- The paper introduces LASER, which integrates SQL-MCTS for generating challenging slow queries and SQL-GRPO for RL-based optimization.
- It demonstrates substantial latency reduction—from 69.73s to 13.03s—and cost efficiency using compact models locally deployable with 32-40GB VRAM.
- The methodology enhances query performance via complexity-adaptive rollouts, Anchored Group Advantage, and verification-driven self-correction.
LASER: A Data-Centric Framework for Efficient SQL Query Rewriting Based on SQL-GRPO
Motivation and Background
The paper presents LASER, a data-centric approach targeting efficient SQL rewriting for performance optimization in DBMSs, specifically leveraging compact Small LLMs (SLMs). Traditional query rewriting approaches rely on either rule-based heuristics, which are brittle and lack adaptivity, or LLM-driven workflows, which introduce prohibitive inference costs, latency, and severe privacy concerns—especially when proprietary APIs handle sensitive SQL and schema data. The Chinchilla scaling law enforces the paradigm that high-quality, diverse data is more crucial than sheer model size for downstream performance in domain-specific settings. However, training compact models for SQL optimization is hampered by the lack of high-quality, structurally complex slow-query benchmarks and ineffective RL-based optimization pipelines.
System Architecture
LASER synergistically unifies two major modules: slow query generation via SQL-MCTS and SQL query optimization policy training via SQL-GRPO.
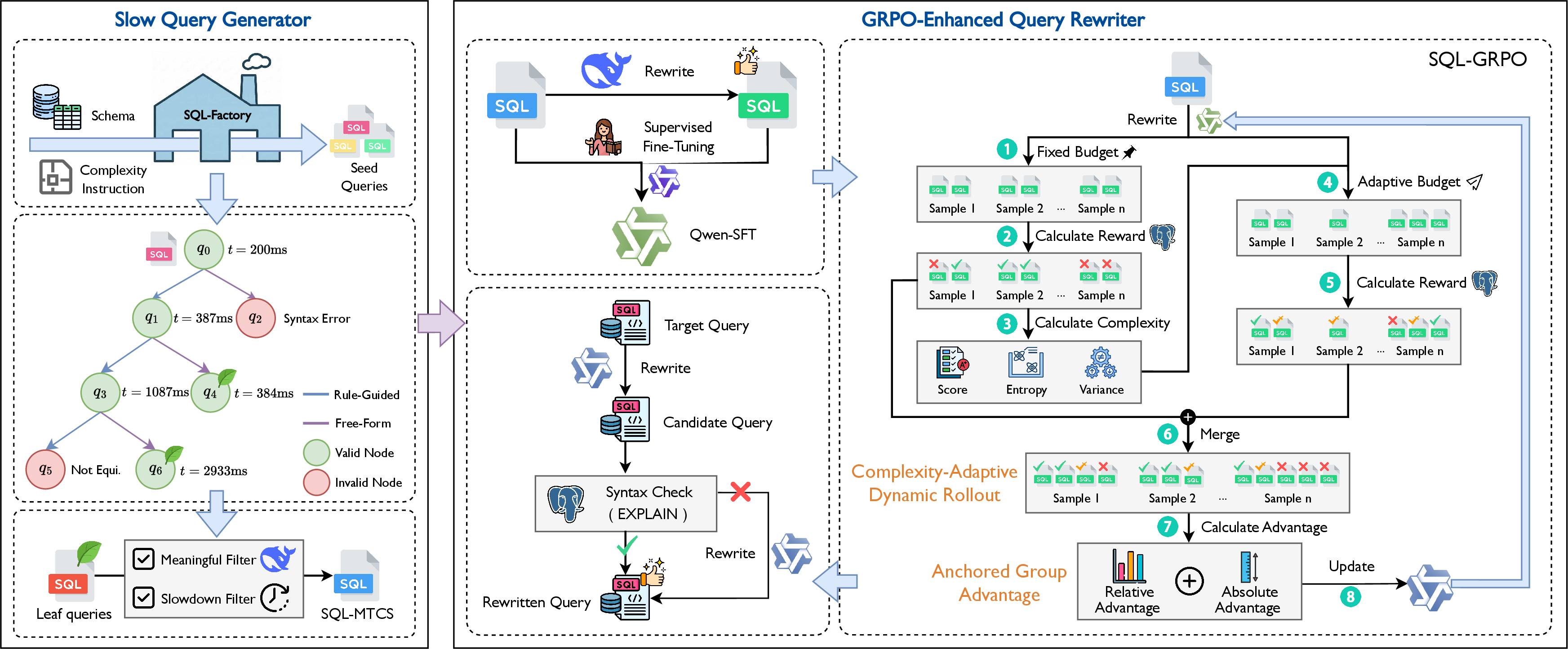
Figure 1: LASER framework architecture integrating slow-query generation and GRPO-enhanced optimization policy training.
