- The paper introduces a metacognitive evolutionary programming framework that enables LLMs to systematically evolve heuristics for VRP solvers.
- It leverages a structured Reason-Act-Reflect cycle and domain-aware initialization to refine key Hybrid Genetic Search components, achieving cost reductions up to 2.70%.
- Experimental results validate that evolved modules improve solution quality and runtime efficiency while demonstrating broad generalization across diverse VRP variants.
Context and Motivation
Metaheuristics are the dominant paradigm for tackling large-scale Vehicle Routing Problems (VRPs), but their optimal configuration—especially within state-of-the-art frameworks like Hybrid Genetic Search (HGS)—has always depended on iterative manual design and domain-specific intuition. Recent LLM-driven evolutionary frameworks, such as FunSearch and AlphaEvolve, have begun automating this process, yet they primarily operate as reactive, feedback-driven code mutators without strategic reasoning. The paper "PyVRP+: LLM-Driven Metacognitive Heuristic Evolution for Hybrid Genetic Search in Vehicle Routing Problems" (2604.07872) introduces Metacognitive Evolutionary Programming (MEP), a framework that compels LLMs to reason systematically, diagnose failures, hypothesize improvements, and critically reflect within the design cycle. This refines LLMs from mere code generators into strategic agents for algorithmic discovery, facilitating the evolution of heuristics for core HGS components that achieve measurable advances over hand-crafted baselines.
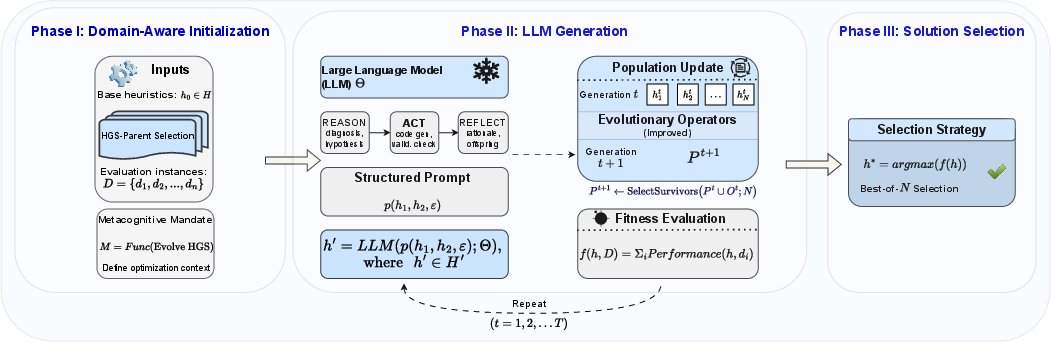
Figure 1: MEP's schematic shows iterative heuristic evolution with explicit strategic reasoning and final selection of the highest-performing candidate.
Methodology
MEP’s process comprises two interlinked phases:
Domain-Aware Initialization: The LLM is primed with structured knowledge bases for each component undergoing evolution: known pitfalls (Kp), mitigation strategies (Ks), and domain-specific traps (Kt). These inform reasoning and anchor design in established CO theory and VRP-specific subtleties.
Reason-Act-Reflect Cycle:
- Reason: The LLM diagnoses observed weaknesses in parent heuristics, referencing the strategic knowledge base, before code generation.
- Act: Proposes a concise design hypothesis and implements it as a new heuristic module, adhering to PyVRP’s modular constraints.
- Reflect: Documents rationale, critiques limitations, and suggests revisions, embedding metacognitive evaluation within the code artifacts, propagating lessons into subsequent generations.
This cycle mandates a hypothesis-driven approach, enforcing deliberate reasoning and self-improvement rather than random mutation.
Experimental Framework
MEP evolves three critical HGS components: parent selection (select_parents), survivor selection (select_survivors), and penalty adjustment (update_penalties), directly affecting exploration/exploitation dynamics and constraint handling. The PyVRP library’s modular design enables isolated evaluation and rapid integration of LLM-generated functions. Evolutionary search is conducted over ten generations, with population selection favoring individuals evaluated across diverse TSP100 instances and six VRP variants for generalization robustness. The LLM (GPT-4.1) is prompted with detailed planning, reasoning, and reflection instructions and strict syntactic constraints.
