- The paper demonstrates a GPU-accelerated, open-source delay-and-sum beamformer achieving a throughput of 1.1 Tpoints/s for real-time 3D ultrasound imaging.
- It introduces a hybrid delay-caching strategy and optimized CUDA kernels to balance memory usage and compute efficiency, enabling 6× faster reconstruction than acoustic limits.
- Numerical validation shows bit-for-bit equivalence with existing methods while extending accessibility to consumer-grade hardware for advanced imaging applications.
Introduction
The paper "mach: ultrafast ultrasound beamforming" (2604.06257) introduces mach, a GPU-accelerated, open-source Python library focused on volumetric delay-and-sum (DAS) beamforming for real-time ultrafast ultrasound applications. The authors address the critical computational limitations of current open-source beamformers when scaling to 3D ultrafast modalities, such as functional neuroimaging, elastography, and localization microscopy. The system achieves a throughput exceeding 1 trillion points per second on consumer hardware, enabling 3D imaging applications previously accessible only in offline workflows or on specialized computing infrastructure.
Conventional DAS implementations reconstruct each imaging voxel by computing round-trip propagation delays from transmit events through voxels to receiver elements (Figure 1). For 3D ultrafast imaging, this process scales as the Cartesian product of voxels, receive channels, transmit events, and frame count, resulting in orders-of-magnitude higher computational demand compared to 2D imaging.
