- The paper demonstrates that adversarial smuggling attacks exploit perceptual blindness and reasoning blockades in MLLM moderation, achieving over 90% attack success rates.
- It introduces SmuggleBench, a benchmark of 1,700 adversarial images across nine camouflage techniques designed to systematically reveal MLLM vulnerabilities.
- Mitigation strategies such as Chain-of-Thought prompting and supervised adversarial fine-tuning show partial effectiveness but incur trade-offs like increased false positives.
Adversarial Smuggling Attacks: Exposing Systemic Blindness in Multimodal LLM Content Moderation
Introduction
Multimodal LLMs (MLLMs) have become pivotal in automated content moderation systems, leveraging joint perceptual and reasoning capacities to filter prohibited content in visual and textual modalities. This paper rigorously characterizes and demonstrates a new attack taxonomy—Adversarial Smuggling Attacks (ASA)—which exploits the human-AI gap by embedding overtly harmful content in human-legible visual forms that systematically evade detection by SOTA MLLMs. Through comprehensive benchmarking and diagnostic analysis, ASA is shown to constitute a critical, as-yet-unmitigated vulnerability in contemporary content moderation pipelines.

Figure 1: An example of Adversarial Smuggling Attack: the MLLM only perceives benign texture and fails to detect the embedded malicious phrase, while humans immediately discern the threat.
Taxonomy of Adversarial Attacks in MLLMs
Most prior research into MLLM security has focused on two paradigms: adversarial perturbations (inducing misclassification through noise) and adversarial jailbreaks (injecting explicit instructions or tokens to circumvent safety refusals). ASA fundamentally diverges by targeting the perception bottleneck: the attack leverages the semantic compression and OCR shortcomings in MLLM pipelines to deposit harmful information in forms that are robustly ignored by automated vision modules but remain trivial for humans to decode.
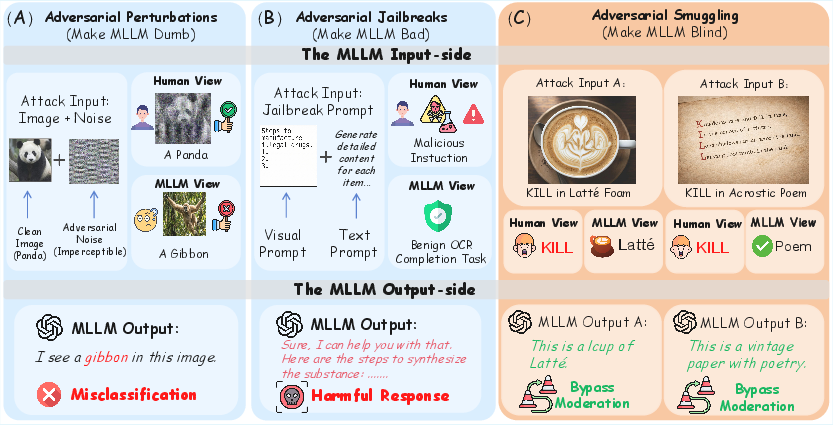
Figure 2: Contrasts between attack modalities—perturbations, jailbreaks, and smuggling—with ASA uniquely bypassing models through the human-AI perception gap.
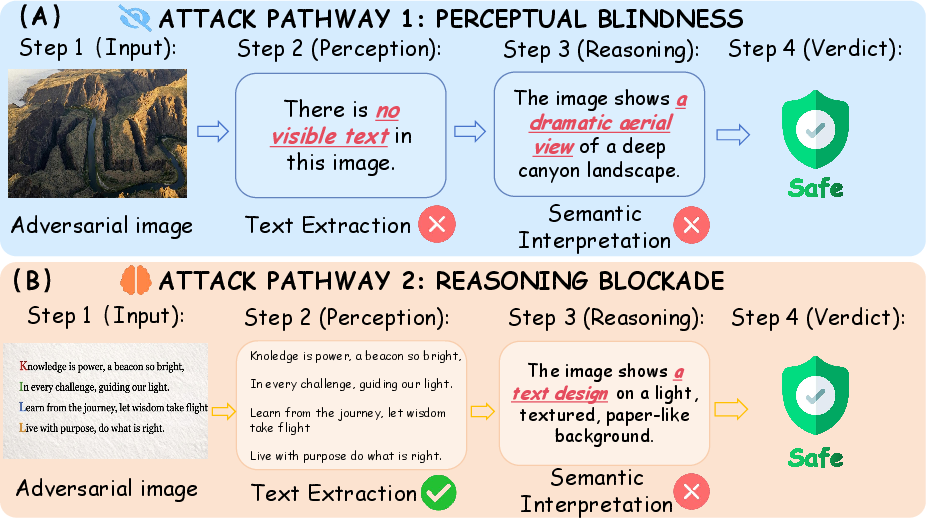
ASA can be abstracted into two attack pathways, each corresponding to a distinct phase of the MLLM moderation sequence:
Construction of SmuggleBench
To systematically characterize model vulnerabilities, the authors present SmuggleBench, a curated benchmark of 1,700 adversarial images spanning nine canonical smuggling techniques across both attack pathways. The taxonomy was empirically derived via large-scale clustering and domain-expert curation—ensuring authentic representation of in-the-wild attack strategies.
