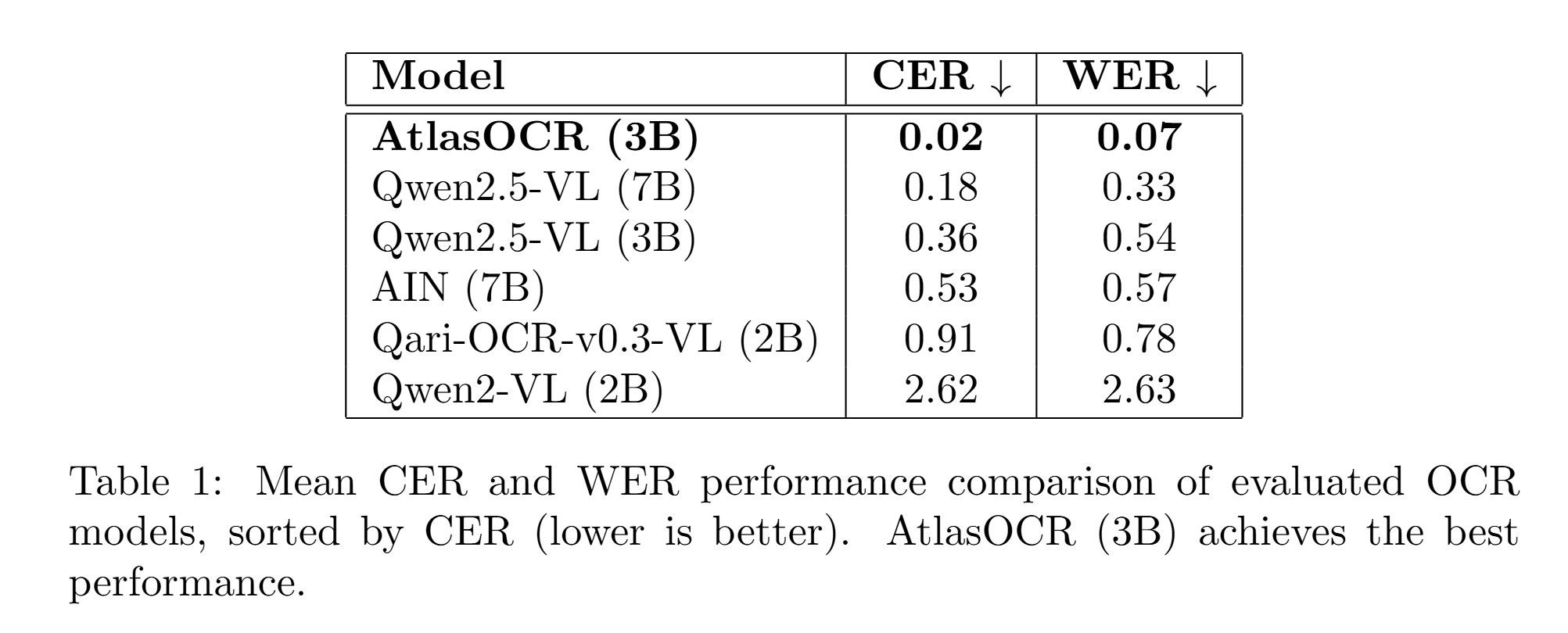
Figure 5: AtlasOCRBench leaderboard highlighting AtlasOCR's superior CER compared to open-source alternatives.