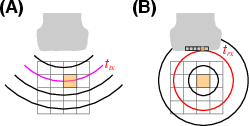
Figure 1: Transmit and receive geometry for pulse-echo ultrasound imaging, highlighting the propagation and reception path for volumetric DAS.
Ultrafast 3D imaging protocols, especially those using large matrix arrays, routinely require throughputs in the teravoxel-per-second range, vastly outpacing the 1010–1011 pts/s achieved by typical existing open-source tools. This gap renders real-time 3D applications infeasible with prior software.
Software Architecture and Optimization
mach implements a hybrid delay-caching strategy: transmit wavefront arrival times at each voxel are precomputed and cached, while receive element delays are computed on-demand. This balances GPU memory footprint, which is prohibitive for fully precomputed delay tables at large 3D scales, against the high arithmetic cost of computing every delay in real time. Further, mach’s CUDA kernel exploits shared memory and memory coalescing—structuring the array dimensions so that time and frame accesses are contiguous—achieving near-peak GPU throughput with 90% memory and 69% compute unit utilization.
The highly optimized CUDA kernel, along with memory layout engineering, ensures that temporal and spatial data are processed with maximal memory transaction efficiency. This enables reconstruction speeds up to 6× faster than the acoustic round-trip time—the theoretical limit imposed by sound propagation (Figure 2).
