- The paper presents an intent-aware retrieval system that decomposes user queries into explicit design facets to improve exemplar matching.
- It employs a taxonomy-guided LLM parser and facet-conditioned embeddings to deliver superior retrieval accuracy and authoring efficiency compared to baselines.
- Experimental evaluations show significant improvements in recall and workflow efficiency, demonstrating reduced workload and enhanced creative support.
Intent-Aware Infographic Retrieval for Authoring Support
Infographic authoring is a complex task requiring the coordinated design of narrative flow, layout, visual style, and illustration usage. While designers often leverage existing exemplars for inspiration and reuse, prevailing retrieval systems primarily focus on topical alignment, failing to capture nuanced user intent regarding structure and style. General-purpose vision-language retrieval methods trained on natural images are unsuitable for infographics due to their multi-component, text-heavy nature. Addressing this mismatch, the paper develops an intent-aware retrieval system that decomposes user queries into multiple explicit design facets, enabling more precise alignment between user intents and retrieved exemplars.
The paper begins with a formative study to characterize how users articulate search intent for infographics. Four diverse infographic exemplars were used as stimuli (Figure 1), and fourteen participants provided both keyword-style and natural language queries for each. Qualitative coding revealed that queries often interweave multiple intent facets: content, chart type, layout, illustration, and style. Natural language queries were richer and more likely to specify design-critical facets; for example, layout and illustration usage were referenced in 39.3% and 28.6% of natural language queries, compared to only 10.7% and 5.4% for keyword queries, respectively. This motivates a retrieval approach that treats intent as a multi-facet specification rather than collapsing it into a single relevance score.
Figure 1: Four infographic exemplars used in the formative study to elicit multi-faceted search queries.
Facet co-occurrence analysis (Figure 2) demonstrates that most queries combine multiple facets, justifying the need for facet-aware retrieval mechanisms.

Figure 2: Facet co-occurrence matrix and annotated example query, showing multi-facet interplay in natural language expressions.
Intent-Aware Retrieval Framework
Building upon the intent taxonomy, the proposed retrieval system parses free-form queries into five design facets: content, chart type, layout, illustration, and style. A taxonomy-guided LLM-based parser produces facet-specific rewrites and predicts importance weights for each facet. Chart type constraints are treated as multi-choice sets; other facets are interpreted as open vocabulary and mapped to concise, facet-focused descriptions.
The retrieval pipeline integrates facet-aware text and image representations. Text embeddings are conditioned via special facet tokens; image embeddings are projected through facet-specific MLP heads. During training, synthetic facet-level supervision is constructed using ChartGalaxy, with multimodal descriptions distilled into short facet captions. Contrastive alignment is performed separately for each facet.
During inference, the system computes facet-conditioned embeddings for both query and corpus exemplars, combines facetwise similarities via weighted sum, and ranks results accordingly (Figure 3).
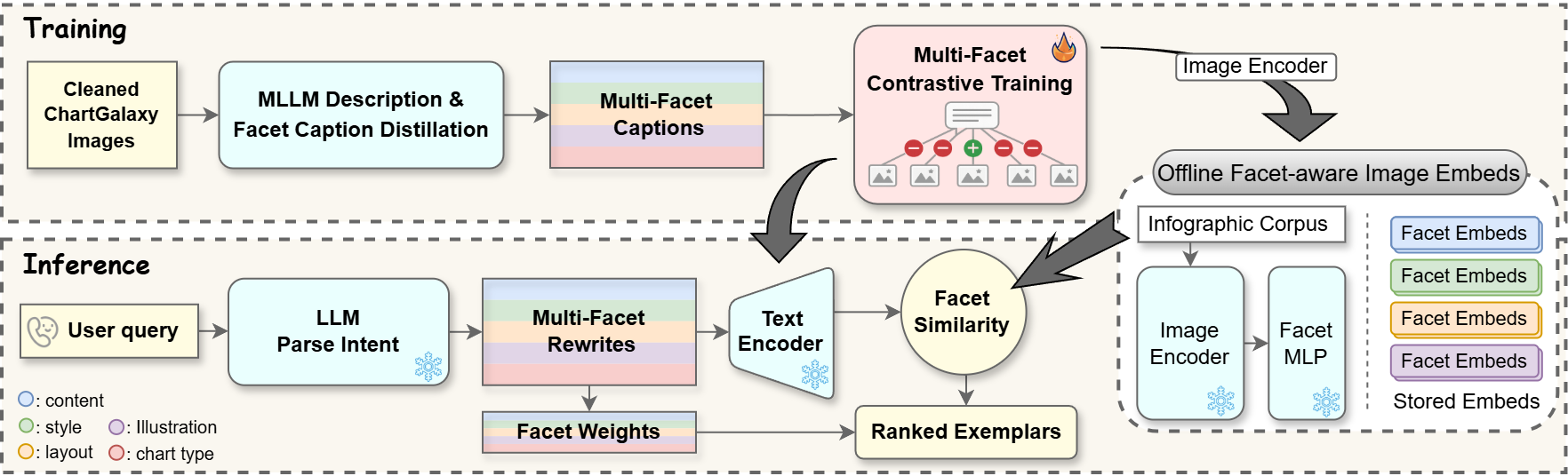
Figure 3: Overview of the intent-aware retrieval pipeline, illustrating facet parsing, embedding conditioning, and multi-facet matching.
