- The paper introduces a unified taxonomy that clearly distinguishes between hypothesis generation and selection stages in abductive reasoning within LLMs.
- It benchmarks state-of-the-art models across diverse domains, revealing a significant performance gap between open-ended generation and closed-form selection tasks.
- Findings underscore the need for specialized training, richer benchmarks, and enhanced mechanistic interpretability to advance abductive reasoning in LLMs.
Wiring the 'Why': A Unified Taxonomy and Survey of Abductive Reasoning in LLMs
Introduction and Motivation
The paper "Wiring the 'Why': A Unified Taxonomy and Survey of Abductive Reasoning in LLMs" (2604.08016) addresses the pervasive fragmentation in the study of abductive reasoning within LLMs. Abduction, distinct from deduction and induction, encompasses the inference to the most plausible explanation given surprising or non-obvious observations. While recent work leverages LLMs for varied abductive tasks in commonsense, medical, legal, and multimodal domains, a cohesive definitional and methodological framework has been lacking, hampering systematic progress and comparative evaluation.
The survey sets out to establish a theoretically rigorous, empirically grounded taxonomy of abductive reasoning in LLMs, to benchmark leading models across diverse abductive tasks, and to synthesize the mapping between abductive, deductive, and inductive capabilities in current models.
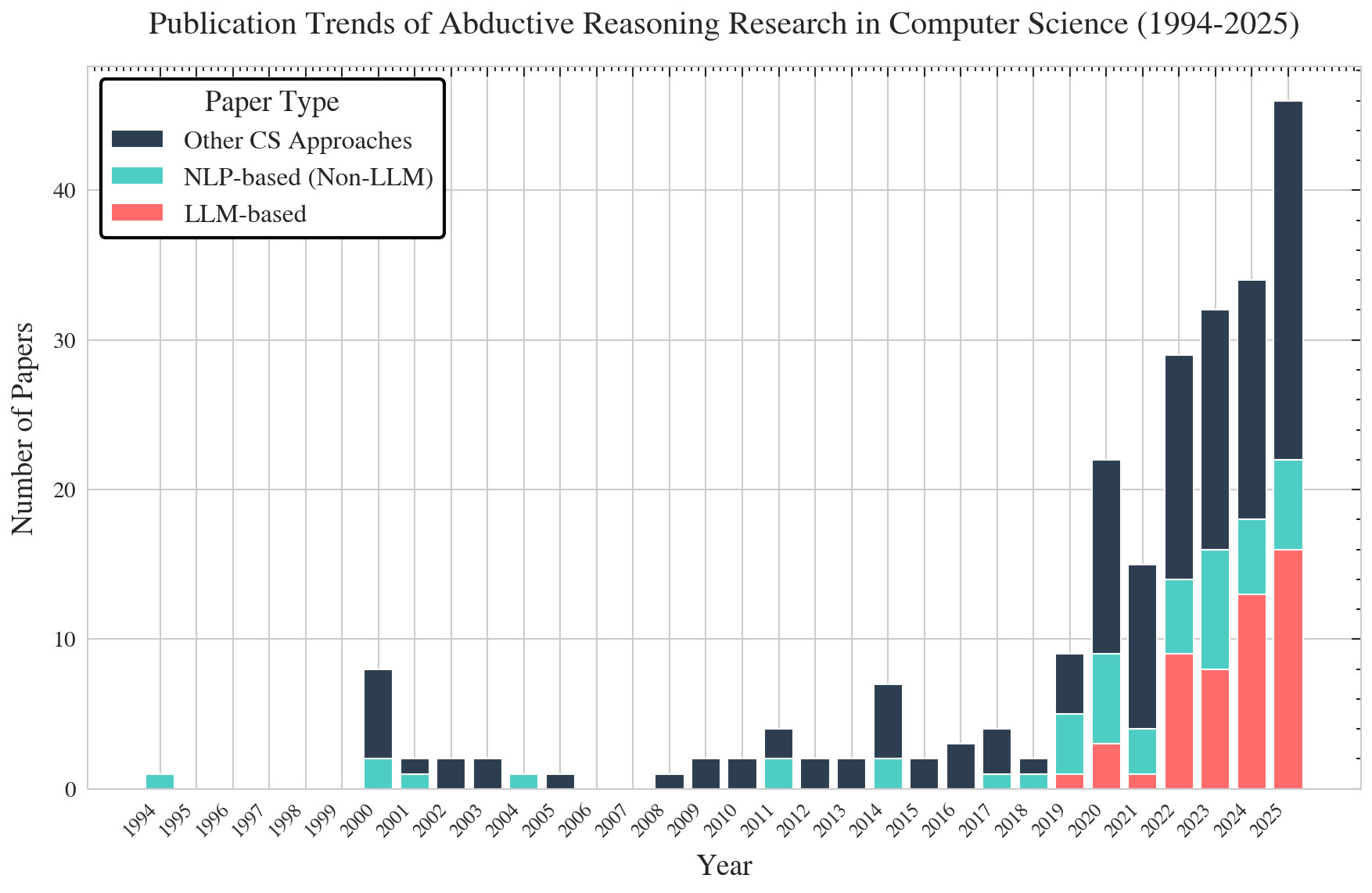
Figure 1: Publication Trends of Abductive Reasoning Research in Computer Science. The stacked bar chart shows LLM-based abduction research rapidly overtaking prior NLP and symbolic methods.