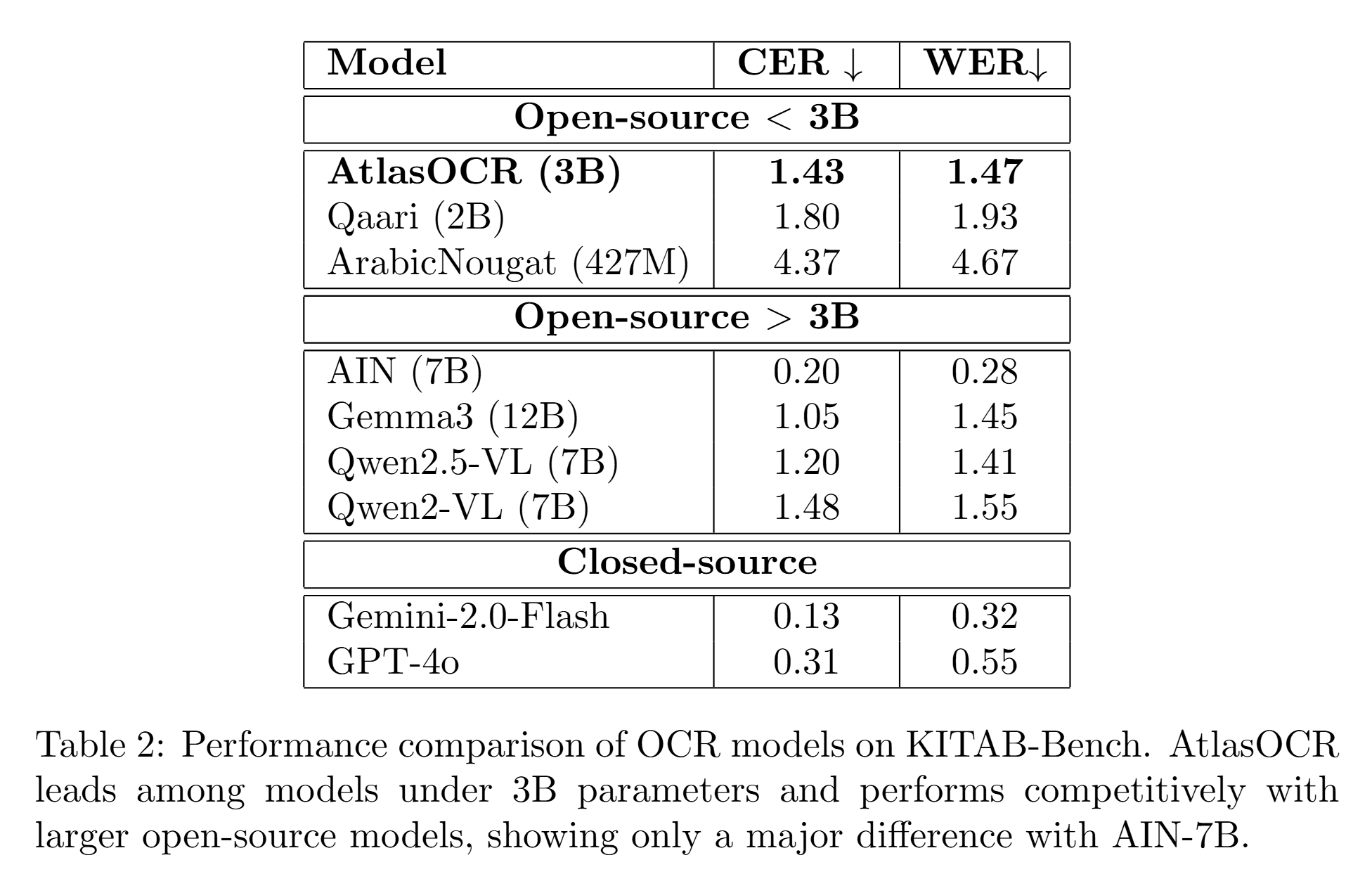
Figure 6: KITAB-Bench results where AtlasOCR competes effectively against larger models in Arabic OCR tasks.
Key findings:
- Optimal LoRA hyperparameters (r=128, α=128) yield minimized evaluation loss.
- 4-bit quantization delivers almost identical results to 16-bit precision with substantial resource reduction.
- Vision layer fine-tuning is essential; freezing these layers leads to pronounced accuracy decay.
- RSLoRA is incompatible in this context, severely impairing convergence and loss.
Discussion and Implications
AtlasOCR's empirical superiority in Darija OCR with a 3B VLM underlines the value of targeted fine-tuning and synthetic-real hybrid dataset construction for dialectal language processing. The model's competitive performance on standard Arabic, with fewer parameters, exposes the efficacy of cross-lingual transfer and parameter-efficient adaptation. Limitations include diacritic recognition, robustness to artistic or complex layouts, and domain coverage bias due to training data distribution.
The practical significance lies in democratizing access to Darija document digitization, enabling downstream NLP and accessibility tasks, and providing a methodological template for other under-resourced languages. Theoretically, the results endorse the scalability of VLM-based OCR pipelines and advocate for increased investment in dialectal model research.
Future Directions
The paper identifies several avenues for advancement:
- Expansion of the dataset to handwritten and diacritized Darija, and broader document types.
- Model compression for deployment in resource-constrained settings (sub-3B footprint).
- Advanced layout and mixed-content understanding, leveraging hierarchical vision-language architectures.
- Adaptation to other North-African Arabic dialects through transfer learning.
Conclusion
AtlasOCR sets a precedent for open-source, parameter-efficient OCR solutions in dialectal contexts, with robust empirical validation and methodological transparency. The work's impact is multifaceted, spanning practical tooling for Moroccan Arabic, foundational research in VLM model training, and open benchmarks to facilitate further advances in low-resource OCR research.