Numerical Results and Heuristic Discovery
MEP achieves statistically significant performance improvements on the TSP100 benchmark, with the evolved select_parents and select_survivors modules demonstrating average cost reductions of 2.23% and 0.69% compared to the PyVRP baseline. All evolved components outperform their hand-designed counterparts (Table~\ref{tab:component_fitness}).
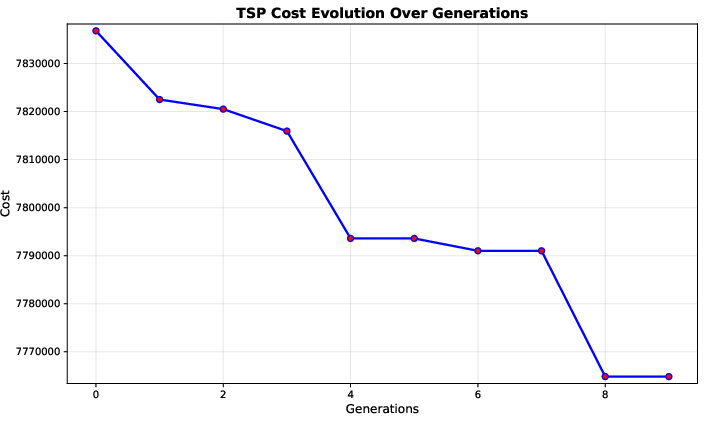
Figure 2: TSP cost evolution curve displays consistent improvement and convergence across MEP generations—averaged on 100 instances.
Integrated HGS solvers employing all MEP-evolved modules realize synergistic effects: VRPTW and PCVRPTW variants display cost reductions up to 2.70%, and runtime shrinks by >45% on PCVRPTW, attesting to both algorithmic innovation and practical efficiency. Ablation studies reveal the full MEP process outperforms simpler, reactive evolution baselines (analogous to EoH and ReEvo), indicating that structured metacognitive scaffolding is essential for non-trivial improvements in complex, modular solvers. Importantly, none of the MEP-evolved modules degrade performance on independent variants, demonstrating strong cross-distribution generalization.
Strong Claims and Contradictions
- Heuristics evolved by MEP outperformed original HGS baselines by up to 2.70% in solution quality and by over 45% in runtime reduction on challenging VRP variants.
- Reactive feedback-driven evolutionary paradigms are insufficient for modular metaheuristic solvers; structured metacognitive reasoning is essential for scalable algorithmic innovation.
- Contradicting prior LLM-based CO approaches, MEP demonstrates significant gains on sophisticated, compositional solvers instead of only elementary heuristics or neural policies.
Theoretical and Practical Implications
MEP elevates LLM-driven heuristic evolution by enforcing explicit reasoning, domain grounding, and self-reflective critique—shifting the paradigm from feedback-mutation to hypothesis-driven discovery. This unlocks non-trivial, synergistic improvements within modular SOTA frameworks and enables efficient condensation of the manual design cycle into automated LLM workflows. The approach is extensible to diverse CO domains and modular optimization environments; it is practical for scalable deployment, given manageable one-time design costs and persistent reductions in inference runtime.
MEP's strategic reasoning cycle parallels advances in AI agentic research, offering a bridge between metacognitive construction hyper-heuristics and scientific discovery systems (e.g., AI Scientist, MLGym). Its impact is twofold: advancing the efficacy and efficiency of VRP solvers, and laying the groundwork for next-generation, autonomous algorithm design agents capable of systematic improvement.
Future Directions
Joint evolution of entire solver architectures, cross-component synergy modeling, and rigorous benchmarking across all PyVRP variants are natural follow-ups. Open-source LLMs capable of complex reasoning and strict code generation could further democratize MEP's methodology. Extending metacognitive reasoning to other NP-hard CO problems and integrating reinforcement learning-based fine-tuning are compelling research avenues.
Conclusion
MEP enables strategic, LLM-driven evolution of modular heuristics within state-of-the-art VRP solvers, delivering statistically robust improvements in both solution quality and computational efficiency. Its structured Reason-Act-Reflect cycle underscores the necessity of metacognitive scaffolding for complex algorithmic discovery, outperforming extant reactive paradigms and demonstrating generalizability across diverse combinatorial settings. The practical and theoretical advances establish MEP as a blueprint for future AI-driven scientific discovery systems in algorithmic optimization.