Abductive reasoning, originally systematized by Peirce, is characterized as the process of inferring hypotheses that, if true, would render an observation unsurprising. Modern treatments extend this into a two-stage process—hypothesis generation and hypothesis selection—largely formalized under Inference to the Best Explanation (IBE) in epistemology (Harman, Lipton). Peirce's original ambiguity between generation and selection remains mirrored in the diversity of computational task formulations surveyed.
The two-stage pipeline is adopted as the unifying operational definition, where:
- Hypothesis Generation: Creative or retrieval-based proposal of multiple candidate explanations for an observation.
- Hypothesis Selection: Evaluation and selection of the best hypothesis using explanatory virtues (e.g., simplicity, coherence, parsimony).
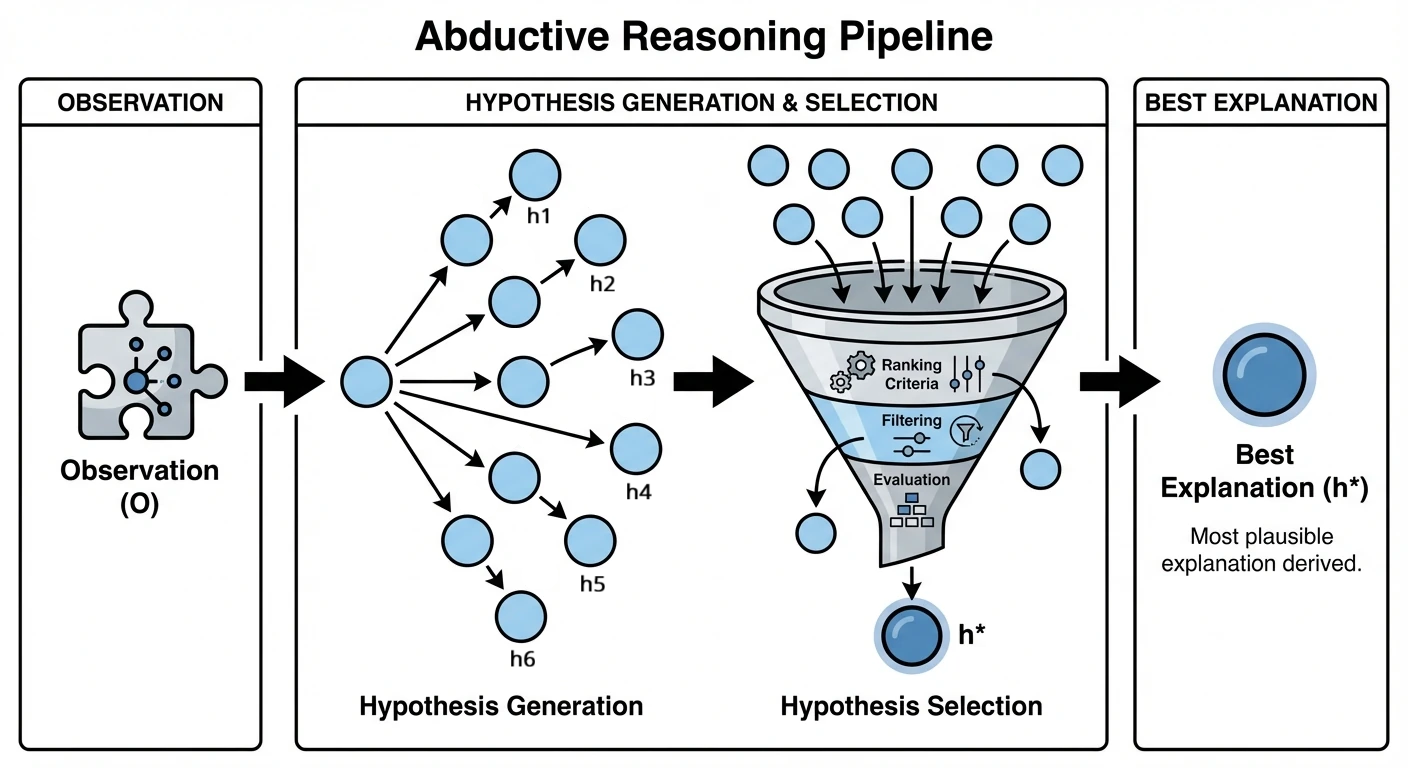
Figure 2: The abduction pipeline: observations trigger hypothesis generation (Stage I), followed by hypothesis selection (Stage II) to identify the best explanation.