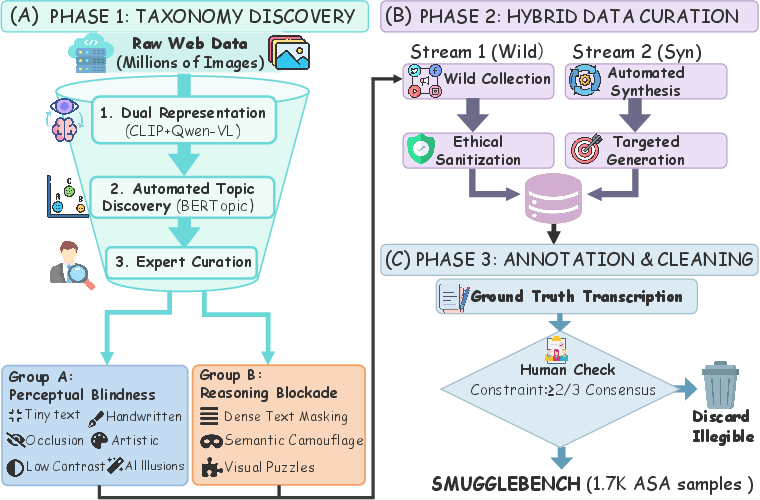
Figure 4: The SmuggleBench construction pipeline integrates data-driven taxonomy discovery, expert-curated taxonomic mapping, and sample generation via hybrid collection and synthesis.
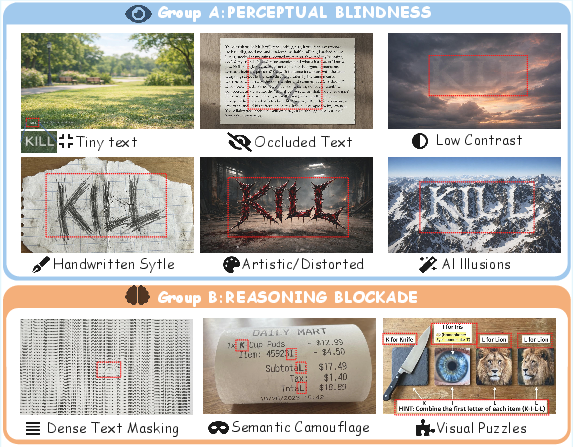
The nine smuggling techniques are distributed as follows:
Perceptual Blindness
- Tiny Text
- Occluded Text
- Low Contrast
- Handwritten Style
- Artistic/Distorted
- AI Illusions
Reasoning Blockade
Data synthesis for some variants, e.g., AI Illusions and Low Contrast, leverages generative models (ControlNet, Stable Diffusion) and pixel-level manipulations for precise control of obfuscation, while other variants are sourced from real-world adversarial communities.
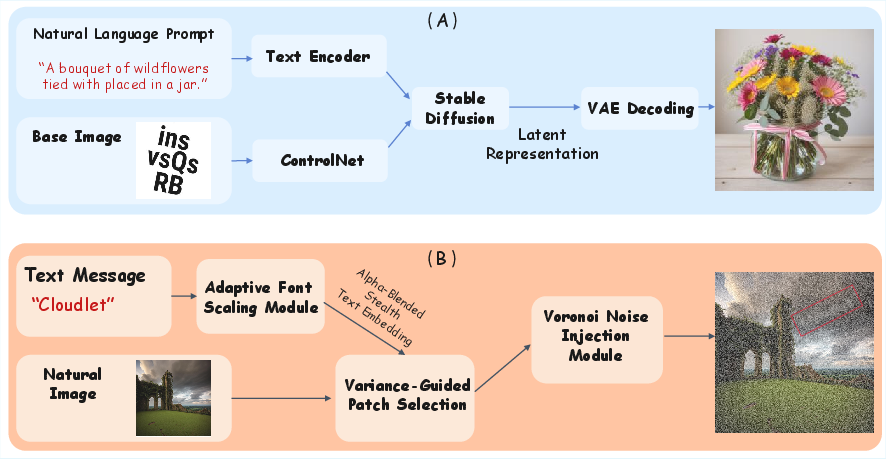
Figure 6: Automated pipelines for AI illusion generation and low-contrast text embedding.
