- The paper introduces DTSR as a model-intrinsic framework that employs reflection signals and sufficiency checks to determine when to halt further reasoning.
- It achieves a token sequence reduction of 28.9% to 34.9% across diverse benchmarks while incurring a negligible accuracy drop (≤1.0%).
- The framework outperforms existing early-exit methods by leveraging third-person self-assessment, ensuring efficient inference in complex reasoning tasks.
Dynamic Thought Sufficiency in Reasoning (DTSR): Early Exit for Efficient LLM Reasoning
Motivation and Problem Statement
Large reasoning models (LRMs) exhibit exceptional performance in complex reasoning tasks by leveraging inference-time scaling and generating long chains-of-thought (CoT). However, these models routinely overthink, producing redundant reasoning stages after reaching correct solutions, thus incurring substantial computational overhead and inefficiency. Early-exit approaches seek to mitigate this inefficiency by terminating reasoning once sufficient evidence is generated. Existing methods (e.g., consistency probing, confidence estimation) rely on handcrafted or statistical criteria, which are unreliable and ill-suited for tasks with open-ended or lengthy answers.
DTSR Framework: Methodological Overview
Dynamic Thought Sufficiency in Reasoning (DTSR) introduces an adaptive early-exit mechanism that enables the model to self-assess the sufficiency of its generated CoT, inspired by human metacognitive processes. DTSR operates in two stages: reflection signal monitoring and thought sufficiency check.
The procedure identifies specific reflection signals within reasoning trajectories (e.g., "Wait", "Alternatively", "But wait") as cue points to perform sufficiency checks. Upon detection, the current CoT is evaluated via a dedicated prompt, and a scalar sufficiency score is produced. If the sufficiency exceeds a threshold (τ), a termination marker is appended, and the answer is generated; otherwise, reasoning continues until the next signal.
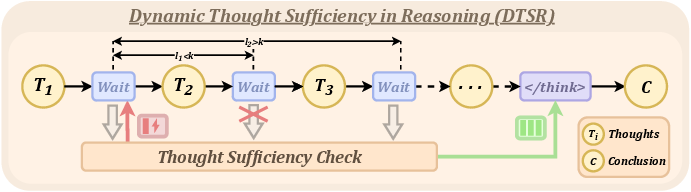
Figure 1: DTSR overview—reflection signals trigger sufficiency checks; upon sufficiency, reasoning immediately exits and a conclusion is formed.
To avoid redundant computation from closely spaced signals, sufficiency checks are only performed at token intervals larger than k, preventing unnecessary overhead and improving efficiency.
Extensive experiments use Qwen3-series models (8B, 14B, 32B) across six benchmarks: GSM8K, MATH-500, AMC, OlympiadBench, GPQA Diamond, and LiveCodeBench. Two primary metrics—accuracy (pass@1) and token count—quantify performance and efficiency.
DTSR achieves a sequence length reduction ranging from 28.9% to 34.9% compared to baseline vanilla models, with negligible performance loss (≤ 1.0% accuracy drop). Notably, DTSR occasionally improves accuracy on challenging benchmarks like OlympiadBench and GPQA. Compared to state-of-the-art training-free baselines (NoThinking, NoWAIT, DEER), DTSR delivers superior accuracy and token savings, particularly as model scale increases.
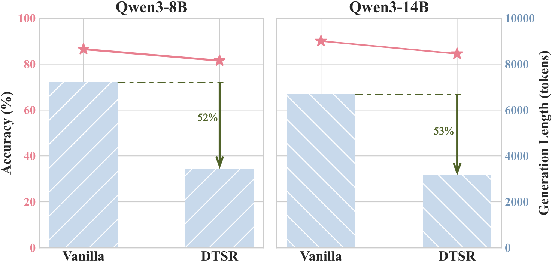
Figure 2: DTSR performance on LiveCodeBench, demonstrating substantial token economy and minimal accuracy loss.
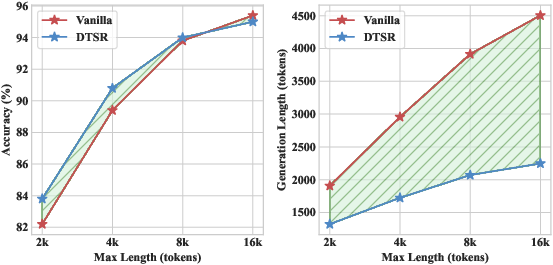
Figure 3: Comparative analysis of Vanilla and DTSR models on MATH-500—DTSR consistently achieves shorter output sequences across increasing token budgets, without compromising accuracy.
Parameter Sensitivity and Ablation
Analyses investigate the effect of token interval (k) and sufficiency threshold (τ). For k≤64, generation length and accuracy remain stable, with excessive checks avoided and latency minimized. Larger k values increase sequence length due to delayed exits. Threshold τ tunes exit readiness; low τ values lead to premature exits and accuracy drops, whereas optimal values (e.g., τ=100) ensure high-confidence outputs.
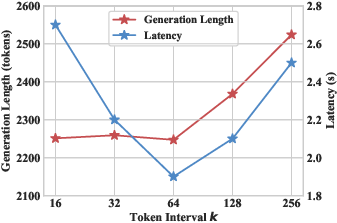
Figure 4: The impact of token interval k—confirming a stable trade-off between token savings and inference latency.
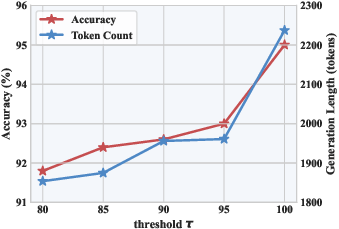
Figure 5: Threshold k0 sweeps—high thresholds guarantee sufficiency and performance; low thresholds risk premature termination and errors.
Comparative Analysis: Early-Exit Paradigms
Contrasted methods include:
- NoThinking: Prompting immediate answers without reasoning, which severely impairs performance on complex tasks.
- NoWAIT: Suppression of reflection tokens, disrupting intrinsic reasoning mechanisms and degrading accuracy.
- DEER: Confidence-based exit using intermediate answer entropy, which underperforms due to overconfidence and inability to handle non-fixed-format answers.
DTSR's self-assessment focuses on the coherence and sufficiency of the entire reasoning trace rather than partial answers or token-level heuristics, resulting in reliable early-exit detection and superior performance.
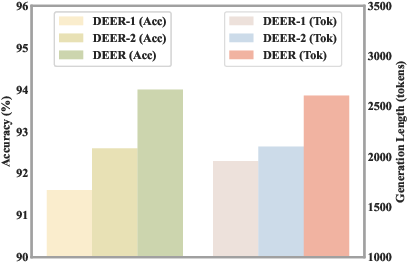
Figure 6: DEER and its variants’ accuracy—models relying solely on confidence scores are prone to overconfidence; intrinsic self-evaluative behaviors (e.g., generating </think>) prove more reliable.
Self-Evaluation Paradigms
DTSR distinguishes between first-person (direct) and third-person (detached) sufficiency assessment. Empirical results show that third-person evaluation—where the model judges sufficiency from an external standpoint—is markedly superior in both accuracy and generation length, highlighting the importance of separation between reasoning and sufficiency judgment.

