- The paper evaluates the distinct capabilities of LLMs in translating natural language requirements into formal LTL, revealing strong syntactic performance but notable semantic gaps.
- It introduces a rigorous evaluation framework that includes atomic proposition extraction, well-formedness classification, and Python AST-based interfaces for enhanced structural validity.
- It demonstrates that even with structured prompting, LLMs struggle with temporal operator scoping and semantic equivalence, emphasizing the need for formal verification in security contexts.
Authoritative Summary: Syntax Is Easy, Semantics Is Hard — Evaluating LLMs for LTL Translation
Introduction and Motivation
The paper systematically evaluates state-of-the-art LLMs on the task of translating assertive English requirements into Linear Temporal Logic (LTL) formulas. LTL is a formalism extensively adopted for expressing requirements, security, and privacy policies in software and network systems. The manual conversion from natural language (NL) to LTL remains a major barrier due to inherent linguistic ambiguity and the complexity of temporal semantics, often impeding broader adoption of symbolic reasoning (SR) tools by practitioners. Previous approaches have relied on property specification patterns, controlled NL, or limited fragments, lacking robust, scalable evaluation and often neglecting semantic correctness. The study addresses these gaps with a rigorous framework, leveraging multiple datasets and three structured prompt interfaces to interrogate both syntactic and semantic LLM capabilities.
Evaluation Framework and Methodology
The evaluation framework decomposes NL→LTL translation into distinct subtasks:
- Atomic Proposition Extraction: Identifying minimal logical building blocks from NL requirements.
- Well-Formedness Classification: Distinguishing valid from invalid LTL formulas.
