- The paper introduces a two-stage protection mechanism, combining calibrated Laplace noise on client gradients with additive secret sharing to secure federated learning.
- It leverages a multi-server architecture to ensure rigorous (ε, δ)-DP guarantees and scalable aggregation without isolating individual client updates.
- Empirical results demonstrate that DDP-SA outperforms standalone LDP by delivering superior test loss and R² values while maintaining efficient communication and computation.
DDP-SA: Scalable Privacy-Preserving Federated Learning with Distributed Differential Privacy and Secure Aggregation
Motivation and Framework Design
The DDP-SA framework addresses persistent privacy vulnerabilities in federated learning (FL), notably privacy leakage from client updates due to inference attacks. While standard FL keeps local data on-device, adversaries have demonstrated significant leakage by attacking shared gradients or parameters. Conventional defense mechanisms fall short: local differential privacy (LDP) degrades model accuracy by adding noise, whereas secure multi-party computation (MPC) incurs computational and communication burdens and typically reveals aggregate gradients to the server. DDP-SA proposes to integrate client-side LDP and full-threshold additive secret sharing (ASS) in a multi-server architecture, ensuring robust end-to-end privacy with practical overhead.
DDP-SA introduces a two-stage protection mechanism: (1) clients perturb gradients with calibrated Laplace noise to guarantee (ϵ,δ)-DP, then (2) encode these noisy gradients into additive secret shares and distribute them across m intermediate servers. No single entity or communication channel can reconstruct any client’s specific update unless all intermediate servers are compromised.
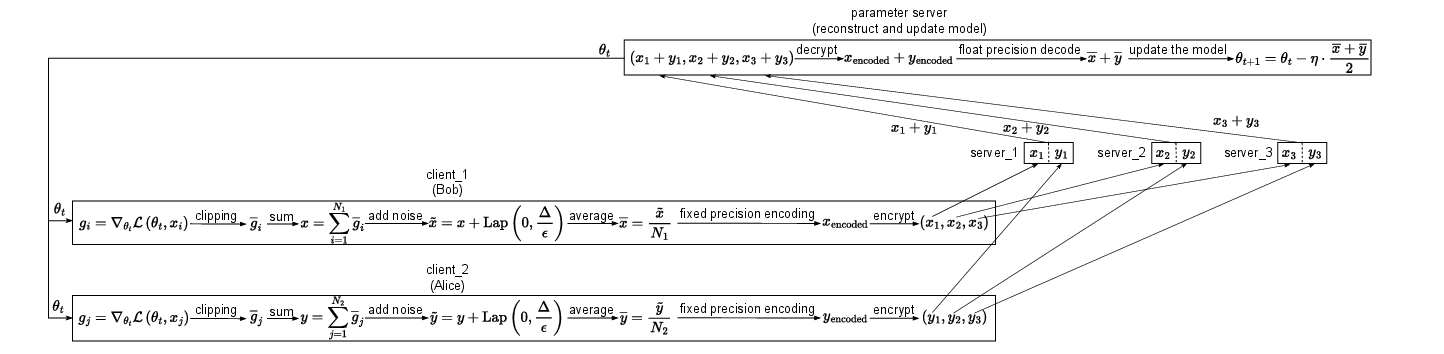
Figure 1: DDP-SA framework architecture, combining client-side local DP and secret sharing across multiple intermediate servers, highlighting two-stage privacy protection.
System Architecture and Workflow
The framework generalizes privacy-preserving aggregation via multi-server architecture supporting arbitrary m and n:
- Clients: Locally compute gradients, clip ℓ1 norm, add Laplace noise (LDP), encode to fixed-point, generate m secret shares, and upload to intermediate servers.
- Intermediate servers: Each receives one share per client, aggregates them, and forwards the partial sum to the parameter server.
- Parameter server: Reconstructs the global sum of noisy aggregates to update the global model, never isolating individual updates.
This architecture achieves linear scalability in n and m and offers flexible communication complexity by varying m. The intermediate servers enable bandwidth offloading, straggler mitigation, and isolation of fault domains.

Figure 2: DDP-SA workflow with n clients, m0 intermediate servers, and m1-dimensional parameters, illustrating scalable and secure aggregation of locally DP-perturbed gradients.
DDP-SA preserves formal m2-DP guarantees, leveraging the post-processing invariance of differential privacy. ASS provides cryptographic security: any strict subset of shares is independent of the secret. The parameter server reconstructs only aggregated, noisy gradients. End-to-end, the system’s privacy is governed by client-side LDP; secure aggregation introduces zero additional privacy loss.
Multi-round privacy accumulation is handled using basic and advanced DP composition theorems. Over m3 rounds, basic composition yields m4-DP; advanced composition achieves tighter bounds, e.g., m5, providing practical guidance for privacy budgeting over the training horizon.
DDP-SA’s hybrid statistical and cryptographic guarantees exceed those of standalone LDP or MPC. Unlike pure LDP, gradients are never transmitted in cleartext, and unlike pure MPC, client contributions receive formal statistical privacy protection.
Empirical Results: Efficiency, Accuracy, and Scalability
Extensive experiments demonstrate that DDP-SA delivers:
- Communication rounds to convergence: MPC and No-Private require ~2070 rounds, LDP and DDP-SA require ~2440 rounds with identical optimizer and noise settings, confirming that aggregation strategy does not dominate convergence rate.