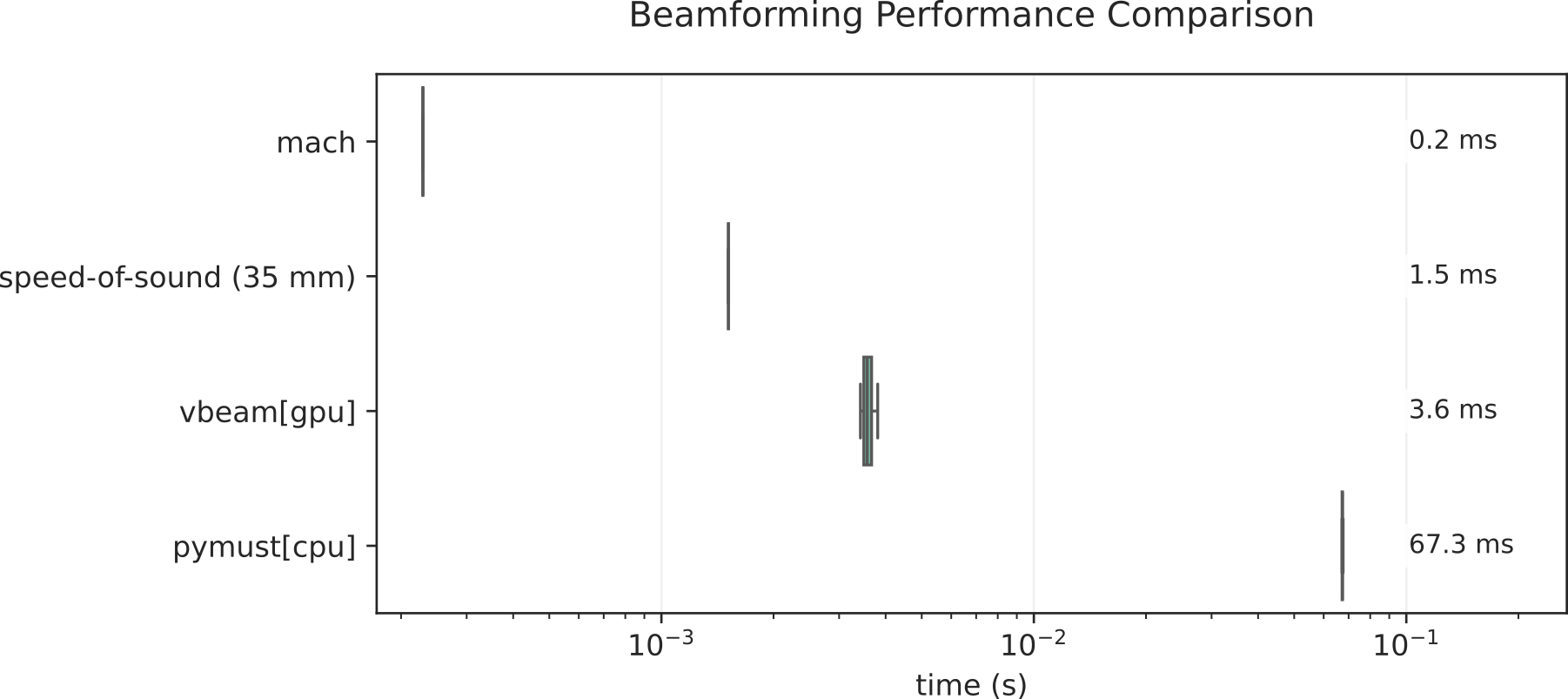
Figure 2: Runtime comparison demonstrates mach’s 0.23 ms reconstruction for the rotating-disk dataset (1.1 Tpoints/s), 6× faster than the acoustic round-trip time.
Usability and Integration
mach’s interface, distributed as a conventional Python package, integrates with NumPy, PyTorch, JAX, and CuPy via the Python Array API standard. The user pipeline involves loading RF/IQ channel data, specifying the reconstruction grid, supplying transmission and array geometry, and performing the core beamforming computation using mach. Comprehensive documentation, example galleries, and interactive (marimo-based) notebooks enhance accessibility (Figure 3, Figure 4).
Figure 3: Screenshot of the mach documentation website showing the example gallery.
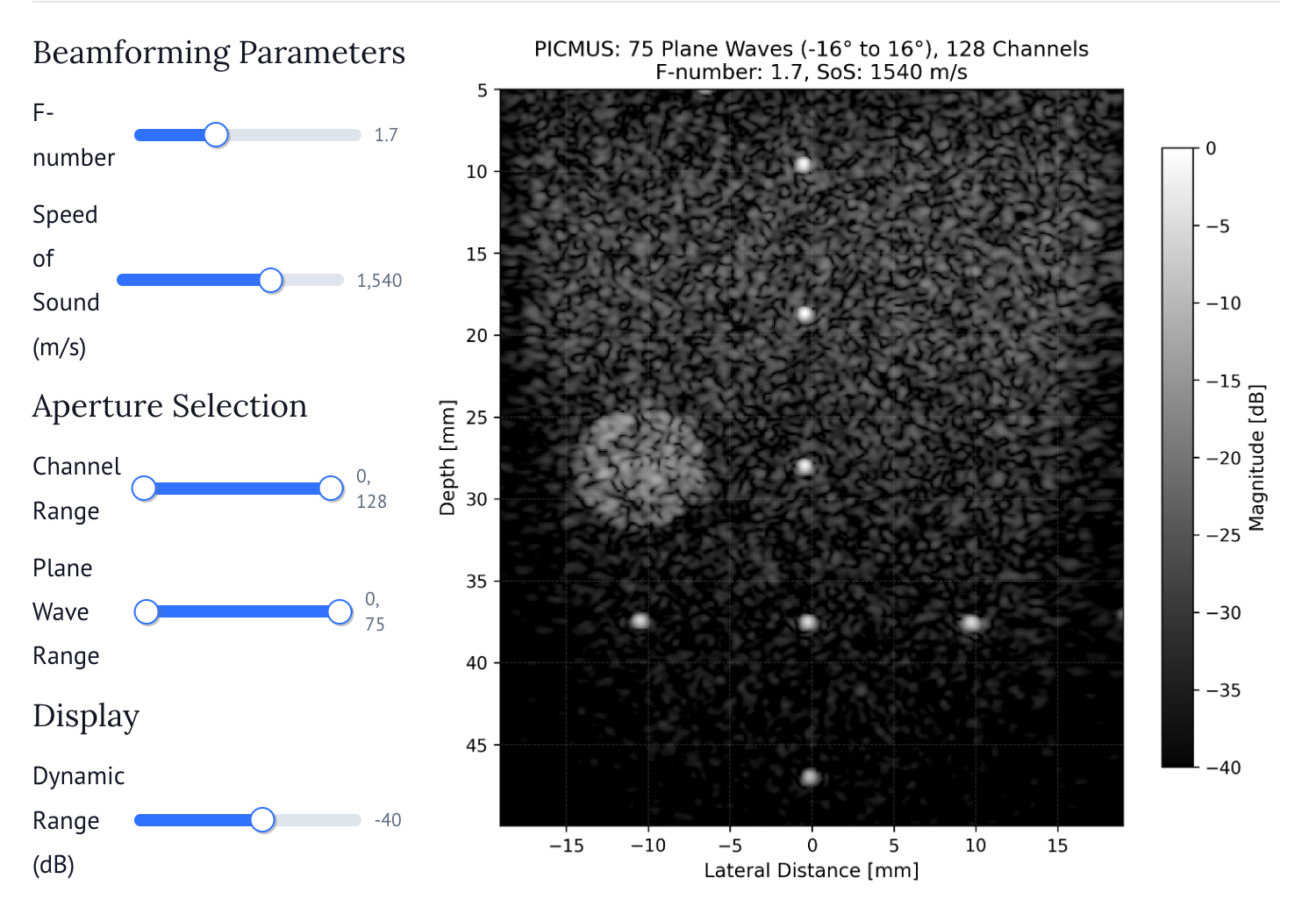
Figure 4: Interactive marimo interface for modifying beamforming parameters on the PICMUS dataset.
The explicit design for GPU interoperability means that downstream postprocessing (e.g., Doppler filtering or machine learning) can occur directly on GPU memory without expensive transfers.
Numerical Validation
Validation against reference implementations demonstrates that mach maintains equivalence to PyMUST and vbeam, with pixelwise differences below −60 dB (Power Doppler) and −120 dB (B-mode), confirming numerical fidelity. Difference imaging reveals only background-level numerical drift, attributable to floating point and hardware-specific arithmetic order (Figure 5, Figure 6).
