- The paper introduces TwinLoop, a simulation-in-the-loop framework that leverages Digital Twins to accelerate policy adaptation in multi-agent RL.
- It employs high-speed simulated training—up to 25× faster than real-time—to minimize latency and improve responsiveness during dynamic environmental shifts.
- Experimental results in urban grid simulations demonstrate significant reductions in post-shift latency and enhanced adaptation efficiency under high-demand conditions.
TwinLoop: Simulation-in-the-Loop Digital Twins for Efficient Multi-Agent RL Adaptation
Motivation and Research Context
The paper "TwinLoop: Simulation-in-the-Loop Digital Twins for Online Multi-Agent Reinforcement Learning" (2604.06610) tackles the central challenge of adaptation in cyber-physical multi-agent systems operating in dynamically evolving environments. In vehicular edge computing (VEC), agents—vehicles deciding task offloading targets—must adapt rapidly to changes in workload, mobility, and infrastructure. Standard decentralised online RL approaches are hampered by slow convergence and inefficient trial-and-error exploration upon environmental shifts. The authors identify the need for mechanisms that can rehearse adaptation, reducing the reliance on costly online exploration and minimising latency impact in safety- and resource-sensitive settings.
Digital Twins (DTs), synchronised virtual replicas of the physical system, are introduced as a practical foundation for accelerated policy improvement via what-if simulation. The study extends prior DT applications beyond single-agent prescriptive or predictive settings, proposing a tightly integrated, simulation-in-the-loop DT for decentralised, multi-agent RL.
System Architecture and Technical Approach
The TwinLoop framework consists of a DT and its Physical Twin (PT). When environmental context shifts occur—such as workload surges or edge server failures—the DT is triggered to acquire a real-time snapshot of the current system configuration, including agent policy parameters. The DT then performs accelerated RL-based policy improvement in simulation, leveraging high exploration rates and rapid scenario evaluation. Upon completion, updated policy weights are synchronised back to the PT, allowing agents to resume online learning with an improved starting point.
TwinLoop's workflow and architecture are visualised in the figures below:
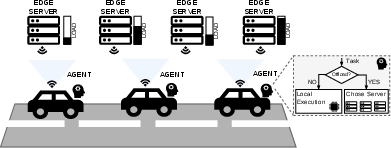
Figure 1: The VEC system model, comprising vehicles and RSU edge servers, forms the substrate for TwinLoop's simulation-in-the-loop adaptation.
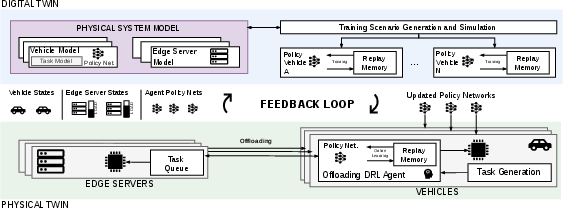
Figure 2: The DT-assisted VEC system architecture, highlighting the interaction between the physical and digital twins during adaptation.
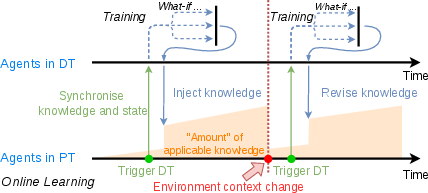
Figure 3: TwinLoop workflow: Snapshot acquisition, DT training, and agent weight synchronisation for online adaptation.
TwinLoop models each vehicle's task offloading as a Markov Decision Process (MDP). Agents observe local and global state features, select task execution targets (local or offloaded), and are trained independently using Dueling Double DQN (D3QN). The DT is capable of executing simulations ∼25× faster than reality, allowing for rapid policy convergence.
Experimental Design
Experiments are conducted in a realistic 2\,km×2\,km SUMO-simulated urban grid with 16 RSUs and up to 65 active vehicles. The evaluation spans three distinct environmental change phases:
Methods compared include TwinLoop (DT-assisted), standard online RL (no DT), an offline baseline, random assignment, and variants adjusting DT trigger frequency and training duration.
Numerical Results and Analysis
Phase-wise mean latency, 90th-percentile, and 99th-percentile latencies are reported. TwinLoop demonstrates strong gains in adaptation efficiency after environmental shifts, particularly during high-demand periods.