This framework delineates abduction from deduction (truth-preserving, monotonic) and induction, and motivates the subsequent empirical and taxonomic analysis.
Unified Taxonomy of Abductive Reasoning in LLMs
A four-axis taxonomy is proposed, structuring the literature along (1) task formulation, (2) dataset type, (3) methodology, and (4) evaluation approach.
- Task Formulation: Distinguishes between hypothesis generation (open-form explanation or structured knowledge completion), hypothesis selection (scoring or discriminating among alternatives), and full pipeline systems.
- Dataset Type: Differentiates between commonsense, expert-domain, formal (logical/programmatic), and multimodal settings.
- Methodology: Includes prompt engineering, supervised fine-tuning, retrieval/knowledge augmentation, multi-agent decomposition, and neuro-symbolic hybrids.
- Evaluation: Encompasses accuracy-based, non-accuracy-based (e.g., explanation quality, similarity), and human-judgment-based measures.
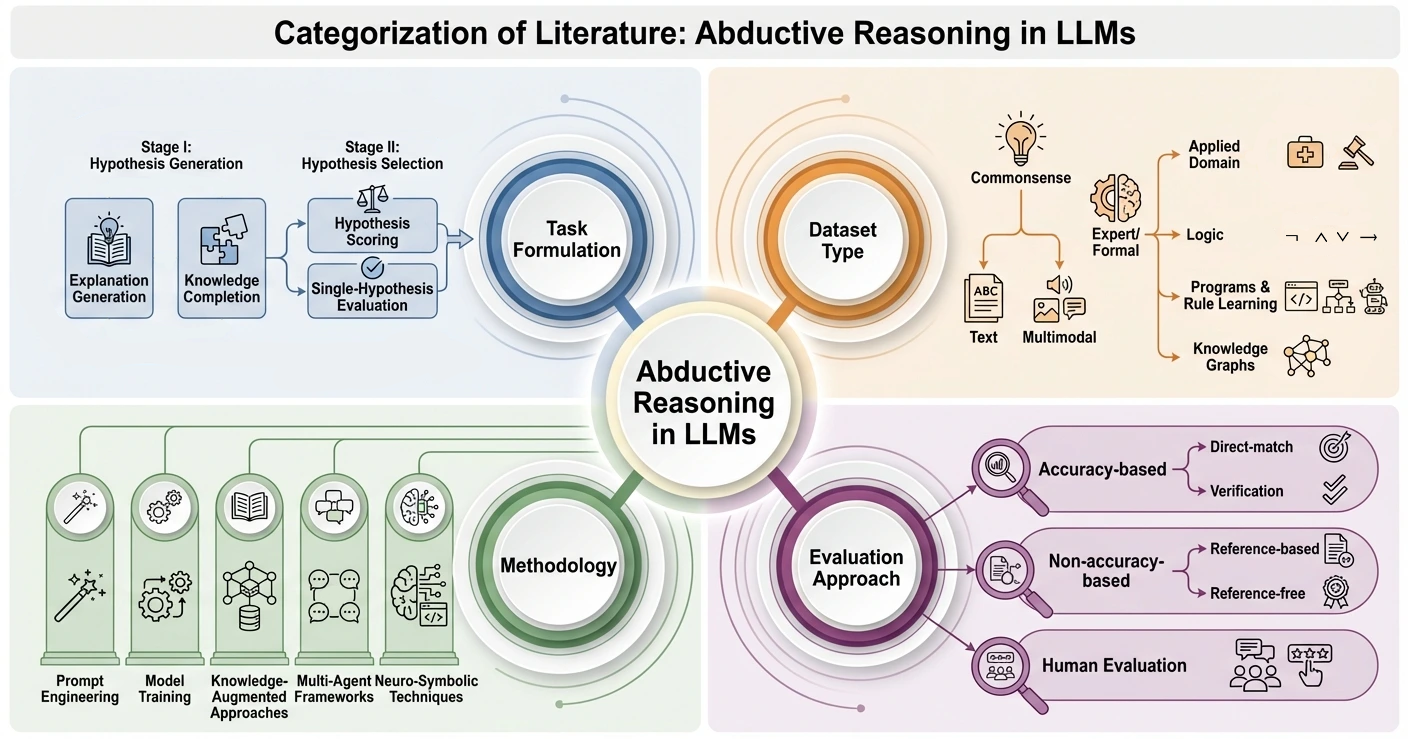
Figure 3: Literature taxonomy: abductive reasoning works are classified by task, data, method, and evaluation strategy.
