- The paper introduces NestPipe, a hierarchical nested pipelining framework that mitigates lookup and communication bottlenecks using dual-buffer and frozen-window techniques while ensuring convergence.
- It decomposes embedding lookups into inter-batch (DBP) and intra-batch (FWP) stages, achieving up to 3.06× speedup and >90% resource utilization on massive clusters.
- Empirical results on 1,536 NPUs and 128 GPUs demonstrate minimal accuracy loss and robust scalability, setting a new baseline for trillion-parameter recommendation models.
NestPipe: Scalable Hierarchical Pipelining for Large-Scale Recommendation Model Training
Motivation and Problem Statement
As recommendation systems advance toward trillion-parameter scales, training efficiency is increasingly bottlenecked by embedding table lookups and All2All communication, particularly in decentralized, heterogeneous clusters exceeding 1,000 accelerators. While computation and memory constraints have been partially mitigated by hierarchical hybrid storage and model/data sharding, exposed data movement overheads grow super-linearly with cluster size. Existing solutions—such as asynchronous sparse pipelines, embedding compression, and communication-compressing parallelisms—either relax training consistency (sacrificing convergence/accuracy) or fail to scale due to exacerbated staleness or residual resource idleness.
NestPipe Framework Design
NestPipe introduces a hierarchical nested pipelining paradigm that optimizes two distinct forms of sparse parallelism: inter-batch and intra-batch, thereby simultaneously addressing lookup and communication bottlenecks without compromising synchronous semantics.
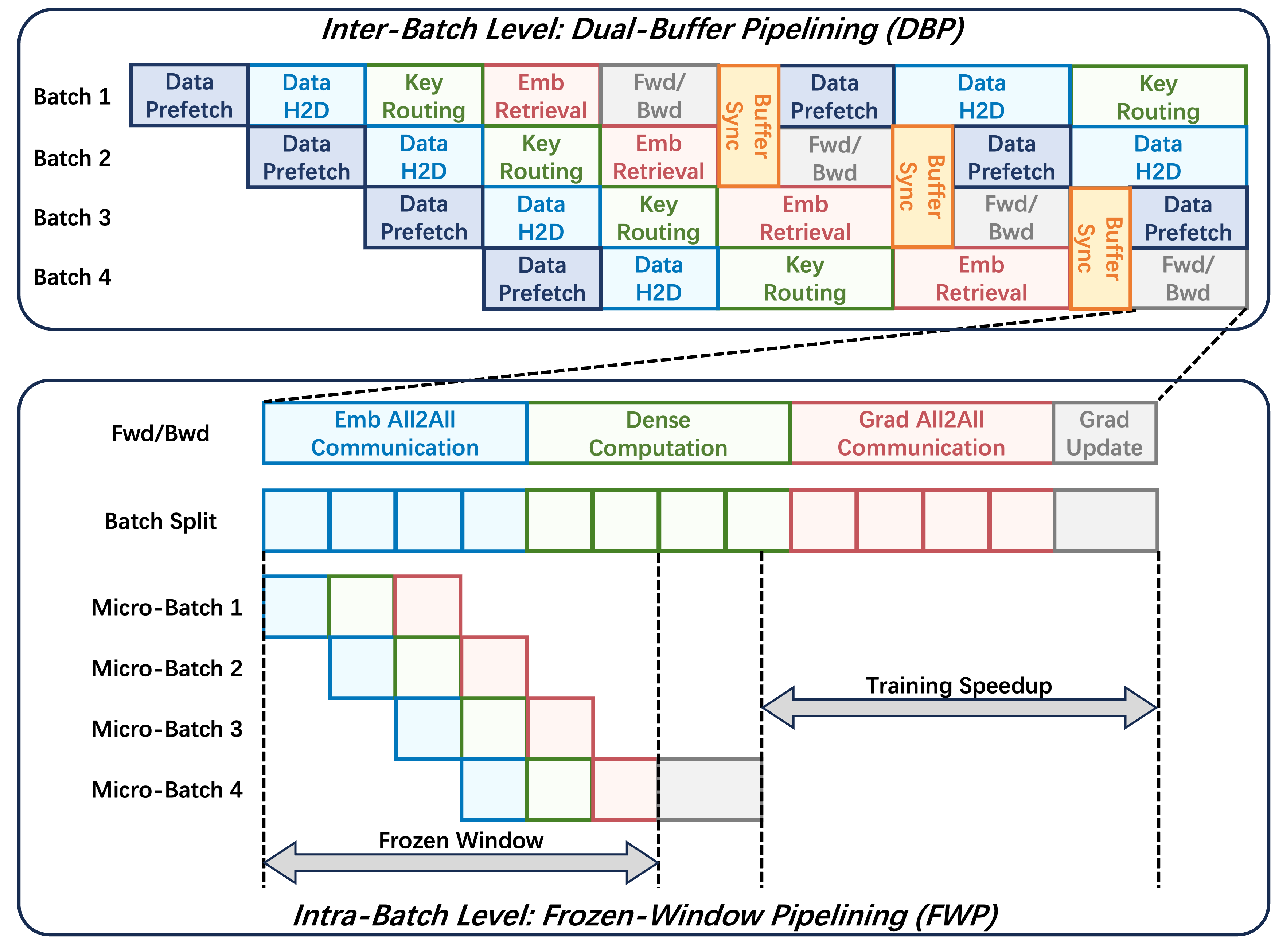
Figure 2: Overview of the NestPipe system, illustrating hierarchical pipelining at inter-batch and intra-batch granularity.
Inter-Batch Level: Dual-Buffer Pipelining (DBP)
The Dual-Buffer Pipelining (DBP) strategy decomposes the embedding lookup pipeline into five distinct stages—data prefetch, data H2D, key routing, embedding retrieval, and Fwd/Bwd computation—each mapped to disjoint resource domains (CPU, network, HBM, accelerators). Crucially, a dual HBM buffer system is maintained per worker: an 'active' buffer serves the current batch, while a 'prefetch' buffer asynchronously loads embeddings for the subsequent batch. Prior to each batch's forward computation, the intersection between active/prefetch buffers is efficiently synchronized via device-to-device copies, ensuring all overlapping embeddings are up-to-date, thereby fully eliminating staleness without impeding pipeline progress.
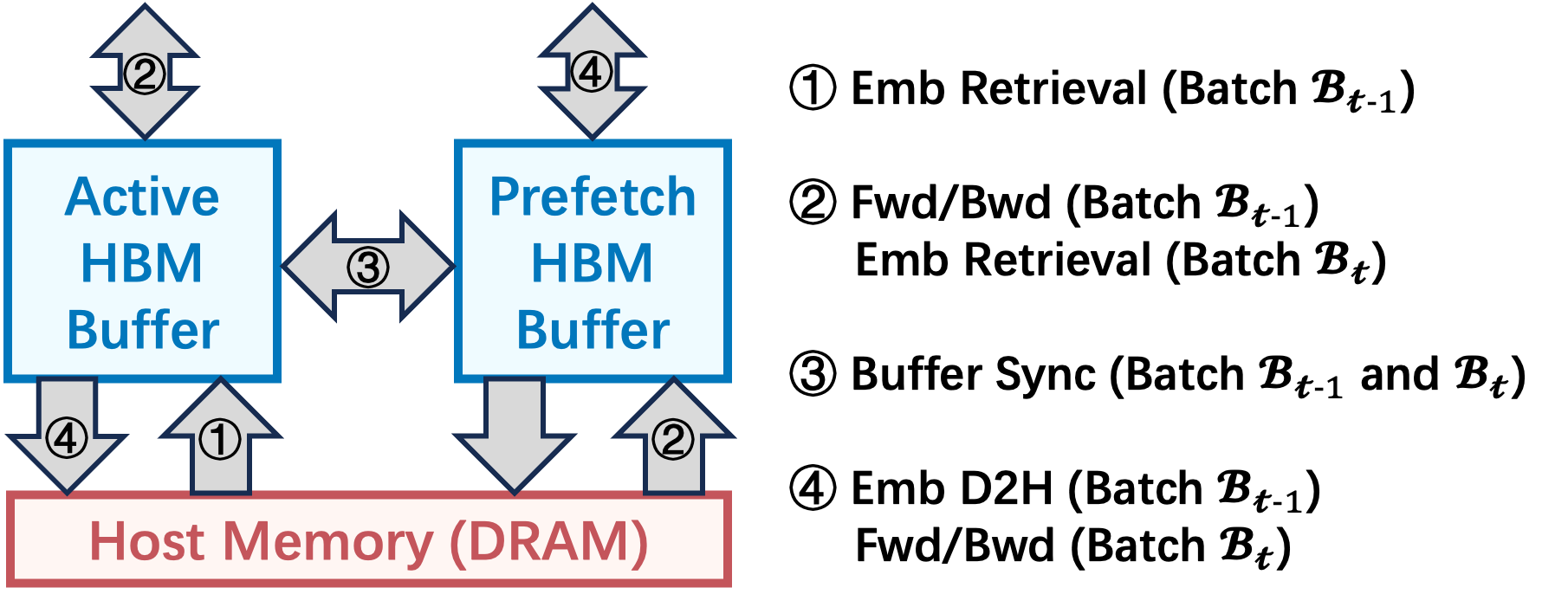
Figure 1: Dual-buffer synchronization in DBP, maintaining parameter freshness across pipeline stages.