- NL→LTL Generation: Translating NL plus atomic proposition (AP) mapping to future-time and past-time LTL formulas.
- Trace Classification and Generation: Assessing trace satisfaction and generating traces for given LTL formulas.
Three interfaces enforce progressively stricter constraints: a minimal prompt (task description only), a detailed interface (BNF grammar and semantics), and a Python AST-based interface that leverages compositional structure and enforces syntactic validity. All semantic correctness is assessed using the NuSMV model checker, grounding evaluation in execution trace semantics.
Syntactic Evaluation
LLMs excel at atomic proposition extraction when guided by detailed prompts and explicit mappings, achieving F1-scores above 77%, Jaccard similarity exceeding 65%, and Levenshtein similarity over 88%. Minimal prompts lead to unreliable decomposition and frequent semantic mismatches; explicit structural guidance is critical for robust extraction.
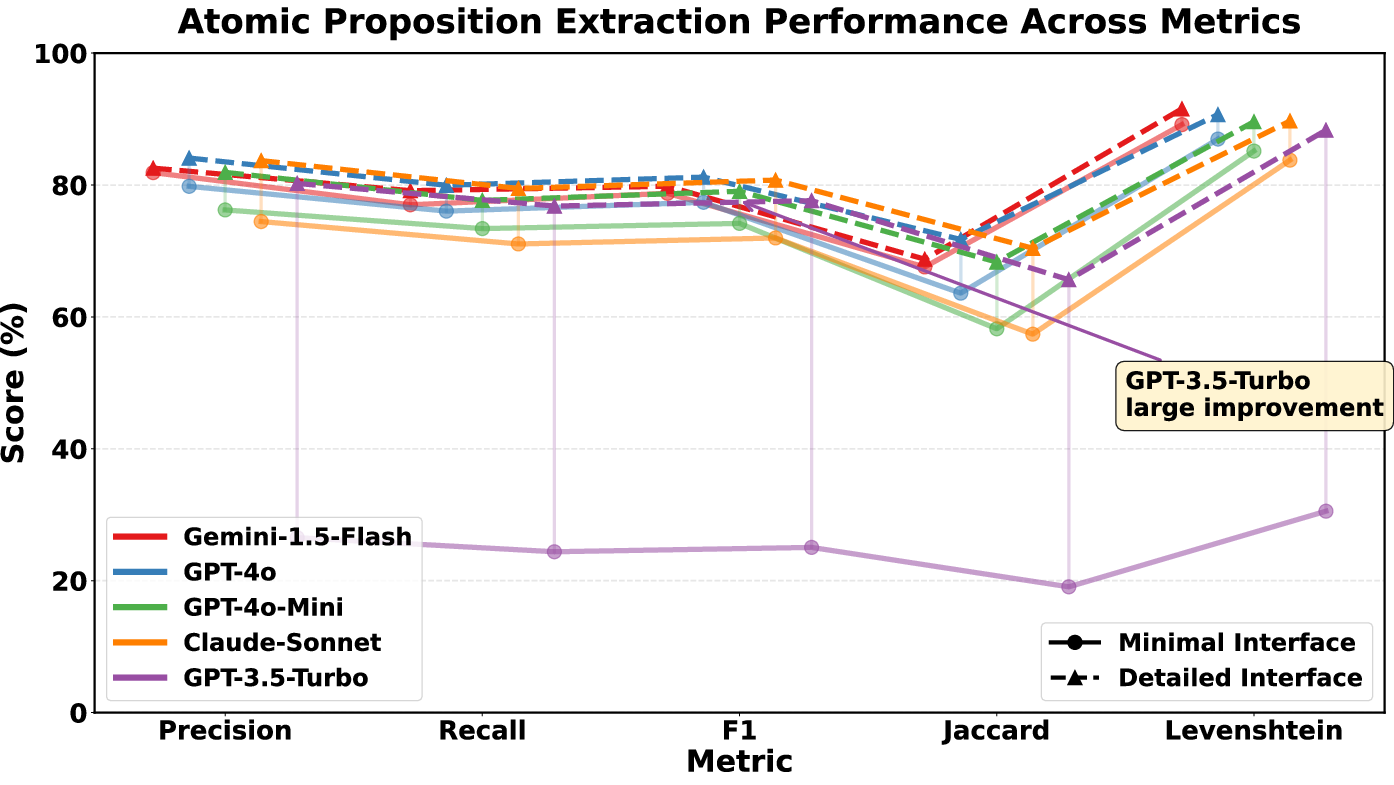
Figure 1: Performance per model and interface (precision, recall, F1-score, Jaccard similarity, Levenshtein similarity) for Atomic Proposition Extraction.
Well-formedness classification remains inconsistent across models. Even the best-performing models (e.g., Claude-3.5-Sonnet) misclassify more than 20% of formulas under the detailed interface. Both false positives (acceptance of malformed formulas) and false negatives (rejection of valid formulas) are prevalent. Syntactic validation must therefore be strictly encapsulated within formal grammar checkers; LLMs cannot reliably serve as standalone syntactic validators.
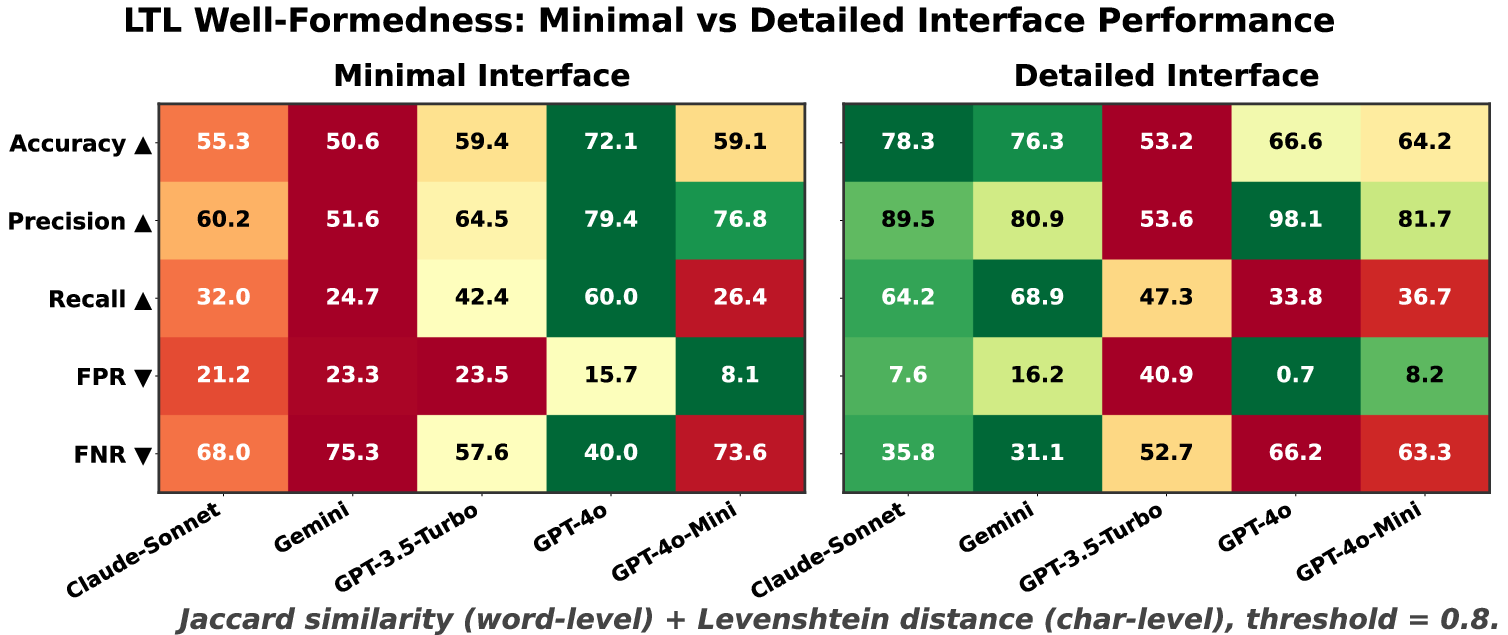
Figure 2: Detailed vs. Minimal Interface performance. Accuracy represents the fraction of correctly classified formulas. Precision and Recall measure soundness and completeness, respectively. FPR and FNR denote the rates of incorrectly accepted malformed formulas and incorrectly rejected well-formed formulas.
