- The paper introduces an innovative on-device data sanitization framework using knowledge distillation to combat unintended data poisoning in federated SLM alignment.
- It leverages a two-step method combining teacher-student distillation and refusal template replacement to robustly filter toxic samples while preserving model utility.
- Empirical results demonstrate significant safety improvements with restored attack success rates and maintained performance on benchmarks like TruthfulQA and GSM8K.
FedDetox: Robust Federated SLM Alignment via On-Device Data Sanitization
Motivation and Problem Definition
The incessant demand for high-quality data for LLMs has led to the exhaustion of open data sources, driving increased reliance on Federated Learning (FL) to access decentralized, private user data. However, FL introduces complex safety challenges due to the heterogeneity and intrinsic noisiness of real-world client datasets, which may contain toxic or unsafe content arising not from malicious intent but from organic user interactions. The paper rigorously formulates the risk of unintended data poisoning—a phenomenon where benign clients unknowingly propagate unsafe samples during federated preference alignment—resulting in catastrophic degradation of global model safety.
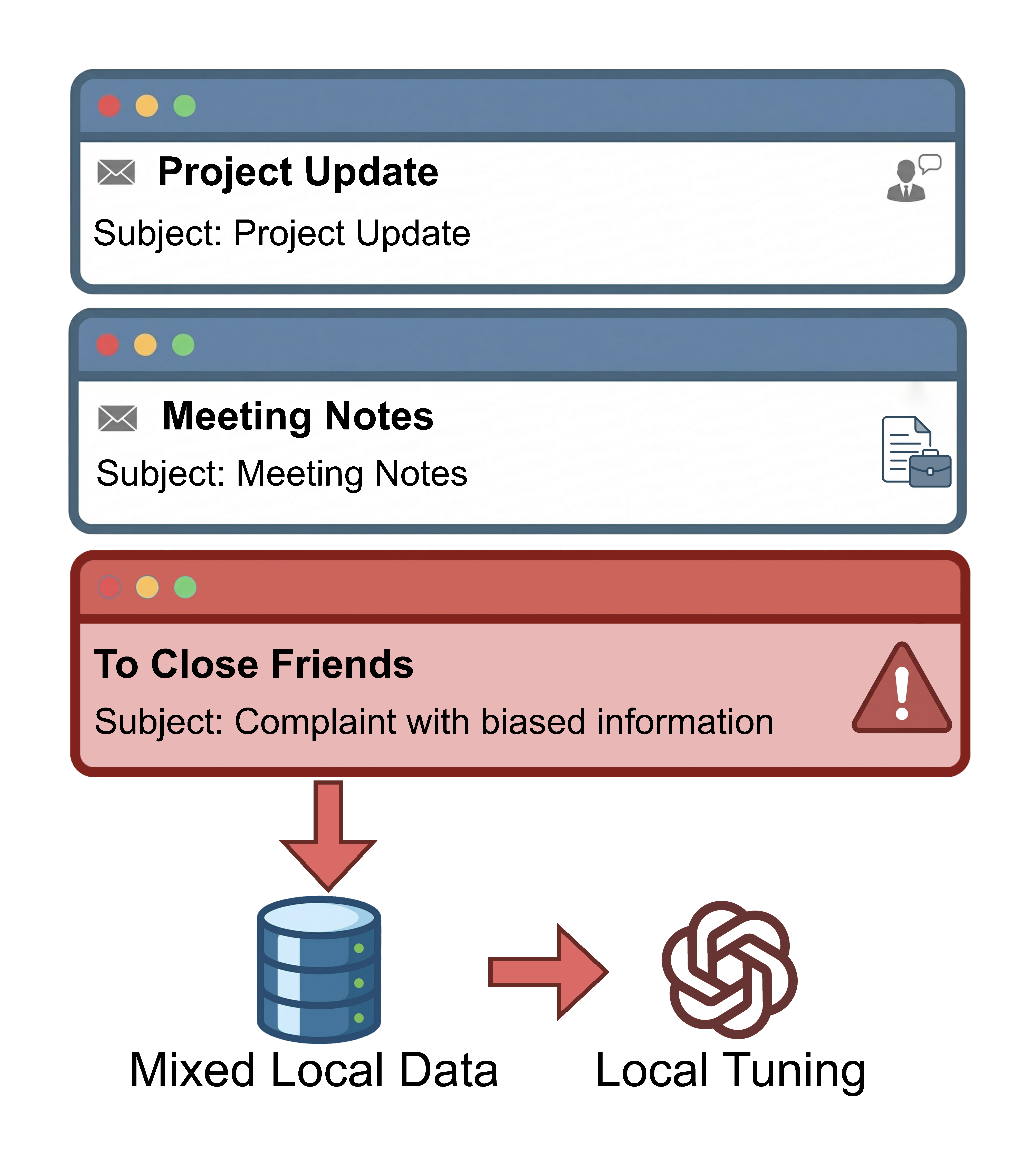
Figure 1: An illustrative example of unintended data poisoning, where daily emails containing sensitive emotions act as toxic samples during federated alignment.
The threat model distinguishes unintended poisoning from classical Byzantine and backdoor attacks. Unaware clients fine-tune SLMs on mixtures of benign and toxic data, with unsanitized gradients propagating to the server and eroding safety guardrails (RLHF-aligned refusal behaviors). Unlike centralized training—where input data is sanitized via server-side safety filters—federated settings decentralize data without any direct visibility or central filtering, exacerbating vulnerability.
Figure 2: Unintended data poisoning in federated alignment: Centralized settings sanitize raw data, while federated settings allow toxic data to propagate through unaware clients, causing catastrophic safety degradation.