This design critically diverges from naive pipelining, which, by not tracking embedding update and access dependencies, would introduce semantic staleness, thereby impairing convergence.
Intra-Batch Level: Frozen-Window Pipelining (FWP)
At finer granularity, the Frozen-Window Pipelining (FWP) strategy leverages the observation that, within a single batch, the forward/backward micro-batch computations do not mutate the embedding parameters—they are only updated once batch gradients are aggregated. Hence, FWP aggressively overlaps All2All embedding communications for micro-batches with dense-layer computation of adjacent micro-batches, within a mathematically justified "frozen window" where all parameter references are consistent. Two coordinated execution streams (communication, computation) are orchestrated to launch All2All exchanges early, schedule ready micro-batches for dense forward/backward steps, and synchronize only at semantic boundaries.

Figure 3: Implementation details of FWP: concurrency of communication and computation streams exploiting the frozen window.
FWP further enhances deduplication efficiency via lightweight key-centric sample clustering. By assigning samples sharing keys to common micro-batches, it maximizes intra-micro-batch redundancy, minimizes redundant transfers, and closely achieves the theoretical communication overlap ratio $1/N$ (where N is the number of micro-batches).
Theoretical Consistency Analysis
Formal proofs accompany both DBP and FWP strategies, demonstrating that—by synchronizing buffer intersections pre-forward and deferring all parameter updates to full batch boundaries—NestPipe preserves strict equivalence to the synchronous update Wt+1=Wt−ηξ∈Bt∑∇F(Wt,ξ). This maintains parameter consistency even under deeply overlapped pipelines, in contrast to prior asynchronous schemes or topology-altered aggregation paradigms.
Experimental Evaluation
NestPipe's efficacy and scalability were validated on industrial-scale training clusters (1,536 NPUs, 128 GPUs) using production-grade datasets and models. The empirical evaluation demonstrates several salient outcomes:
- Up to 3.06× Training Speedup: Compared to SOTA baselines (e.g., TorchRec, 2D-SP), NestPipe achieves up to 3.06× speedup and 94.07% scaling efficiency at the 1,536-worker scale, without discernible convergence or accuracy loss.
- Staleness-Free Semantics: Unlike asynchronous pipelines and certain communication-restricted schemes, NestPipe exhibits negligible degradation in HR@10 and NDCG@10, with differences consistently below 0.3×10−3, confirming full training consistency.