Slow Query Generator: SQL-MCTS
SQL-MCTS systematically constructs a large corpus of semantically equivalent but computationally degraded SQL queries, which serve as challenging benchmarks for training optimizers. Seed queries are initialized by injecting structural constraints to ensure multi-table joins, deep nesting, and dense predicates, explicitly avoiding bias towards trivial, shallow queries. Subsequent expansion utilizes a hybrid MCTS-based workflow: anti-patterns derived from reversed optimizer rules and free-form LLM-based mutations expand the search space. Each step is grounded by execution feedback for reward assignment, including strict semantic equivalence via sorted result-set hashes and structural novelty via AST-based tree edit distance metrics.
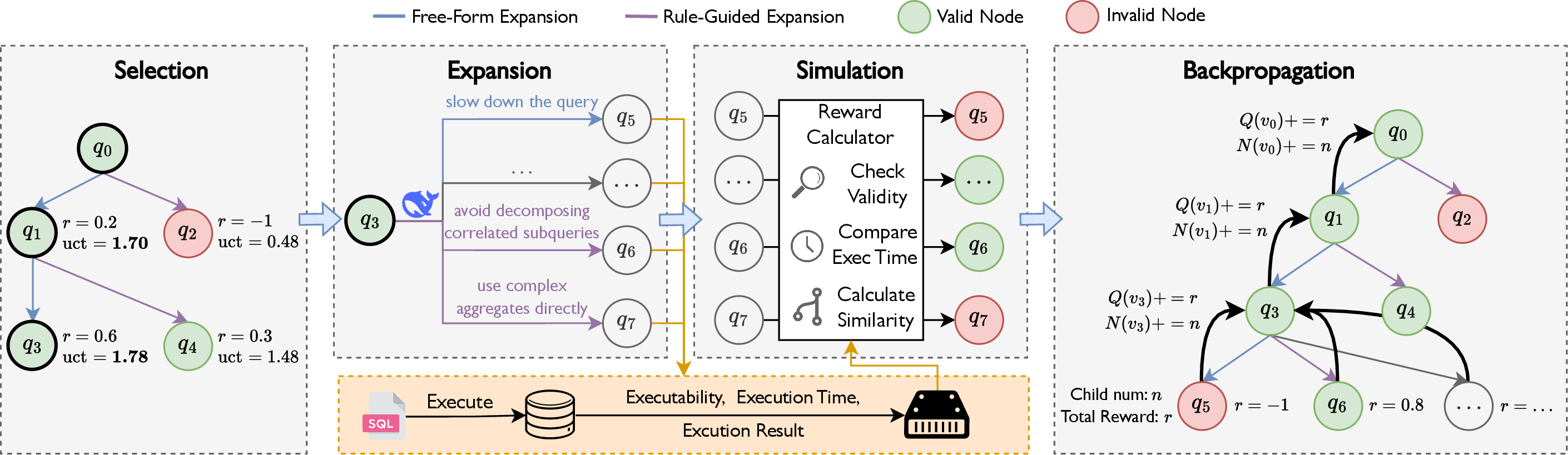
Figure 2: Workflow of MCTS-Driven Slow Query Generation with rule-guided and LLM-based expansion, and execution-based reward feedback.
SQL-MCTS delivers a training corpus with 11,675 slow queries, each exhibiting execution latency at least twice the reference, filtered for non-trivial structural complexity and semantic coherence, validated via DeepSeek-V3.
Reinforcement Learning Pipeline: SQL-GRPO
LASER initiates optimization with Supervised Fine-Tuning (SFT) on reasoning traces generated by the DeepSeek-R1 model, distilling domain-specific optimization knowledge into the policy. Subsequently, Group Relative Policy Optimization (GRPO) aligns the policy with latency reduction objectives via environment feedback, but with bespoke modifications addressing SQL workload heterogeneity:
Complexity-Adaptive Dynamic Rollout
Rollout budgets adapt on-the-fly based on pilot entropy and reward variance (proxy for query complexity and optimization headroom), ensuring sparse resources focus on challenging queries rather than saturating trivial ones. Empirical results (Figure 3) demonstrate that naive uniform rollout leads to wasted compute on simple queries and insufficient exploration for complex cases.
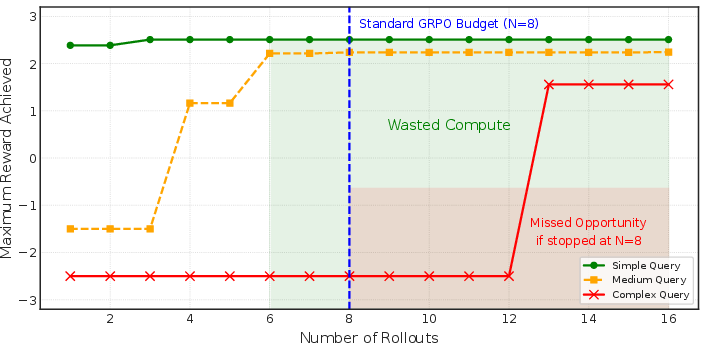
Figure 3: Saturation analysis of rollout budgeting—complex queries demand high exploration budgets for valid optimization.