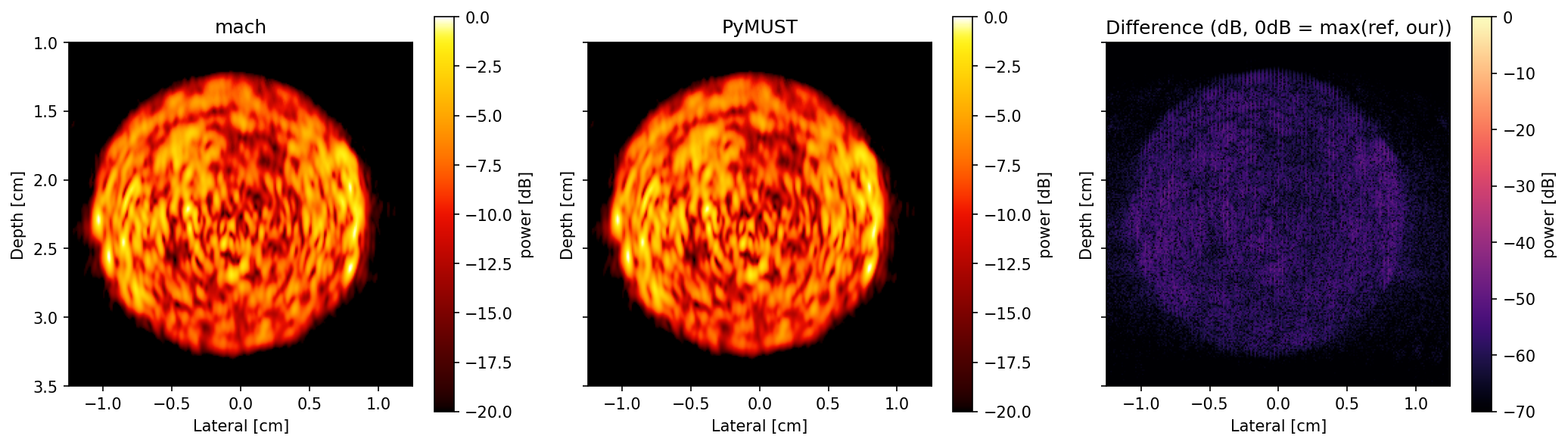
Figure 5: Power Doppler results on the rotating-disk dataset; mach and PyMUST outputs are visually identical with negligible difference (<−60 dB).
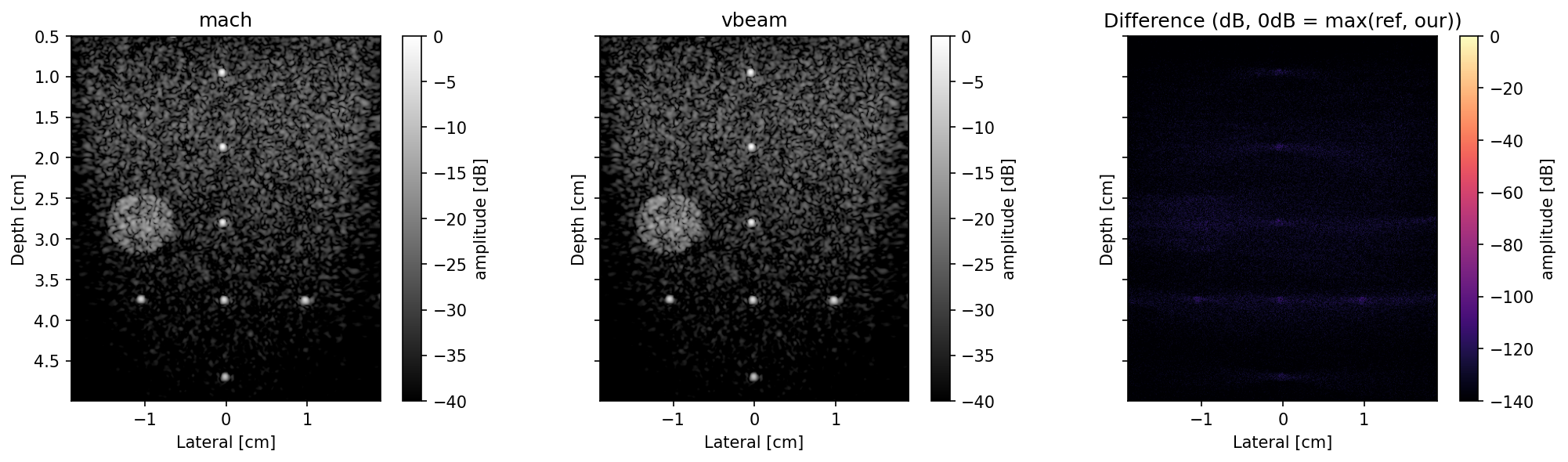
Figure 6: B-mode resolution/distortion validation on PICMUS phantoms; difference images confirm errors are below −120 dB, validating numerical accuracy.
On the PyMUST rotating-disk Doppler benchmark, mach attains 1.1 Tpoints/s, marking a >10× speedup over the fastest existing open-source GPU beamformers (vbeam at 3.6 ms and rtbf at 83 Gpoints/s). Comprehensive scaling analysis demonstrates linear runtime growth with the number of voxels and elements, with constant per-point throughput maintained across practically relevant workload sizes. Only for very low frame counts (<16) do memory coalescing inefficiencies manifest as modest throughput drop (Figure 7).