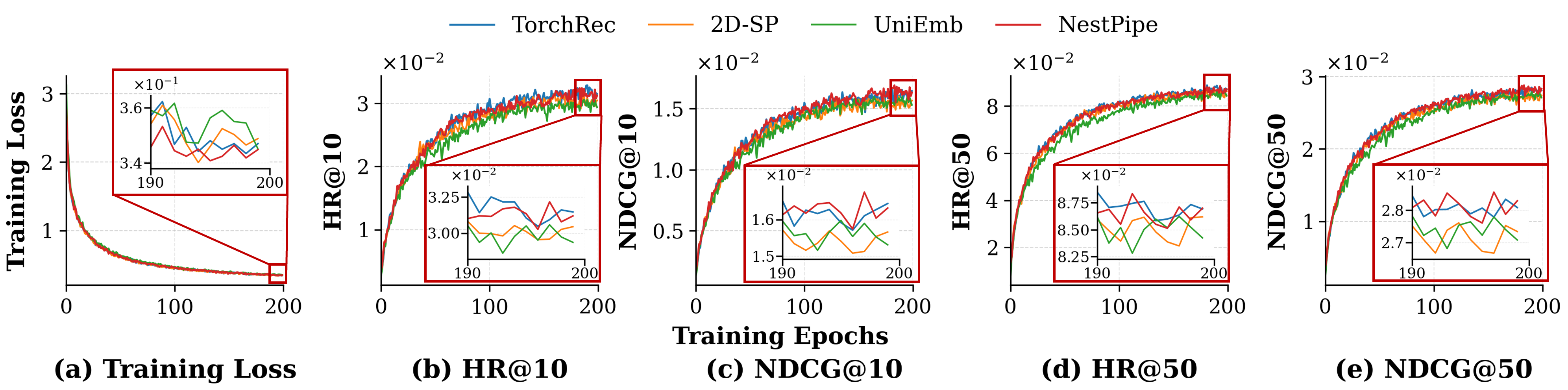
Figure 4: Training loss and accuracy curves for different methods, highlighting NestPipe's preservation of synchronous convergence.
- Superior Hardware Utilization: Coordinated compute/comm streams maintain >90% resource utilization throughout scaling regimes, minimizing idle periods attributable to communication or preprocessing.
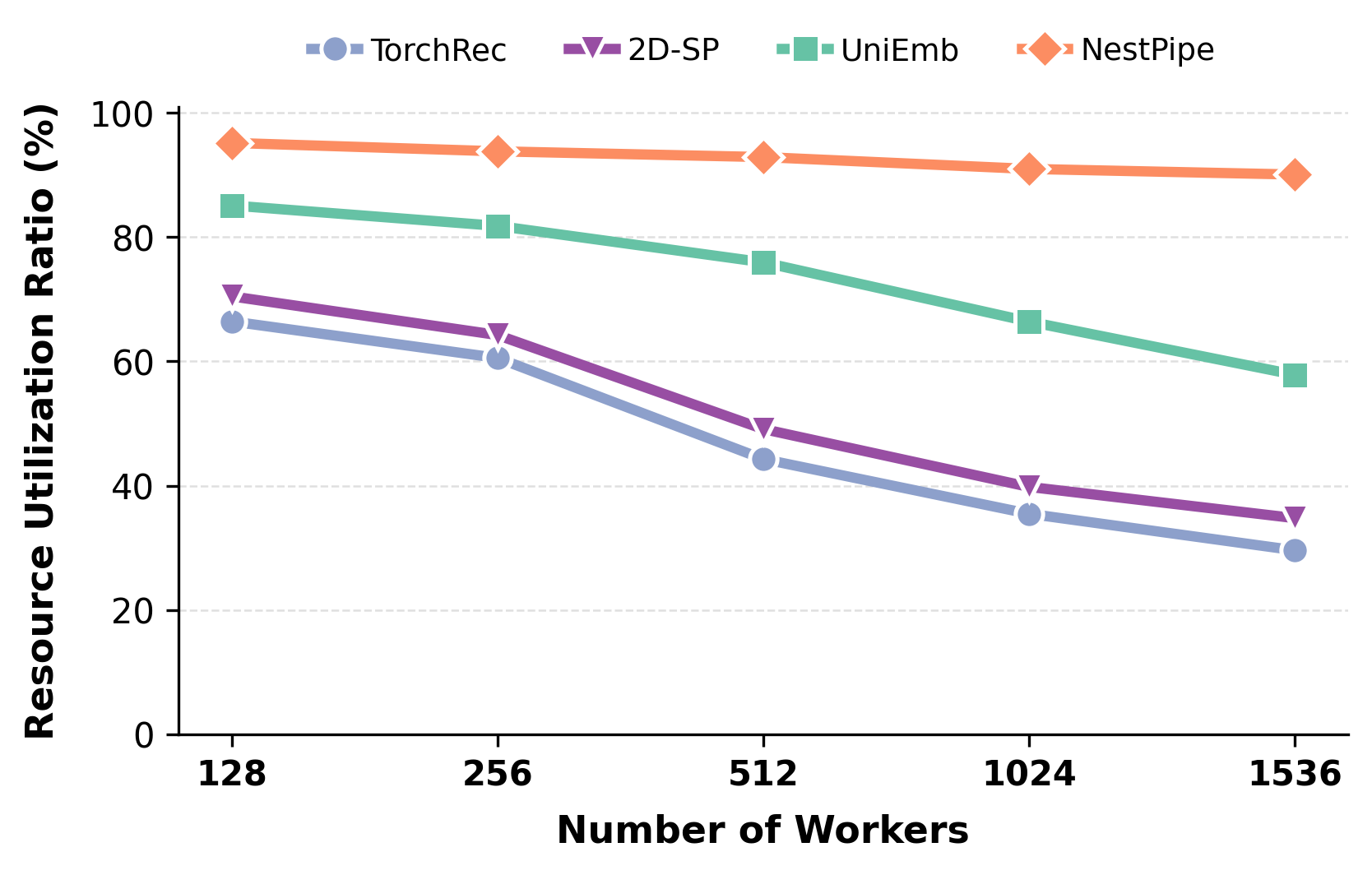
Figure 5: Resource utilization ratio improvements with NestPipe, sustaining efficient accelerator usage at large cluster sizes.