This taxonomy allows rigorous comparison and uncovers the fragmentation inherent in LS (selection)-only, LG (generation)-only, and partial pipeline methods, as well as domain and evaluation biases.
Empirical Benchmarking and Model Analysis
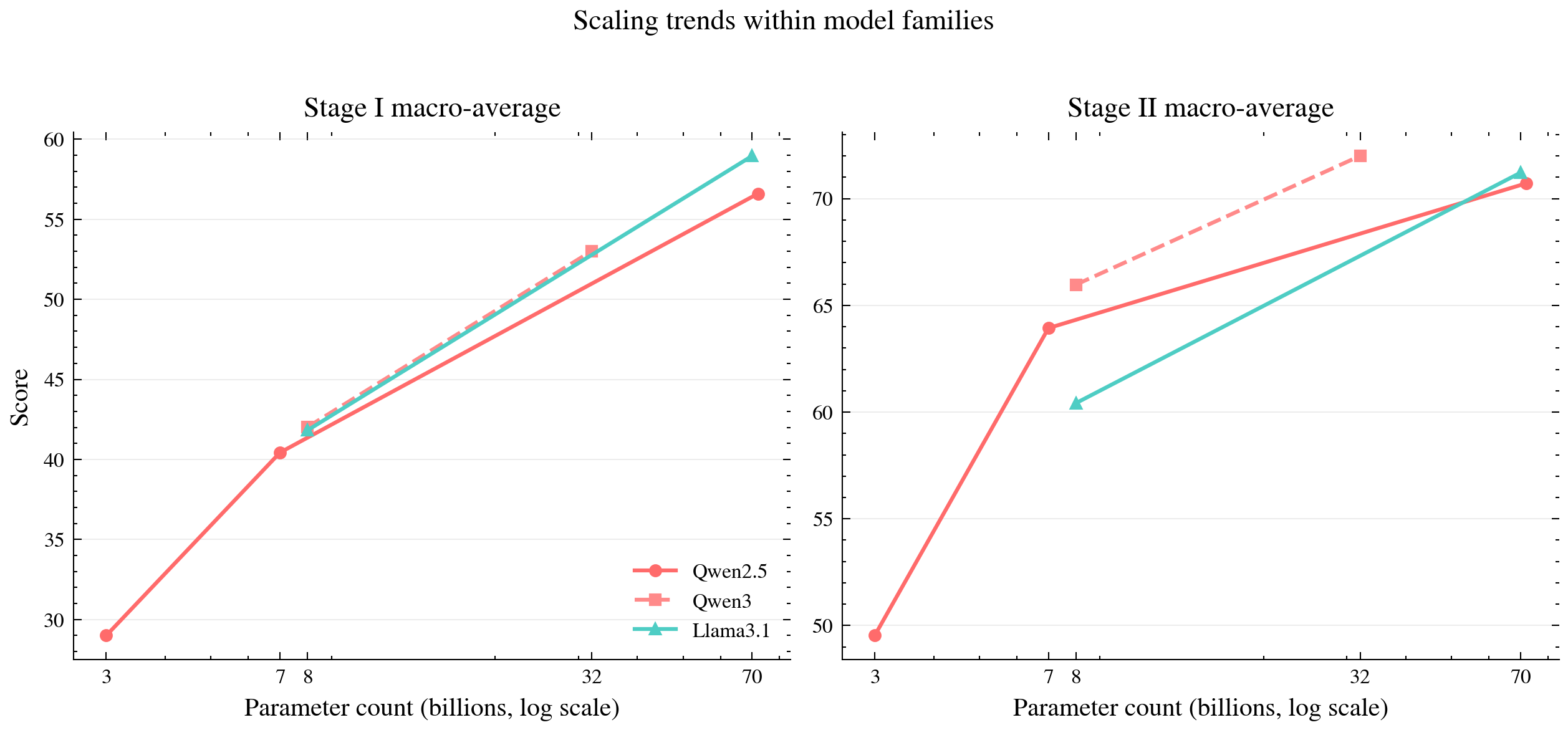
A systematic benchmarking protocol evaluates state-of-the-art LLMs (Qwen, Llama, DeepSeek, GPT-4o/5.4) on tasks covering both abductive pipeline stages and varying domains.
Stage I (Hypothesis Generation):
- Tasks: ART (bridging events), e-CARE (causal conceptualization), UNcommonsense (low-prior outcomes), DDXPlus (diagnosis explanations), formal abduction in ProofWriter/AbductionRules.
- Metrics: Validity, pairwise win rate vs. reference, BLEU/ROUGE/BERTScore, task accuracy, Levenshtein similarity.