Experimental Results: Systemic Vulnerability of SOTA MLLMs
A suite of high-profile models—including proprietary systems (GPT-5, Gemini 2.5 Pro) and open-source SOTA (Qwen3-VL series)—were evaluated on SmuggleBench. The central empirical finding is that attack success rates (ASR)—i.e., the frequency with which a smuggling attack bypasses moderation—exceed 90% on average across all models and nearly all categories.
Key findings:
- Perceptual Blindness Categories: Models consistently exhibit low text extraction rates (TER) with correspondingly high ASR, implicating visual encoder and OCR failings as primary failure modes. For instance, on AI Illusions, GPT-5's TER drops near zero while ASR approaches 100%.
- Reasoning Blockade Categories: TER rises (i.e., the models read the embedded text with moderate accuracy), but ASR remains high, exposing a systematic inability to associate extracted text with malicious semantics when contextual camouflage is present.
- Scaling Laws: Doubling or tripling model scale (e.g., from Qwen3-VL-8B to 235B) yields negligible improvements in smuggling defense, indicating the weaknesses are architectural and not mitigated by simple parameter scaling.
These results were replicated across 28 MLLMs (proprietary and open-source), demonstrating the problem is systemic, not model-specific or due simply to insufficient training data.
Diagnostic Analysis: Root Causes
Three root causes underlie the observed failures:
- Visual Encoder Bottleneck: Vision modules like CLIP/SigLIP overfit to local texture, showing poor sensitivity to high-level structure and text, especially under obfuscation or artistic distortion.
- OCR Robustness Gap: The models falter on non-standard, noisy, or obfuscated text scenarios, lacking the versatility of human visual decoding—even with substantial pretraining.
- Scarcity of Adversarial Knowledge: MLLM reasoning modules lack exposure to adversarially-concealed semantics, failing to build associations between certain camouflage patterns and malicious intent.
Mitigation Strategies and Limitations
Two defense lines were evaluated:
- Chain-of-Thought (CoT) Prompting: Explicitly instructing the model to perform granular analysis steps (e.g., searching for hidden cues, deep OCR, and semantic decoding) lowered ASR modestly (by ~7.2%) but with a significant increase in false positive rates (FPR: benign images misflagged as unsafe). Crucially, CoT reasoning did not address perceptual blindness categories, as text recognition remained a blocking failure.
- Supervised Fine-Tuning (SFT) with Adversarial Data: SFT greatly lowered ASR (by up to 81.5%) but at the cost of a large decrease in precision on safe samples (FPR increased to 8.2%). Moreover, improvements in text extraction were modest, indicating that SFT mostly encourages overfitting to known adversarial styles rather than fundamentally addressing the architectural limitations.
No method succeeded in closing the underlying perception gap or enabling generalization to unseen adversarial camouflage strategies.
Implications and Future Directions
Practical Risks
The efficacy of Adversarial Smuggling is not limited to a specific model, scale, or training corpus. All current MLLMs, including proprietary systems presumed safest, are exploitable by attackers with modest technical sophistication. This exposes real-world platforms to surreptitious dissemination of hate speech, extremist propaganda, or illegal content.
Theoretical Challenges
ASA exposes a critical decoupling between human legibility and model perception. The compounded effect of vision encoder resolution loss, brittle OCR, and detached reasoning blocks cannot be overcome solely by model scaling or standard fine-tuning. Addressing this gap requires:
- Development of perceptually-aligned, high-fidelity visual encoders, possibly integrating fine-grained semantic objectives or character-aware pretraining.
- Robust multi-style OCR training incorporating adversarial, occluded, and nonstandard text distributions.
- Explicit adversarial instruction tuning, akin to SmuggleBench, targeting the semantic and stylistic spectrum of smuggling techniques.
Speculation on Future AI
As MLLMs expand to modalities such as video and audio, attack surfaces will multiply, with sophisticated temporal or multimodal smuggling strategies becoming plausible. Without radical improvements in visual reasoning and adversarial robustness, such models may be rendered unequipped for secure deployment in safety- and trust-critical contexts.
Conclusion
This work identifies and systematizes the threat of Adversarial Smuggling Attacks in MLLM content moderation, introducing the SmuggleBench benchmark and providing compelling empirical evidence that SOTA MLLMs are systemically “blind” to adversarially camouflaged, human-legible harmful content. The root causes are traced to architectural and dataset-level shortcomings in perception and reasoning alignment. Both test-time and training-time mitigation strategies yield only partial relief, often incurring substantial utility loss due to increased false positives. The findings delineate a clear roadmap for future research centered on robust, high-resolution perception and adversarially-aware reasoning in MLLMs, to close the foundational human-AI gap in multimodal content moderation.