Figure 7: Illustration of optimal exit point determination—forcing answer generation after each sentence validates sufficiency and localizes the optimal exit within a reasoning trajectory.
Case Studies
Case analyses showcase DTSR’s practical operation in mathematical, programming, and open-ended reasoning tasks.

Figure 8: DTSR’s stepwise reasoning on a math problem—reflection signals trigger sufficiency checks, leading to early exit with minimal token usage.

Figure 9: DTSR’s approach on programming tasks—efficiently prunes redundant code generation by timely sufficiency assessment.
Theoretical and Practical Implications
The DTSR paradigm advances the field by demonstrating that LRMs can reliably and efficiently self-evaluate the sufficiency of their reasoning processes. This addresses fundamental inefficiencies in chain-of-thought reasoning and introduces a principled early-exit mechanism broadly generalizable across task formats and domains. Theoretical implications include the viability of metacognitive prompting and detached self-assessment in optimizing reasoning model inference.
Practically, DTSR enables scalable and cost-effective deployment of LRMs in settings requiring long-form, deep reasoning (e.g., scientific QA, code synthesis, complex mathematics) without retraining or substantial modifications. Future directions include extension to multimodal reasoning and integration with agentic environments, as well as further exploration of adaptive sufficiency thresholds and multimodal reflection signals.
Conclusion
Dynamic Thought Sufficiency in Reasoning (DTSR) sets forth an effective, model-intrinsic early-exit strategy that leverages metacognitive self-evaluation to reduce computational redundancy in LRMs. By combining reflection signal detection and sufficiency checks at optimally spaced intervals, DTSR achieves strong numerical gains in reasoning efficiency with minimal impact on accuracy, outperforming both prompt-based and confidence-driven baselines. This research enriches understanding of efficient reasoning mechanisms and charts prospects for future developments in adaptive reasoning and scalable AI deployment (2604.06787).