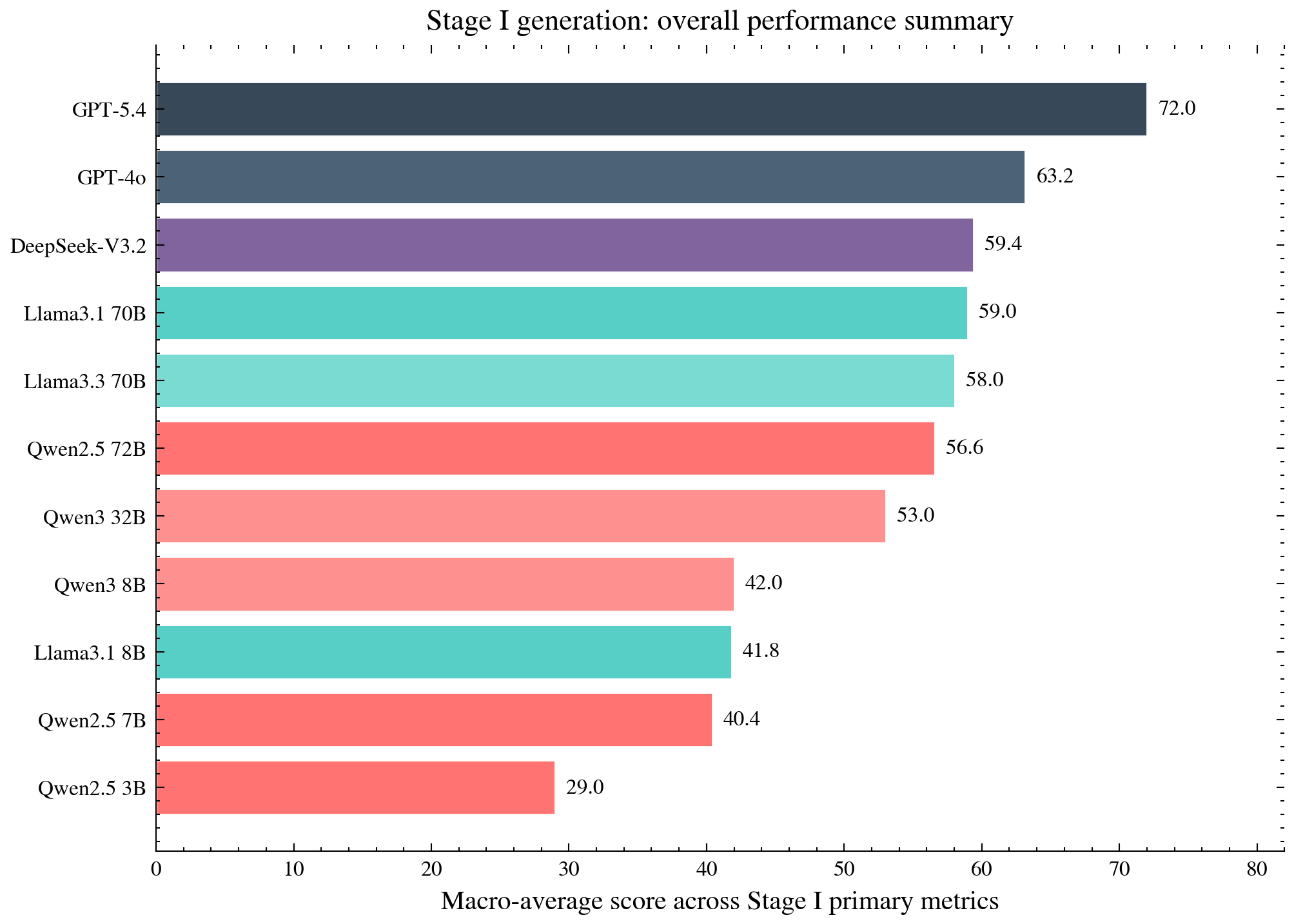
Figure 4: Macro-average performance on Stage I generation: overall, larger-scale and proprietary LLMs yield higher, but far from saturated, validity and explanation quality.