This design facilitates fine-grained control over which aspects—such as layout or style—dominate retrieval, far surpassing generic vision-LLMs.
Integrated Conversational Authoring System
Beyond retrieval, the system incorporates end-to-end authoring support via a chat-centric interface (Figure 4). Users iteratively articulate design intent, retrieve relevant exemplars, pin them for reference, and adapt their structure to new data. SVG adaptation is facilitated by progressive context management: structural summaries are used for global reasoning, with on-demand retrieval of sanitized SVG subtrees for localized editing, overcoming context-window limitations of LLMs.
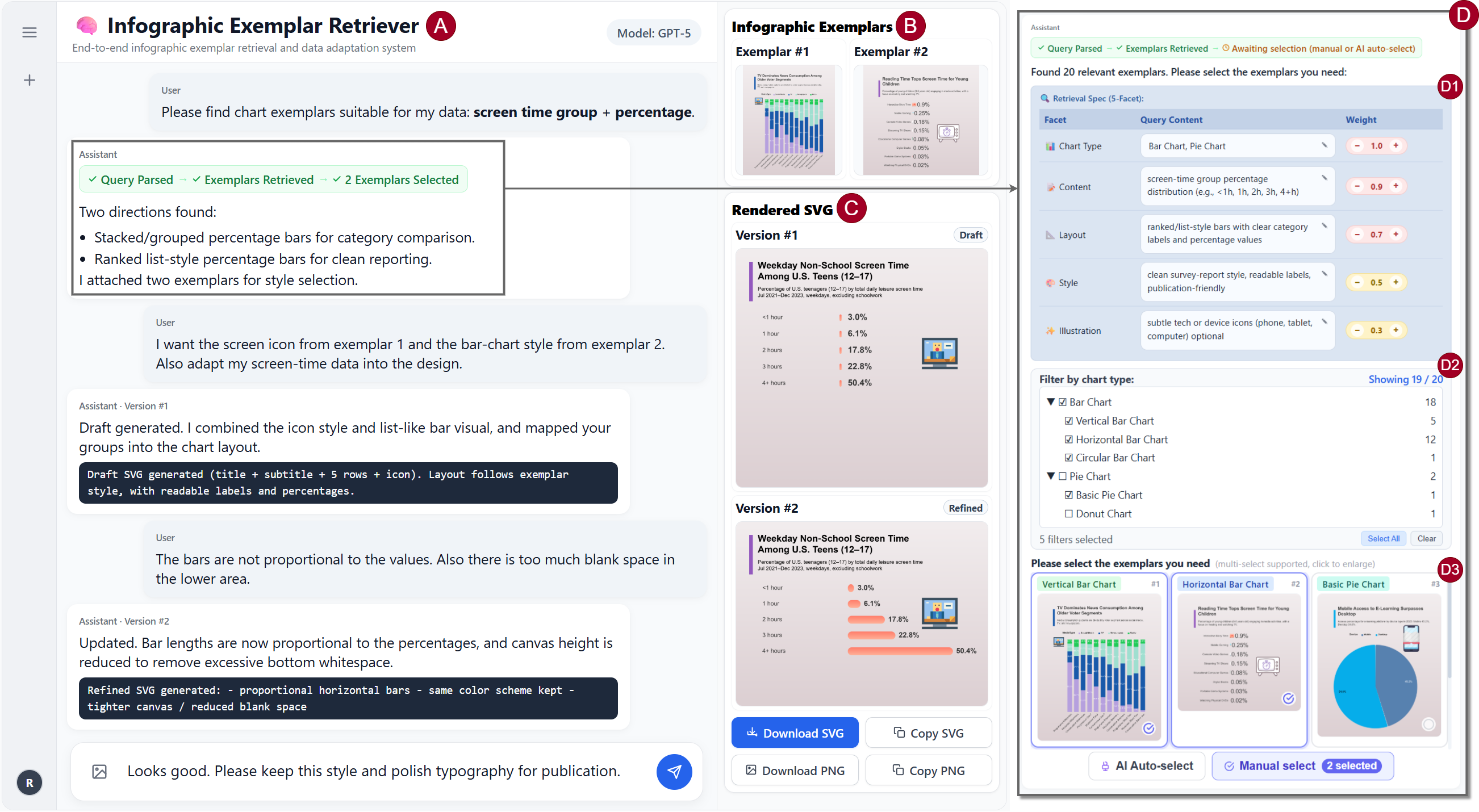
Figure 4: System UI for conversational exemplar retrieval, persistent exemplar commitment, iterative adaptation via SVG drafts, and version history.
This integrated workflow minimizes coordination overhead and enables persistent reference tracking, iterative preview, and direct mapping of high-level edit intents to concrete image modifications.
Retrieval Benchmarks
Comprehensive retrieval benchmarks across synthetic general queries, multi-facet queries, and human-written short/long queries demonstrate substantial improvements over strong baselines (CLIP, SigLIP2, MegaPairs). On human-written long queries, Recall@1 reached 70.33% for the proposed method, compared to 50.33% for MegaPairs and 41.00% for CLIP. Human judgment studies further confirmed better intent match and exemplar usefulness, with 57.3% of paired comparisons favoring the proposed approach and only 5.3% favoring MegaPairs.
Multi-Round Interactive Search
Multi-round user studies showed that the intent-aware retriever nearly doubled exact-match retrieval rates (91.7% vs. 45.8%) relative to single-facet baselines, reduced rounds to completion, and improved satisfaction ratings (mean 6.88 vs. 5.50 out of 7).
Retrieval-Based Authoring