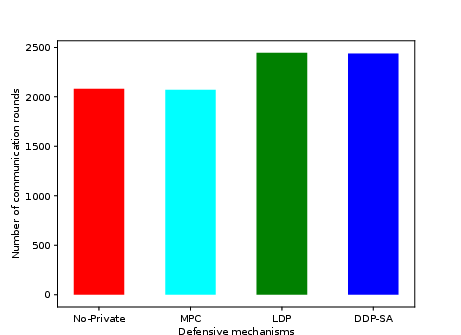
Figure 3: Communication rounds to convergence under various defense mechanisms.
- Parameters uploaded per client: In DDP-SA and MPC, each client uploads m6 parameters (m7 in experiments), scaling linearly with m8. In contrast, LDP and No-Private require only m9 parameters, validating scalability of the intermediate server architecture.
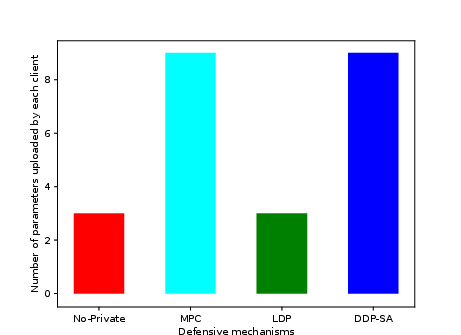
Figure 4: Parameter upload per client for different mechanisms (m0).
- Total time to convergence: DDP-SA incurs modest overhead compared to LDP (203 vs 172 minutes), well within practical bounds.
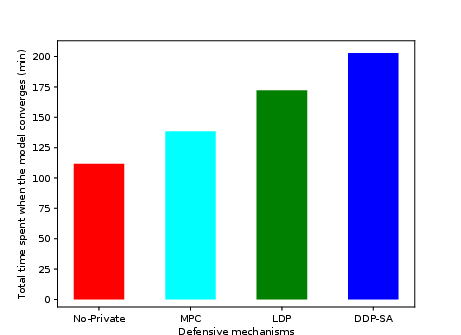
Figure 5: Time to convergence for varying privacy mechanisms.
- Average time per training round: DDP-SA rounds require only 10s, versus 8.4s for LDP, remaining efficient even as m1 increases.
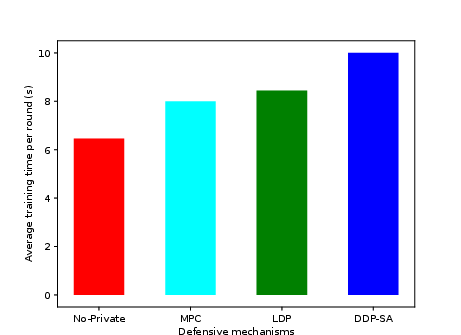
Figure 6: Average round training time.
Component-wise analysis identifies gradient clipping as the primary bottleneck. Communication overhead scales as m2, but per-client bandwidth can be minimized by increasing m3; system ingress bandwidth to the parameter server becomes m4, enabling scalability to large m5.
Model Utility and Privacy-Utility Tradeoff
Model accuracy was evaluated via test loss and test m6. DDP-SA consistently outperformed standalone LDP: with m7, DDP-SA achieves test loss of m8 and m9, while LDP yields n0 loss and n1. No-Private and MPC provide near-perfect values (n2 loss, n3 n4).
Increasing the privacy budget n5 improves both LDP and DDP-SA utility; DDP-SA maintains a superior trajectory, enabling lower privacy budgets for a given target accuracy. As the client count n6 increases, noise averaging further boosts accuracy, with DDP-SA scaling robustly.
Privacy Protection Strength and Attack Mitigation
DDP-SA resists inference attacks through dual protection:
- Membership/property/training data attacks: Locally perturbed gradients coupled with secret sharing mitigate reconstruction risks.
- Strict-subset indistinguishability: Any subset of fewer than n7 shares yields zero mutual information about client data; compromise probability decays exponentially with n8.
- Resilience to server compromise: Parameter server cannot reconstruct any client’s gradient given only aggregated values.
These properties apply across multiple rounds due to DP composition and the immutable cryptographic protection from ASS. DDP-SA outperforms pure LDP or MPC in terms of end-to-end privacy, especially when adversaries have physical link access or compromise subsets of servers.
Implications and Future Directions
DDP-SA demonstrates that hybrid privacy architectures are feasible for scalable FL systems, delivering stronger privacy protections without catastrophic accuracy loss or prohibitive overhead. In practice, DDP-SA provides a tunable privacy-utility tradeoff and robustness to communication and computation scalability. The architecture supports integration with dropout-tolerant aggregation and is extensible to heterogeneous or non-IID client datasets.
Future work may focus on:
- Adaptive privacy budget allocation across rounds and clients, leveraging advanced DP mechanisms.
- Generalization to more sophisticated model architectures or non-IID partitions.
- Optimization of secure aggregation to further minimize communication and computation bottlenecks.
- Integration with privacy amplification techniques (e.g., shuffling) and robustness to active adversaries.
Conclusion
DDP-SA establishes a principled, scalable foundation for privacy-preserving federated learning by combining local DP and secure aggregation. Empirical and theoretical analysis confirms that DDP-SA achieves superior privacy protection compared to standalone LDP or MPC, with only moderate and controllable tradeoffs in accuracy and efficiency. The results demonstrate that hybrid designs are key for practical FL deployments confronting stringent privacy requirements and scalability demands (2604.07125).