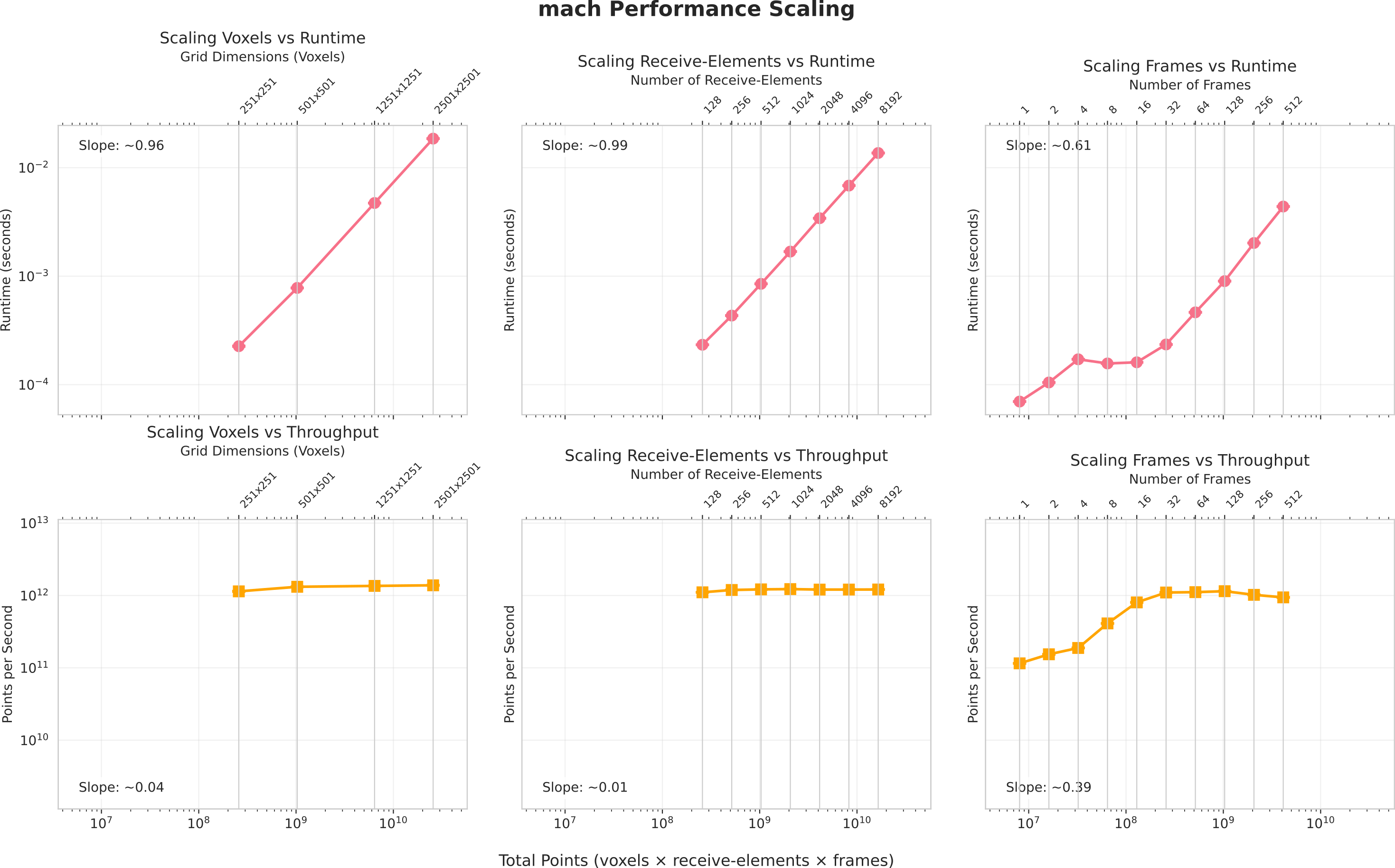
Figure 7: Performance scaling of mach; throughput remains constant across voxel and channel scaling due to memory access and thread block optimizations.