- Communication and Lookup Bottleneck Elimination: Latency breakdowns across cluster scales, embedding dimensions, and sequence lengths demonstrate that both lookup and communication times are aggressively overlapped and largely hidden under computation.
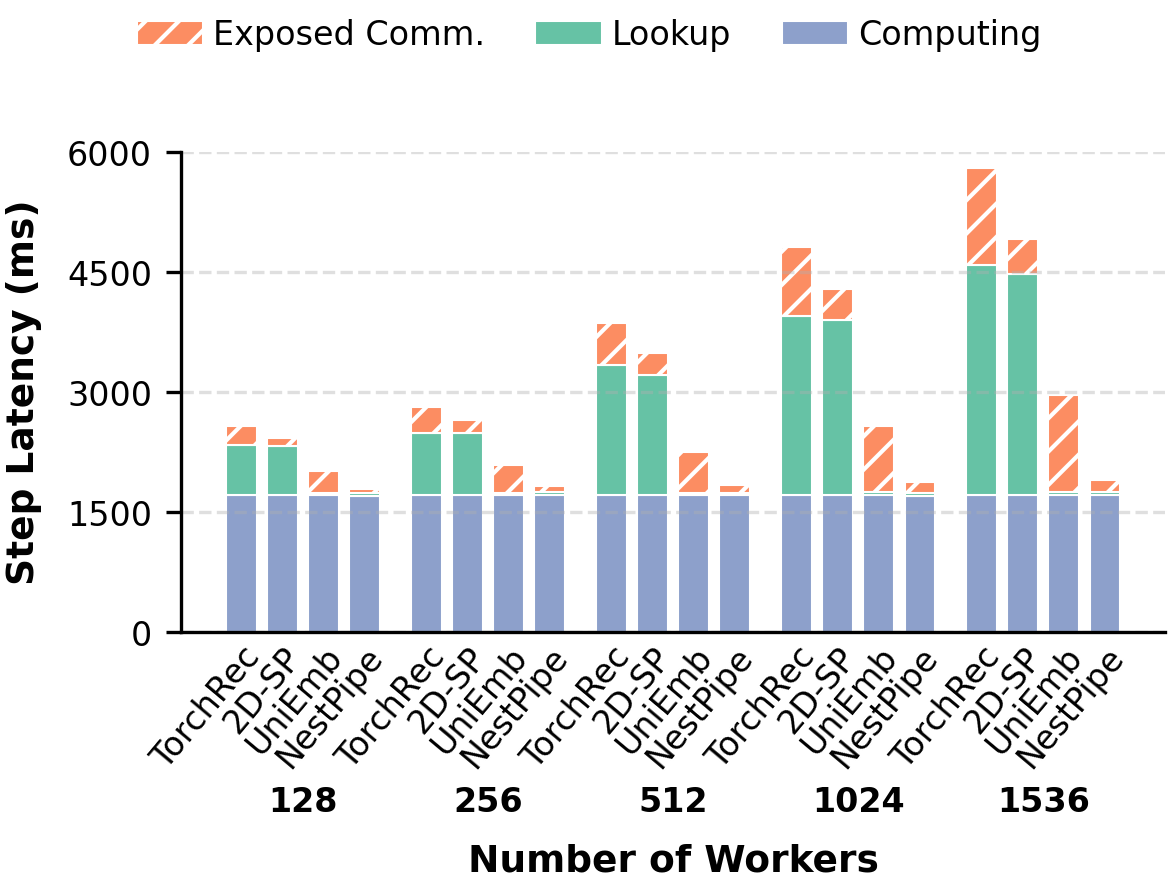
Figure 7: NestPipe step latency breakdown remains stable across increasing cluster sizes, indicating robust scalability.