Semantic Evaluation
NL→LTL Generation
Semantic equivalence is achieved in fewer than one quarter of cases across traditional and detailed prompt interfaces, despite high syntactic validity. AST-constrained Python interfaces substantially improve equivalence (up to 61–72% for top models), yet mis-scoped temporal operators and incorrect nesting remain dominant failure modes. Syntactic correctness does not correlate with correct temporal interpretation; semantic verification via bidirectional entailment is essential.
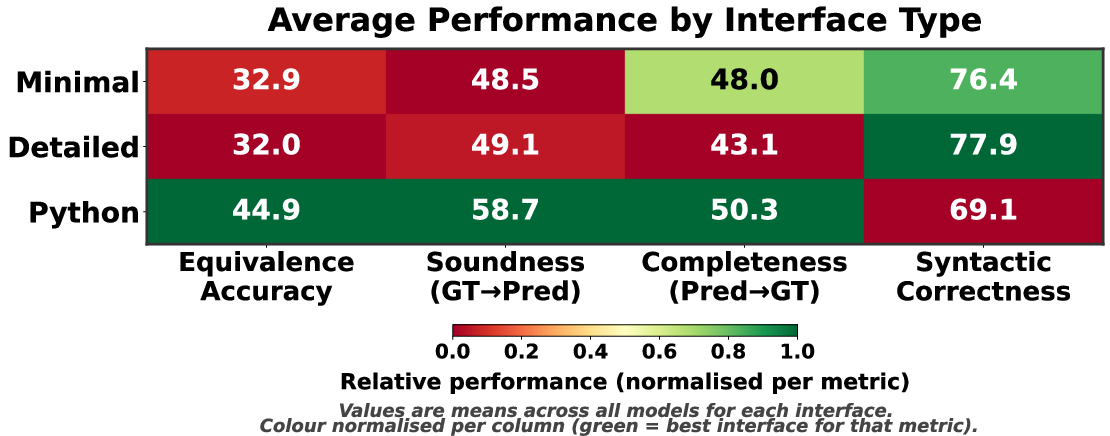
Figure 3: Semantic performance of NL→LTL translation evaluated via bidirectional entailment. Equiv. denotes semantic equivalence ($\varphi_{\mathit{GT} \Leftrightarrow \varphi_{\mathit{Pred}}$).
Trace Classification and Generation
LLMs demonstrate moderate trace classification accuracy (~80% F1 with Python interfaces), with higher reliability recognizing violating traces due to localized inconsistencies versus satisfying traces requiring global temporal constraints. Trace generation is moderately reliable (F1 55–70%), with reliability diminishing as temporal nesting depth increases. Structured interfaces guide generation but cannot eliminate errors arising from complex temporal dependencies.