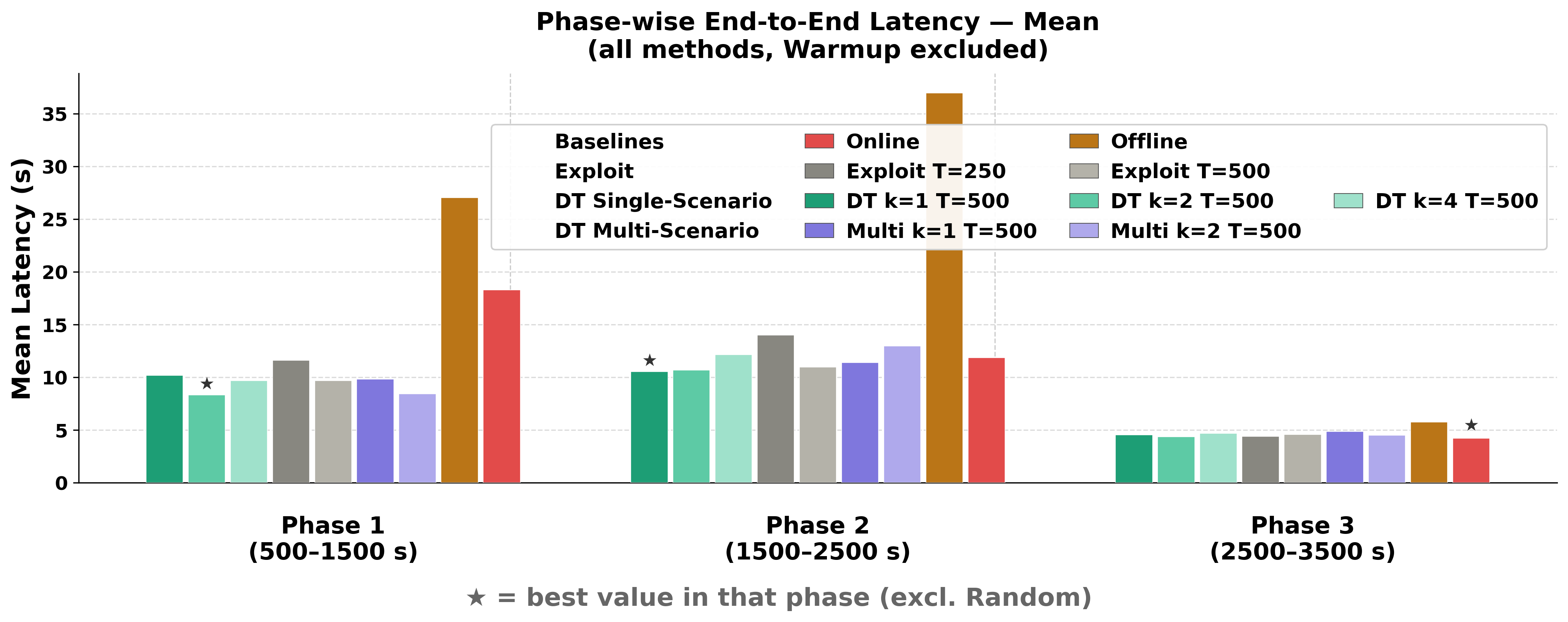
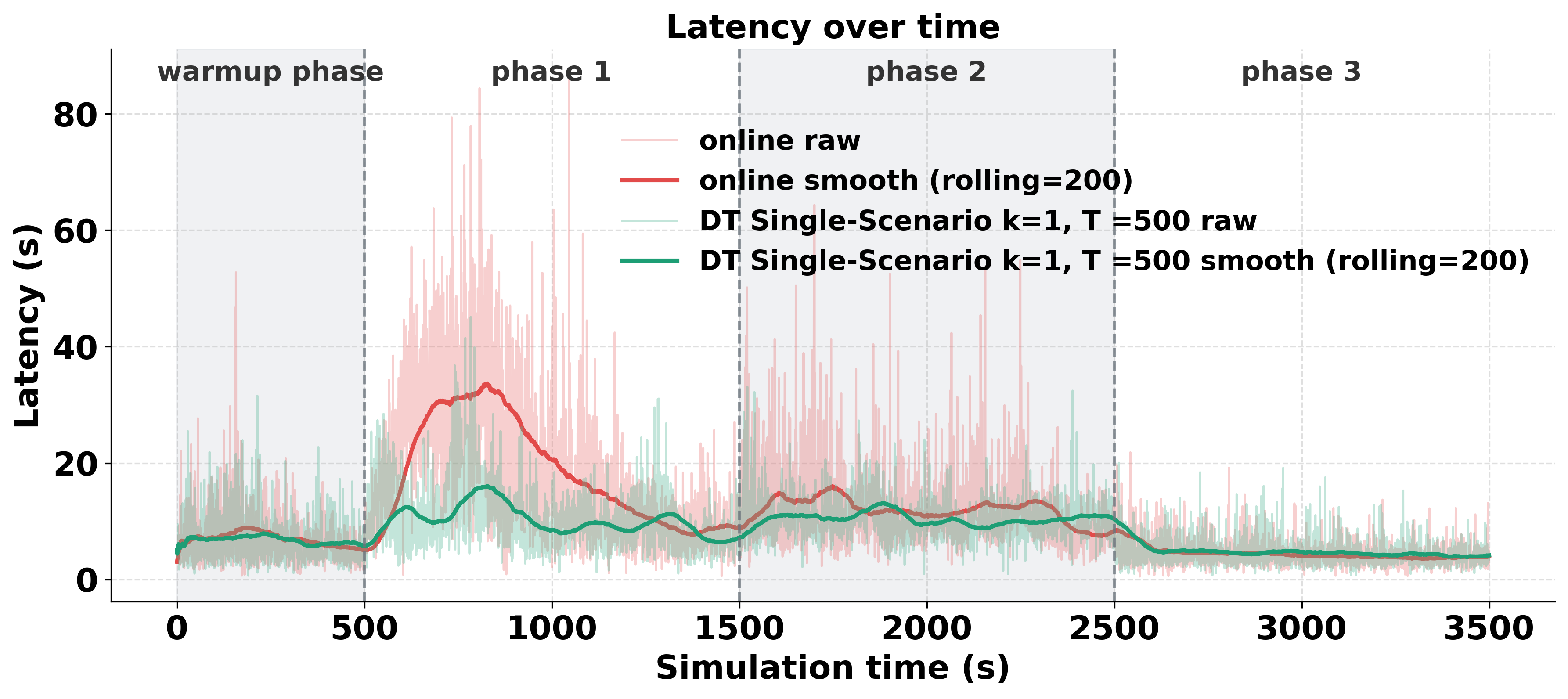
Figure 5: Mean latency per phase shows TwinLoop consistently outperforming baselines in adaptation efficiency, especially in high-pressure scenarios.
Compared to online RL, TwinLoop reduces initial post-shift latency significantly; tail latency suppression is pronounced in demanding phases. The offline baseline rapidly becomes suboptimal under dynamic conditions, validating the necessity of online adaptation. Longer DT training durations yield improved convergence and lower latencies, while excessively frequent DT triggers result in performance regression due to destabilisation effects. Multi-scenario DT training yields marginal differences in homogeneous urban settings but is hypothesised to provide greater benefit in heterogeneous environments. Trigger frequency and adaptive scheduling are highlighted as critical parameters impacting framework efficacy.
Latency trajectory comparison further underscores TwinLoop's advantage in early adaptation cycles, mitigating costly exploration in the physical system.
Practical and Theoretical Implications
TwinLoop provides a robust system for accelerating policy adaptation in multi-agent RL settings subject to recurring environmental shifts. Its approach enables cost-free, high-efficiency exploration in simulated environments, reducing operational risk and minimising real-world latency penalties. Practical benefits are most evident during periods of high environmental pressure—offering system operators improved responsiveness and stability.
Theoretically, the TwinLoop architecture advances the integration of DTs into decentralised learning, demonstrating simulation-in-the-loop adaptation as a convergence accelerator. The activity of synchronising agent policies across the DT-PT boundary serves as a template for broader deployment of prescriptive DTs in dynamic multi-agent systems.
Future Directions
Priorities for future work include the development of adaptive DT triggering mechanisms responsive to detected context shifts, policy merging strategies for incremental policy augmentation, and evaluation across heterogeneous environments to quantify generalisation gains from multi-scenario DT training. Exploration of DT-driven meta-learning and federated adaptation in multi-agent RL settings remains open.
Conclusion
TwinLoop represents a rigorously engineered system for simulation-in-the-loop online RL adaptation in multi-agent VEC environments. Experimental evidence verifies significant improvements in post-shift adaptation efficiency and latency minimisation. The framework sets a foundation for broader exploration of DT-assisted decentralised learning and establishes DT simulation-in-the-loop as a practical strategy for real-time policy rehearsal in cyber-physical systems.