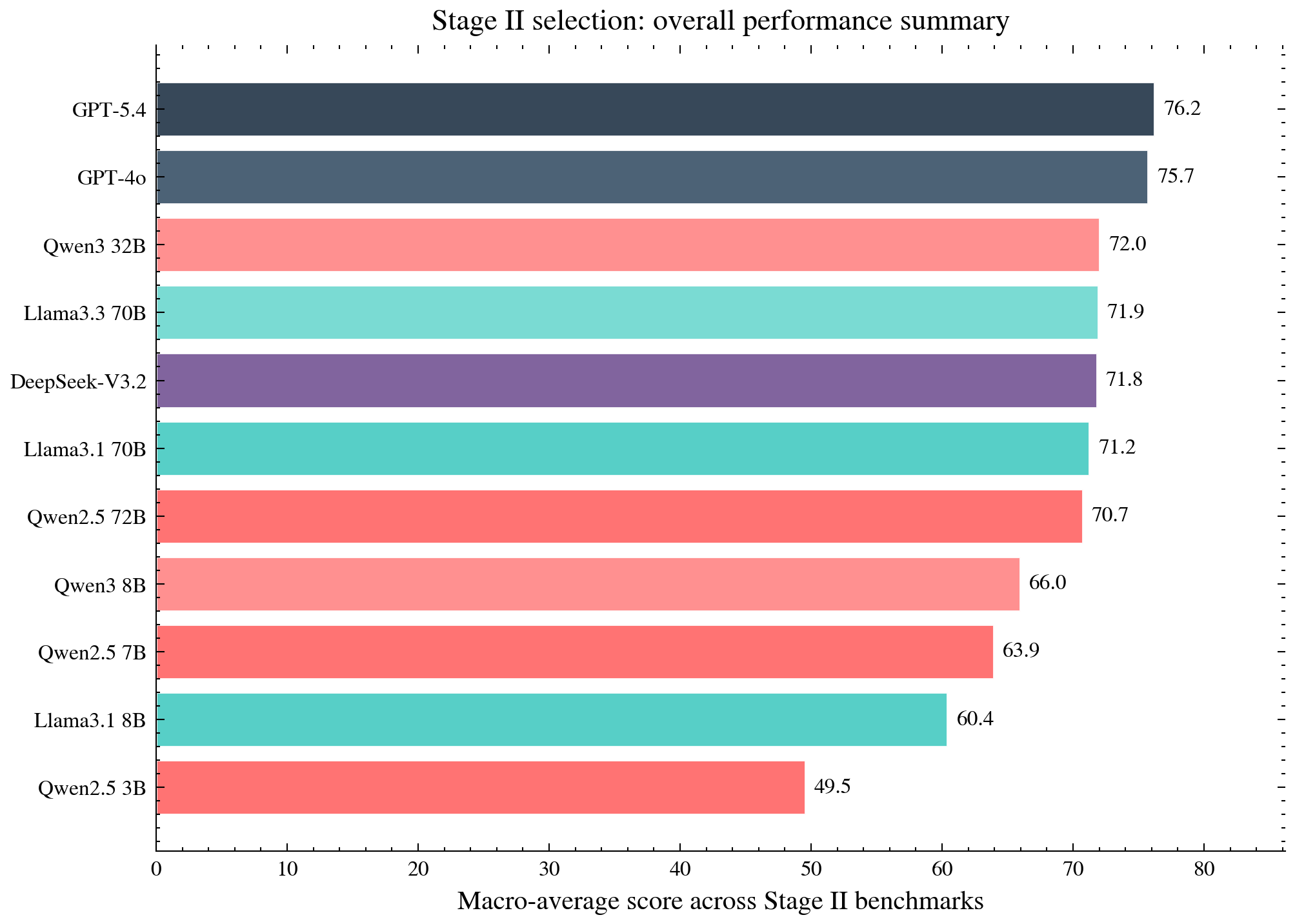
Stage II (Hypothesis Selection):
Key Observations:
Comparative Reasoning Analysis: Abductive, Deductive, Inductive
The paper aggregates cross-benchmark results—paired on identical models, methods, and datasets—across abduction, deduction, and induction.