Methodology: Knowledge Distillation and On-Device Sanitization
The cornerstone of FedDetox is efficient on-device data sanitization tailored for resource-constrained Small LLMs (SLMs). The framework consists of two primary stages:
- Knowledge Distillation Pipeline: Safety knowledge from a large teacher model (Llama Guard 3-8B) is transferred via KD to a compact student classifier (MobileBERT), generating lightweight "Guardians" suitable for edge devices. The distillation minimizes a joint loss function combining KL divergence (to align soft teacher logits) and cross-entropy (against hard labels), ensuring the student retains nuanced safety boundaries.
Figure 3: Knowledge distillation pipeline for Guardian: Student model learns safety boundaries on a mixed benign/toxic dataset by optimizing a joint loss over teacher logits and hard labels.
- Federated Direct Preference Optimization (FedDPO) with Refusal Template Replacement: During federated fine-tuning, each client locally deploys the Guardian. Detected toxic samples are not simply discarded; they are transformed into preference pairs, explicitly favoring refusal templates over the original toxic responses. This direct negative supervision aligns the SLM’s policy to robustly refuse unsafe outputs, rather than merely avoiding exposure to toxicity—mitigating "knowledge voids" that naive filtering creates.
Local sanitization, decision making, and template replacement are enacted strictly on-device, maintaining privacy by never exposing raw data upstream. The Guardian's minimal footprint ensures negligible latency and memory impact, crucial for edge deployment.
Empirical Validation
Classifier Distillation
The distilled dataset aggregates diverse sources to maximize hazard coverage across the MLCommons taxonomy, fortifying the Guardian against both overt and subtle adversarial prompts.
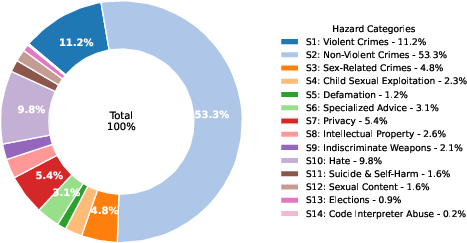
Figure 4: Hazard category distribution of the distilled dataset spanning multiple sources for comprehensive safety coverage.
Effect of Poisoning and Defense Efficacy
Unintended poisoning severely elevates the Attack Success Rate (ASR) across both static and dynamic jailbreak benchmarks. The original instruct-aligned SLM has low ASR (10.8%), while poisoned variants spike to ASR 77.0% (TAP), indicating catastrophic failure of safety guardrails. FedDetox restores model integrity, attaining ASR 14.0% (AdvBench) and 61.0% (TAP), closely aligning with the original instruct baseline and outperforming naive defenses.
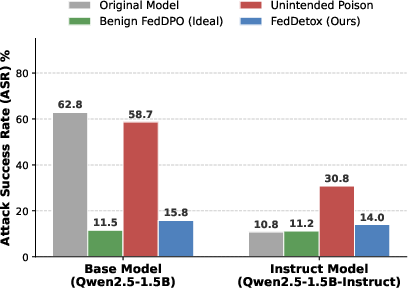
Figure 5: Impact of poisoning and defense efficacy. Unintended poisoning erodes safety in both base and instruct models, while FedDetox restores robust safety boundaries comparable to ideal benign baselines.
Utility Preservation
Safety-aligned models often suffer from reduced general utility ("alignment tax"). FedDetox maintains high performance on TruthfulQA (38.9%), MMLU (59.1%), and GSM8K (55.4%), showing negligible degradation relative to benign-only fine-tuned SLMs or the original backbone.
Ablation: Refusal Template Replacement Necessity
Discard-only strategies yield a significantly higher ASR (25.6%) than template replacement (14.0%), empirically confirming that explicit negative supervision from synthetic preference pairs is essential for robust safety boundary formation.
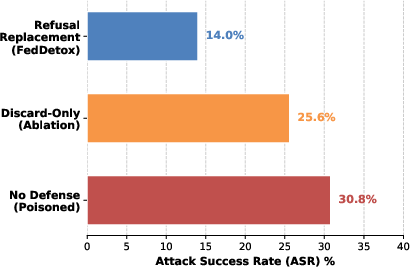
Figure 6: Ablation study: Refusal template replacement yields superior safety alignment (lower ASR) compared to naive discard-only filtering.
Practical and Theoretical Implications
FedDetox sets a new standard for scalable, privacy-preserving safety alignment in federated SLMs, effective even on highly resource-constrained devices. The Guardian distillation approach demonstrates that complex semantic safeguards can be reliably compressed and deployed locally, superseding simplistic keyword or heuristic filters. The refusal template mechanism ensures models do not merely “ignore” toxicity but actively learn robust refusal behavior, critical for mitigating emerging jailbreaks and adversarial prompt engineering—especially in environments where clients are non-malicious and unaware.
From a theoretical standpoint, this work underscores the vulnerability of alignment processes in FL to local data distributions and proposes an instance-level, semantic-centric defense paradigm. The methodology is extensible to evolving safety taxonomies and adversarial contexts, future-proofing federated SLM training as LLMs are increasingly deployed at scale in privacy-critical applications (personal assistants, medical chatbots, etc.).
Future Directions
Promising avenues include continual distillation from evolving teacher models to adapt Guardians in situ, integrating federated adversarial detection for dynamic template synthesis, and optimizing the trade-off between safety and utility via adaptive thresholding. Expansion to multimodal federated alignment (text+vision) and integration with client-side differential privacy mechanisms are also anticipated.
Conclusion
FedDetox decisively addresses unintended data poisoning in federated SLM alignment by deploying lightweight, semantically rich Guardians for on-device sanitization, coupled with explicit refusal template supervision. The framework preserves privacy, restores robust safety guardrails against both static and dynamic attacks, and maintains general model utility—demonstrating suitability for future federated AI deployments where safety, privacy, and efficiency are paramount.