Anchored Group Advantage
Standard GRPO's groupwise Z-score normalization is vulnerable to inflated reward signals if valid but suboptimal rewrites emerge against a group of invalid candidates. Anchored Group Advantage fuses relative ranking with absolute performance baselines, suppressing false positives and amplifying reward signals for genuine latency breakthroughs. This prevents reinforcement of degradation patterns and improves stability, as elucidated in Figure 4.
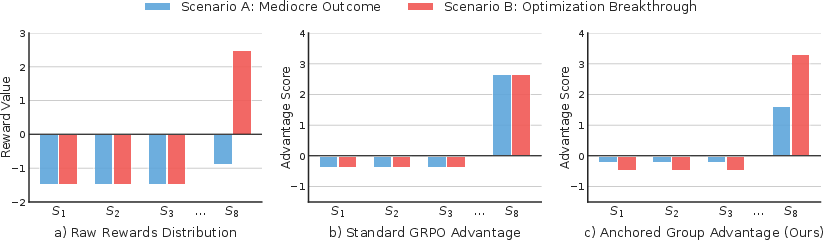
Figure 4: Advantage estimation—Anchored Group Advantage resolves misleading parity between mediocre survivors and genuine breakthroughs.
Verification-Driven Self-Correction
Inference incorporates a closed-loop verification workflow: candidates are first checked via EXPLAIN for syntax integrity before execution. Failures trigger diagnostic feedback loops, enabling self-correction and increasing robustness against parse errors and semantic ambiguity.
Experimental Evaluation
Data Quality and Human Evaluation
SQL-MCTS is benchmarked against TPC-DS, TPC-H, DSB, Calcite, and SQL-Factory. Human evaluation confirms SQL-MCTS queries significantly surpass synthetic benchmarks in optimization non-triviality and structural depth, without sacrificing semantic coherence.
LASER-14B achieves a mean execution time reduction from 69.73s (original) to 13.03s on SQL-MCTS, with 90% equivalence, outperforming DeepSeek-R1, GPT-4o, Qwen3, and all rule-based systems, both in average latency and equivalence across multiple benchmarks.
Cost and Localizability
The LASER models (8B/14B) achieve local deployment, requiring only 32–40GB VRAM, dramatically reducing cost/latency compared to LLM-based and rule-based API workflows that demand >1TB VRAM and incur substantial API call costs (Table: DSB benchmark).
Generalization and Cross-DB Transfer
LASER-trained models generalize robustly to unseen schemas (TPC-H, Calcite) and other database engines (MySQL), achieving state-of-the-art latency reduction and maintaining equivalence without retraining, validating SQL pattern transferability.
Ablation Results
Ablation confirms each component's necessity. Removing SFT, Dynamic Rollout, or Anchored Group Advantage noticeably degrades latency and equivalence. Naive GRPO (E3-Rewrite) fails to handle sparse, complex queries, especially at the 95th percentile. Verification-driven self-correction impacts robustness.
Case Study
LASER successfully eliminates computational redundancy, such as duplicate aggregations in deeply nested queries, by restructuring via Common Subexpression Elimination with CTEs, reducing expensive table scans and overall execution cost.

Figure 5: Example generated slow queries illustrating structural degeneration for optimization training.
Real-world Deployment
In ByteDance enterprise deployment, LASER-14B rewrote 69 production queries; 73% yielded latency reduction, averaging 23% speedup, demonstrating industrial applicability for diverse business scenarios.
Implications and Future Directions
LASER illustrates that with high-quality, structurally challenging data and tailored RL policy optimization (notably GRPO with complexity-Adaptive rollout and anchored advantage), compact SLMs can achieve DBMS-level optimization traditionally reserved for large, resource-heavy models. Local deployability enables privacy-compliant, real-time optimization for production environments. The framework's robust transferability across benchmarks and engines reinforces the utility of data-centric pipelines over parameter-centric scaling, aligning with broader trends in domain-adapted LLM deployment.
Potential future directions include expanding the domain to other SQL dialects and heterogeneous DBMSs, integrating LASER with auto-indexing/subschema optimization, and exploring its synergy with agentic RL pipelines and interpretable SQL optimization rationales.
Conclusion
LASER presents a unified methodology for data-driven, cost-efficient SQL rewrite optimization, leveraging novel slow-query generation and advanced GRPO-based training to enable compact models that exhibit superior latency reduction and equivalence. Distinct results in experimental and industrial settings validate LASER's effectiveness, scalability, and practical transferability for real-world DBMS optimization scenarios (2604.06804).