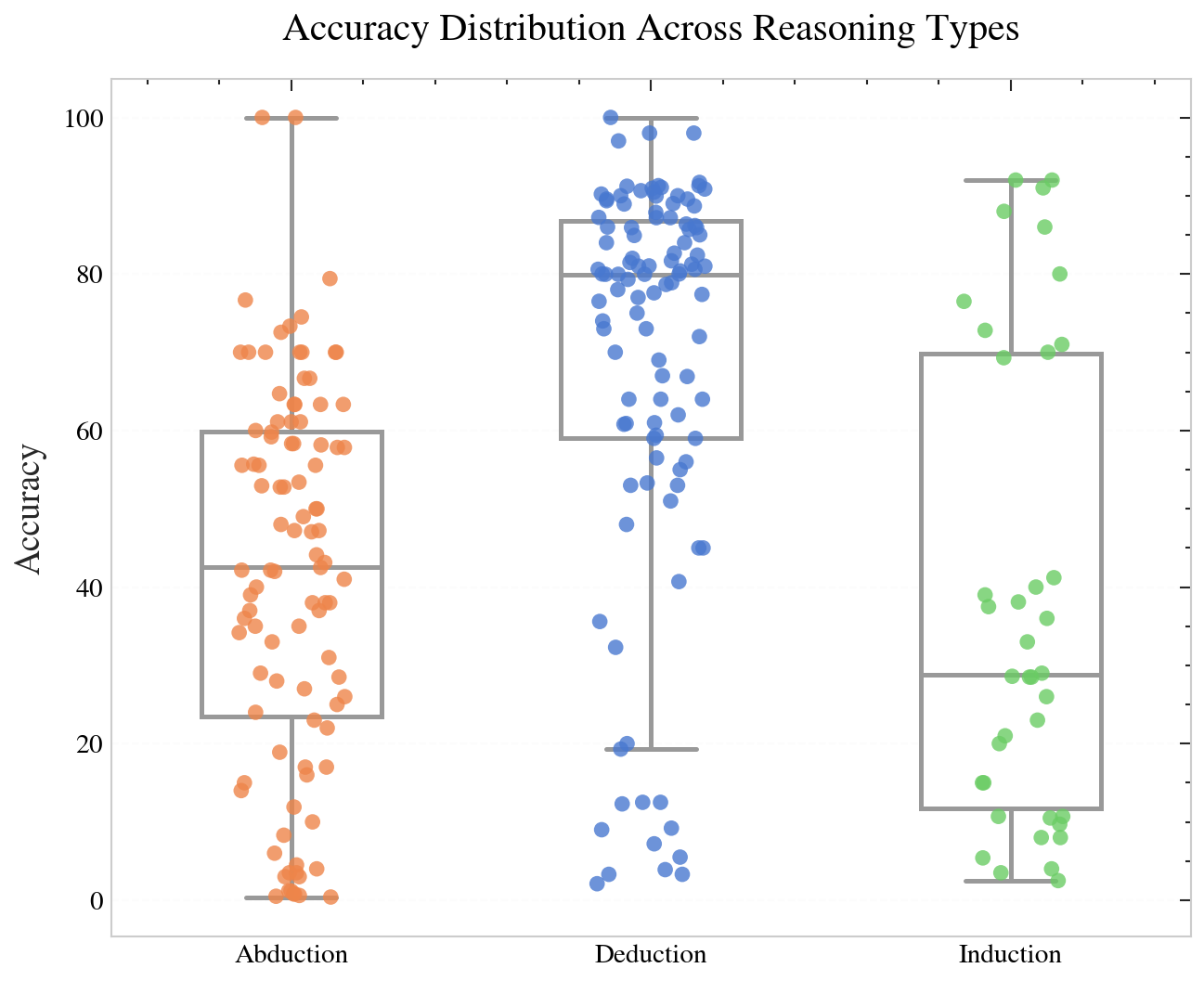
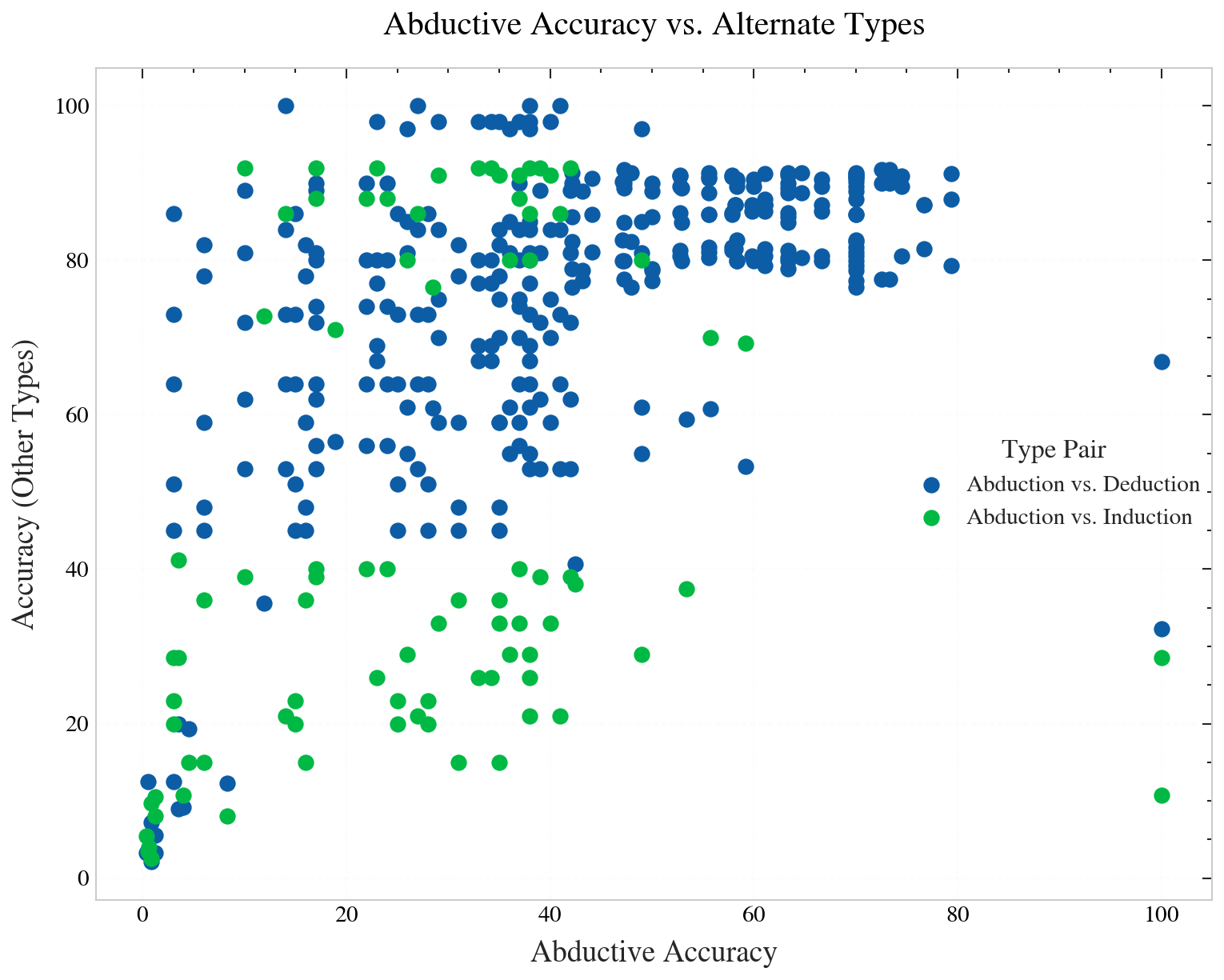
Figure 7: Reasoning type accuracy distributions: deduction outperforms abduction and induction, which lag with lower means and greater variance.
- Deduction exhibits both higher median accuracy and lower variance compared to abduction and induction.
- Abduction does not correlate strongly with either deduction or induction: strong deductive performance in LLMs does not predict abductive competence.
- Inductive scores demonstrate still greater variance and lower medians, but also appear uncorrelated with abductive performance.
These findings contradict the assertion that strong general logical reasoning in LLMs subsumes abductive performance, underscoring the necessity of abductive-specific training and benchmarks.
Identified Gaps and Critical Challenges
The survey delineates several bottlenecks for abductive reasoning in LLMs:
- Conceptual Fragmentation: Lack of a unified operational definition obstructs methodological and empirical progress.
- Dataset Limitations: Over-reliance on static, one-shot, and narrow-breadth benchmarks (e.g., two-sentence bridges) fails to capture the complexity and iterative nature of practical abduction. Multistep, action-oriented, and context-evolving settings are rare.
- Domain Narrowness and Disconnection: Most benchmarks are stylized, lacking robust coverage of domains where abduction is central (e.g., law, medicine, scientific discovery, IT troubleshooting).
- Accuracy–Reasoning Discrepancy: Improvements in benchmark accuracy often reflect better pattern-matching or answer selection rather than genuine explanatory inference or hypothesis generation capability.
- Methodological Stagnation: SFT and prompting dominate; reinforcement learning, especially reward-aligned with explanatory virtues, is nascent and poorly explored.