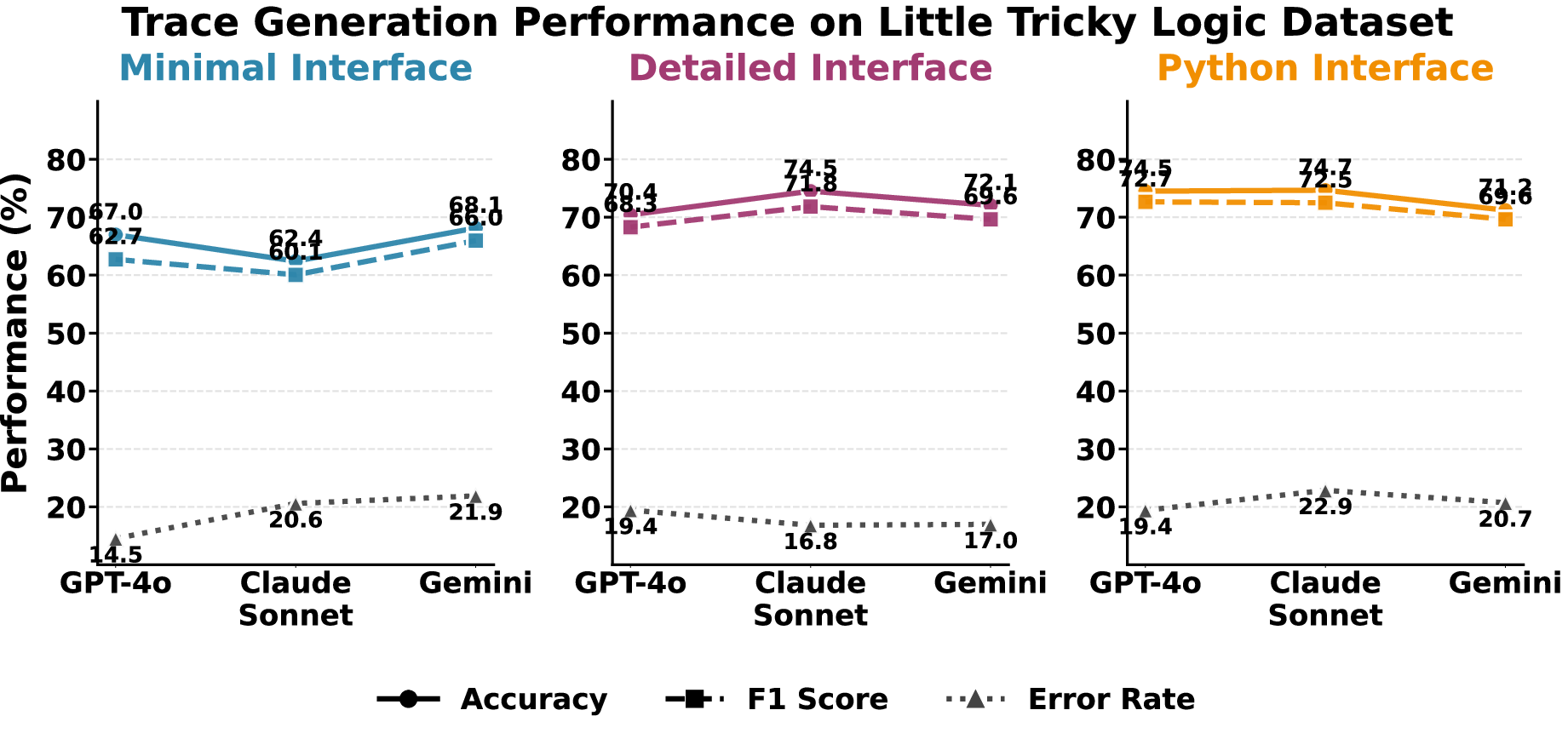
Figure 4: Trace generation results on Little Tricky Logic dataset, showing interface-dependent performance variations.
Past-LTL Generation
Transitioning to past temporal operators, LLMs achieve moderate semantic equivalence—up to ~72% for strongest models under Python interfaces. Structural constraints improve consistency but scoping errors (e.g., interactions between Y, S) and operator confusion persist.