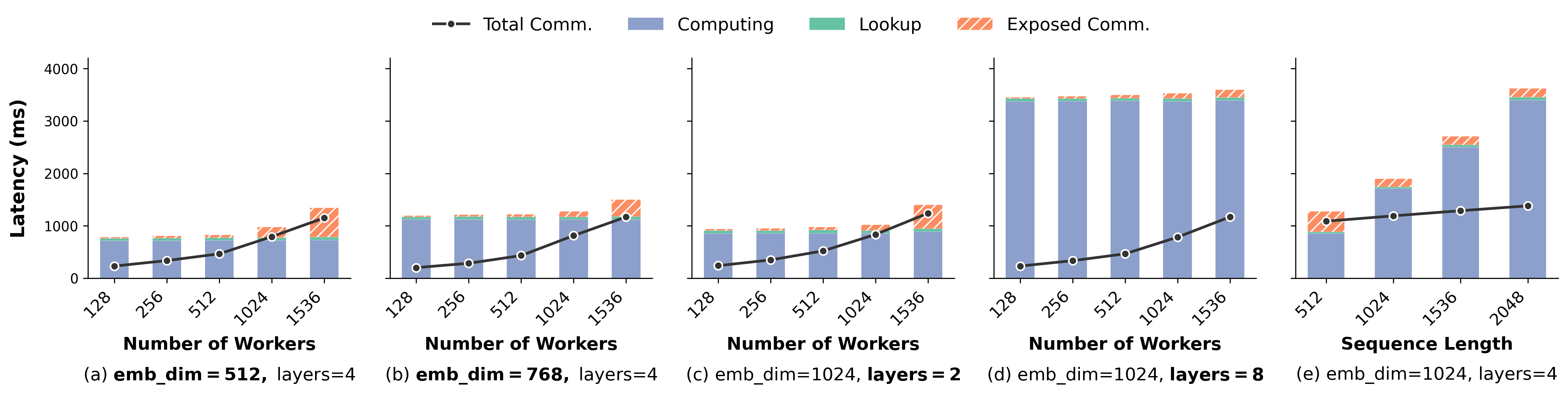
Figure 6: Step latency breakdowns for varied embedding dimensions, dense layers, and sequence lengths, demonstrating the adaptability of NestPipe.
Orthogonality and Integration with Existing Methods
NestPipe is orthogonal to communication- and payload-reduction techniques. Experiments integrating NestPipe with 2D sparse parallelism show further reductions in exposed All2All latency and push scaling efficiency to 97.17%, confirming that temporal overlap and spatial communication reduction are complementary.
Implications and Future Directions
NestPipe presents a robust hierarchical parallelization framework for next-generation industrial recommendation models, demonstrating that exposed data movement, rather than absolute communication, defines scalability limits. By focusing optimization on the exposed pipeline ratios, NestPipe escapes the accuracy-throughput deadlock characterizing earlier strategies. This design generalizes across hardware platforms and is compatible with further embedding compression, sharding, and network topology advancements.
The underlying principles—resource decoupling for lookup, staleness-free pipeline synchronization, and frozen-window intra-batch scheduling—suggest compelling directions for similarly structured sparse+dense large-scale models (e.g., memory-augmented LLMs, mixture-of-experts architectures).
Conclusion
NestPipe delivers consistent, efficient, and near-linearly scaling decentralized embedding training at massive cluster scales. Hierarchical nested pipelining—via DBP and FWP—addresses both exposed lookup and communication overheads without relaxing synchronous training semantics. The integration of NestPipe within existing distributed training frameworks is likely to set a new operational baseline for trillion-parameter recommendation models and beyond.