- Mechanistic Interpretability Deficit: There is minimal understanding of which circuits/components in LLMs are responsible for abduction, and little work differentiates abductive from deductive/inductive internal mechanisms.
Implications and Prospective Directions
Practical Implications
Enhanced abductive reasoning can directly impact safety-critical applications (clinical decision support, legal analysis, scientific hypothesis generation, root-cause analysis in engineering), where robust explanatory capabilities are essential.
Methodological Agenda
- RL for Explanatory Virtues: Future research should operationalize rewards for coherence, simplicity, predictive power, and diversity in RL environments, moving beyond accuracy.
- Richer Benchmarks: Next-generation datasets should target more open, multi-stage, domain-general and action-oriented abductive tasks.
- Multi-Agent/Distributed Architectures: Decomposing hypothesis generation and selection among simulated agents shows promise for enhanced diversity, justification, and robustness in abduction.
- Mechanistic Interpretability: Activation patching, causal tracing, and mechanistic probes should be applied to discriminate and intervene on abductive circuits, analogous to recent work in induction head analysis and transformer circuit discovery.
Conclusion
This work establishes a rigorous taxonomic and operational foundation for abductive reasoning in LLMs and compiles a thorough empirical synthesis. The gap between existing LLM capabilities and the goals of explanatory, creative reasoning is significant and persistent. Addressing the conceptual, empirical, and mechanistic deficits highlighted here will be essential for the realization of LLMs as reliable explanatory agents and for true integration of abductive reasoning in next-generation AI systems.