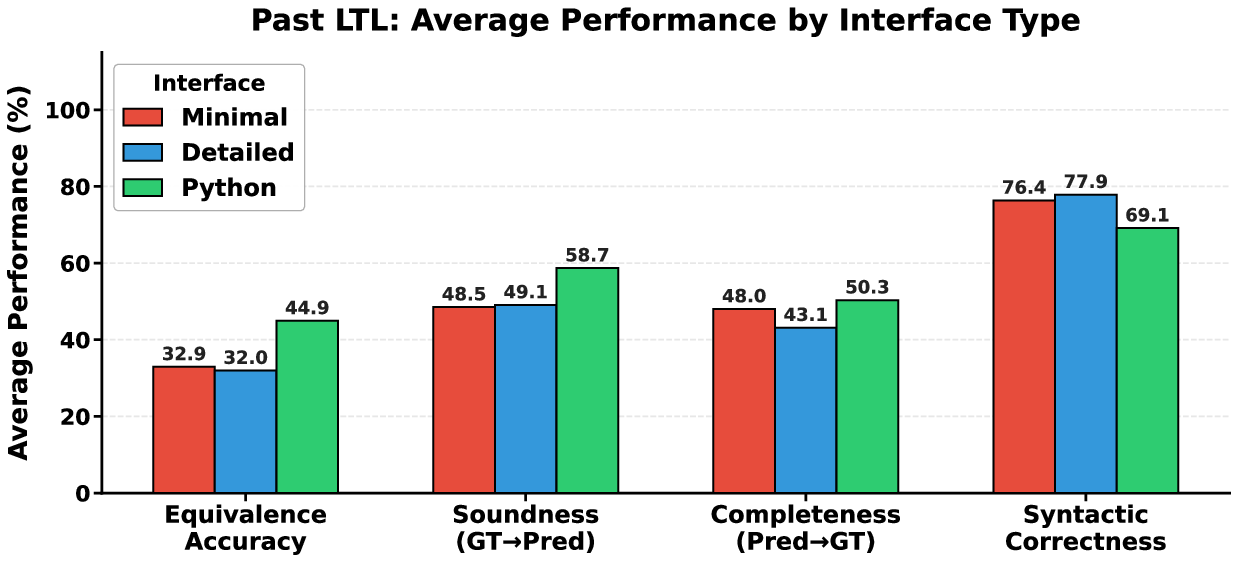
Figure 5: Semantic performance of NL→LTL (Past) translation evaluated via bidirectional entailment. Equiv. denotes semantic equivalence ($\varphi_{\mathit{GT} \Leftrightarrow \varphi_{\mathit{Pred}}$).
Security Specification Generalization
Extending evaluation to security-focused requirements (VERIFY dataset), semantic equivalence drops by 3–16 points compared to general benchmarks. Ensuring correct AP grounding is substantially more impactful, with proposition misalignment leading to a higher rate of Not Meaningful outputs. Temporal operator mis-scoping remains the dominant source of semantic error, even with correct AP mapping, highlighting the fundamental challenge in NL→LTL translation for domain-specific constraints.
Discussion, Practical Implications, and Recommendations
- Prompting design and interface enforcement are critical: Few-shot and detailed prompting outperform minimal variants; Python code-completion framing yields the highest semantic reliability, suggesting structured output constraints are necessary for specification generation.
- Semantic correctness must supersede syntactic elegance: Robust evaluation and subsequent deployment require formal semantic validation, not just string-level or grammar-based checks.
- Security-critical application demands human oversight: Semantic deviations, even minor, compromise policy enforcement and monitoring guarantees. LLM-assisted NL→0LTL translation is best considered as a decision-support tool rather than fully automated process.
- Dataset regularity and abstraction mismatch affect generalization: Edge-case datasets expose salient structural limitations, while practical requirements further amplify ambiguity and interdependence.
Theoretically, the findings foreground the gap between LLMs as syntactic parsers and as semantic reasoners in temporal logic—a consequence rooted in compositionality and abstraction hurdles, in line with established distinctions in formal methods [Pnueli_1977]. Practically, LLM outputs remain contingent on stringent post-processing and verification. The reformulation of NL→1LTL as a Python code task exploits LLMs' code-centric pretraining but is insufficient to address the broader semantic gap.
Future Directions
Advancement in NL→2LTL translation demands:
- Fine-tuning on private, non-contaminated data that accepts explicit proposition mappings.
- Retention of symbolic reasoning (model checking, synthesis, etc.) within specialized tools rather than LLMs.
- Interface-centric prompt engineering harnessing formal grammars, ASTs, and example-driven self-refinement.
- Expanded benchmarks for domain-specific requirements to stress-test temporal compositional reasoning.
Conclusion
LLMs currently exhibit strong syntactic competence in NL→3LTL translation, but struggle to reliably preserve semantic correctness, especially for temporal operator scoping and compositionality. Security and privacy domains further accentuate this gap due to implicit policy dependencies and strict correctness demands. Python code-completion interfaces serve as effective structural scaffolds, but do not resolve fundamental semantic deficiencies. Any deployment that relies on LLM-generated LTL specifications must incorporate formal semantic validation and human oversight, particularly in security-critical contexts. The study establishes clear lower bounds for end-to-end NL-to-formal specification tasks and outlines key recommendations for future evaluation and tool design.