- The paper presents SQLStructEval, a novel evaluation framework that uses canonical AST representations to reveal structural instability in LLM Text-to-SQL generation.
- It quantifies consistency with metrics like majority ratio, structural diversity, entropy, and robustness, highlighting significant instabilities even among execution-correct queries.
- The study proposes a compile-style pipeline that decouples structural planning from token generation, improving both accuracy and interpretability of generated SQL queries.
Structural Evaluation of LLM Text-to-SQL Generation: SQLStructEval
Motivation and Problem Statement
The proliferation of LLMs for program synthesis and Text-to-SQL translation has foregrounded functional correctness as the primary evaluation metric, typically through execution-based tests. However, this approach fails to account for structural reliability: multiple syntactically distinct SQL queries can yield identical execution results, obscuring meaningful variation in query logic, join paths, aggregation patterns, and interpretability. The paper "SQLStructEval: Structural Evaluation of LLM Text-to-SQL Generation" (2604.06736) introduces SQLStructEval, a structure-aware evaluation framework based on canonical AST representations to expose structural instability and variance—dimensions largely overlooked by standard metrics.
Framework Overview: SQLStructEval
SQLStructEval quantifies how reliably LLMs generate structurally consistent SQL programs by analyzing pooled generations per input and mapping each query to a canonical AST. It introduces four principal metrics:
- Majority ratio: proportion of sampled generations sharing the dominant AST structure.
- Structural diversity: number of distinct structures for a single input.
- Structural entropy: distributional spread over generated ASTs.
- Robustness: sensitivity to semantically invariant input perturbations (paraphrasing, schema reorderings).
Canonicalization removes superficial differences (aliasing, ordering of logical predicates), ensuring focus on the core syntactic and semantic structure.
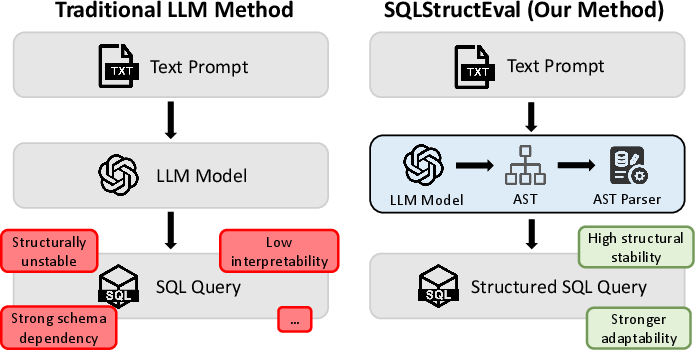
Figure 1: Comparison of direct LLM-based Text-to-SQL generation (prone to structural inconsistency) and SQLStructEval’s AST-based pipeline enabling explicit structural analysis and enhanced stability.
Empirical Analysis: Structural Instability in LLM SQL Generation
An exhaustive evaluation across seven state-of-the-art LLMs (OpenAI, Anthropic, Google, DeepSeek) on Spider reveals systematic structural instability:
- GPT-5-mini yields on average 1.91 distinct ASTs per input across 10 generations; the dominant structure is produced only 65% of the time.
- Even among execution-correct generations, structural diversity remains substantial (1.38 distinct ASTs for GPT-5-mini).
- Execution accuracy misrepresents reliability: 20–39% of questions have execution-equivalent but structurally divergent generations.
Qualitative cases demonstrate that surface-level input perturbations (paraphrasing, minor schema adjustments) regularly induce divergent query plans—different aggregation arguments (COUNT(*) vs. COUNT(col)), join orders, and subquery structures—even when semantics are identical.
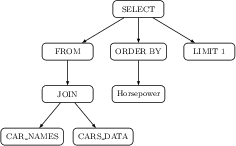
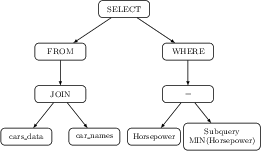
Figure 2: AST of gold SQL query illustrating canonical structural representation used for evaluation and alignment.
Structured Generation Paradigm: Compile-style Pipeline
The study advances a compile-style generation paradigm wherein LLMs output structured intermediate representations (JSON-encoded ASTs) that are later deterministically compiled to SQL. This approach decouples structural planning from token-level synthesis.
- Compile-style generation achieves 0.785 execution accuracy, surpassing direct SQL generation (0.742) and DIN-SQL (0.736).
- AST similarity among execution-correct generations rises from 0.552 (direct) to 0.632 (compile-style), indicating stronger structural consistency.
- This pipeline reliably produces valid structured representations (99.8% JSON validity, 95.9% end-to-end success).
- More distinct structures are explored, but correct programs concentrate around stable canonical patterns.
Error analysis highlights conditional trade-offs: compile-style generation reduces schema linking, logic, join path, and predicate errors but introduces new errors related to intermediate representation compilation. However, structural variance among execution-correct generations (Type E) increases—reflecting improved structural diversity without sacrificing correctness.
Robustness experiments demonstrate pronounced structural sensitivity to semantically invariant paraphrasing:
- GPT-5-mini exhibits only 0.328 cross-paraphrase AST similarity; over 90% of questions are structurally sensitive.
- Stronger models (Gemini 3 Pro) attain 0.894 similarity and reduce sensitivity to 19.5%, but no model achieves true invariance.
Schema perturbations induce less instability; however, even the most robust models maintain a non-negligible sensitive fraction (Claude Opus/Gemini: 6.5%).
The results expose a nontrivial model dependence on superficial linguistic features and schema presentation, undermining claims of stable program reasoning.
Practical and Theoretical Implications
SQLStructEval reveals contradictions in current evaluation paradigms: execution accuracy frequently overestimates model reliability by masking structural inconsistency and instability. LLMs systematically construct context-sensitive, input-dependent program structures—contradicting the expectation of semantic equivalence translating to structural invariance. This finding has profound implications:
- Interpretability and debugging: structurally unpredictable programs are harder to audit and reason about.
- Downstream reasoning and compositionality: structural instability threatens compositional generalization, consistent performance on paraphrased or reordered inputs, and integration in modular AI systems.
- Robustness and safety: instability is a latent failure mode, increasing risk in deployed settings.
The compile-style generation paradigm provides a principled route towards improved stability, decoupling structural decision-making from surface realization and enabling systematic enforcement of intermediate plan validity.
Future Directions
The study motivates several avenues for advancing structure-aware evaluation and generation:
- Extending SQLStructEval principles to broader domains (code synthesis, API orchestration).
- Embedding structural objectives directly in LLM training loops, potentially via reinforcement from canonical AST alignment.
- Exploring stronger grammar- and logic-constrained decoding methods to suppress context-driven structural variance.
- Developing richer semantic metrics beyond canonicalization to distinguish genuine equivalence from structural diversity.
These directions are critical for the maturation of LLM-based program synthesis methodologies and their safe, robust integration in practical applications.
Conclusion
SQLStructEval provides an incisive framework for measuring structural reliability in LLM Text-to-SQL generation, revealing systematic instability masked by execution-centric benchmarks and demonstrating the promise of compile-style structural pipelines for improving both correctness and consistency. The findings necessitate recalibration of evaluation norms and inform the design of future LLM architectures and training criteria, with implications for stability, interpretability, and safety in program-generating AI systems.