End-to-end authoring sessions with twelve participants found statistically significant reductions in workload (mean NASA-TLX 7.88 vs. 11.23, p=0.034) for the integrated system, with higher output preference rates in blind peer review. Participants highlighted increased ease of use, lower manual overhead, and better ideation and first-draft support, though noted adaptation pipeline fragility and limitations in low-level edit fidelity.
Implications and Future Directions
The results underscore the necessity of explicit facet modeling for infographic retrieval, especially as LLM-powered authoring support matures. The pipeline's multi-facet architecture provides practical improvements in both retrieval accuracy and authoring efficiency. Theoretical implications include the formalization of intent decomposition in design retrieval and the utility of in-domain facet-level alignment over generic multimodal embeddings.
Remaining challenges concern adaptation fidelity and creative exploration in downstream workflows. Future developments may focus on robust SVG editing, constraint-aware modification planning, and seamless handoff to professional design tools for high-fidelity refinement. The compositional facet approach may generalize to other structured creative domains (e.g., UI prototyping, graphic layouts) leveraging exemplar-based inspiration and iterative adaptation.
Conclusion
This work presents an intent-aware infographic retrieval and authoring framework combining multi-facet query parsing, facet-aware embedding alignment, and integrated conversational adaptation. Empirical results establish strong improvements over state-of-the-art baselines in both retrieval quality and authoring throughput, moving infographic support tools beyond topical search toward explicit intent satisfaction and exemplar-centered workflows. The approach positions itself as a robust foundation for future AI-powered visual design systems, with potential applicability across complex, multi-component creative tasks.