All core computations fit comfortably within the 8–16 GB VRAM envelope typical of current consumer GPUs for most ultrafast 3D imaging workloads.
Application: Real-Time 3D Ultrasound Localization Microscopy
A direct application is demonstrated on a 3D+t ultrasound localization microscopy dataset, involving a full rat brain volume (94 × 94 × 178 voxels, 500 compounded volumes/s, 100,000 volumes total). Maximum-intensity projections of the resulting microvasculature showcase the system’s capacity for high-resolution, real-time volumetric imaging (Figure 8).
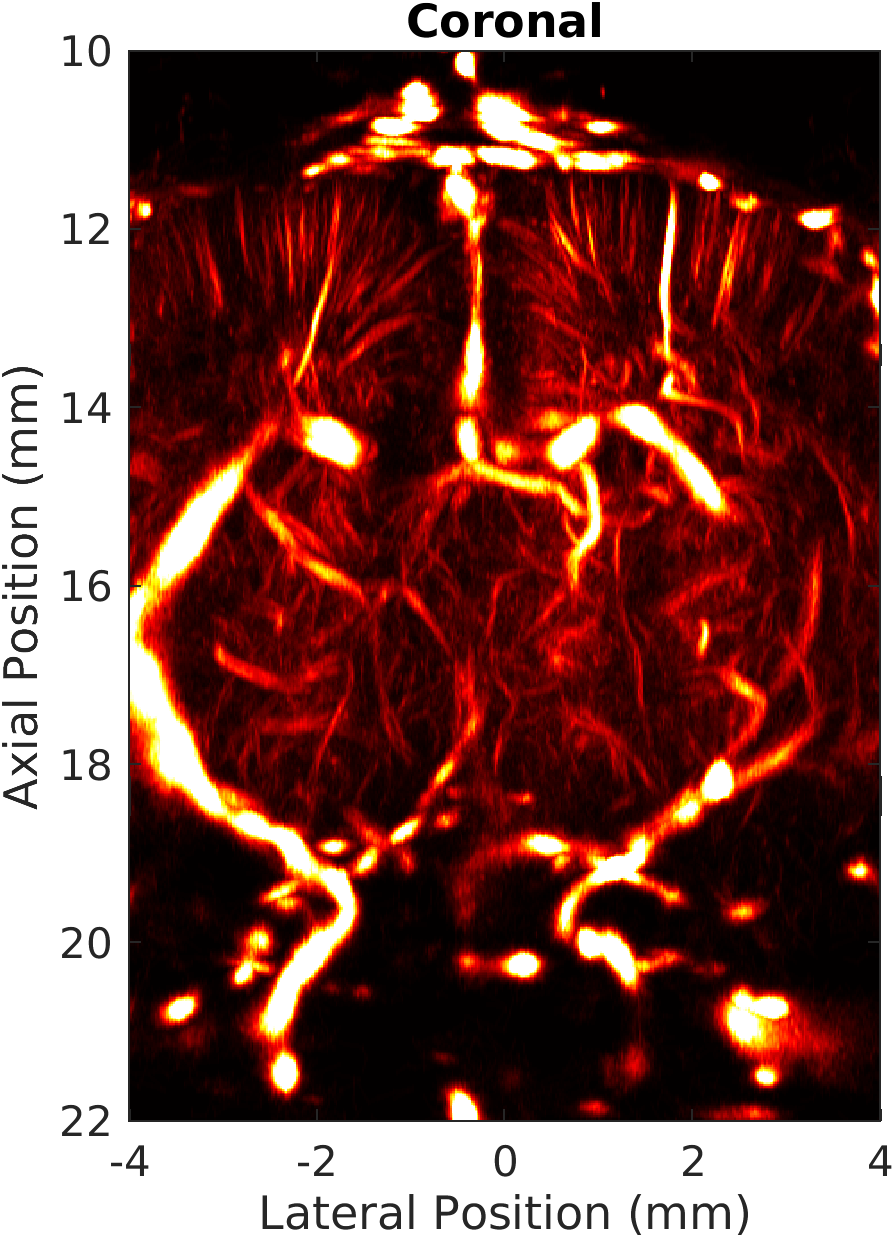
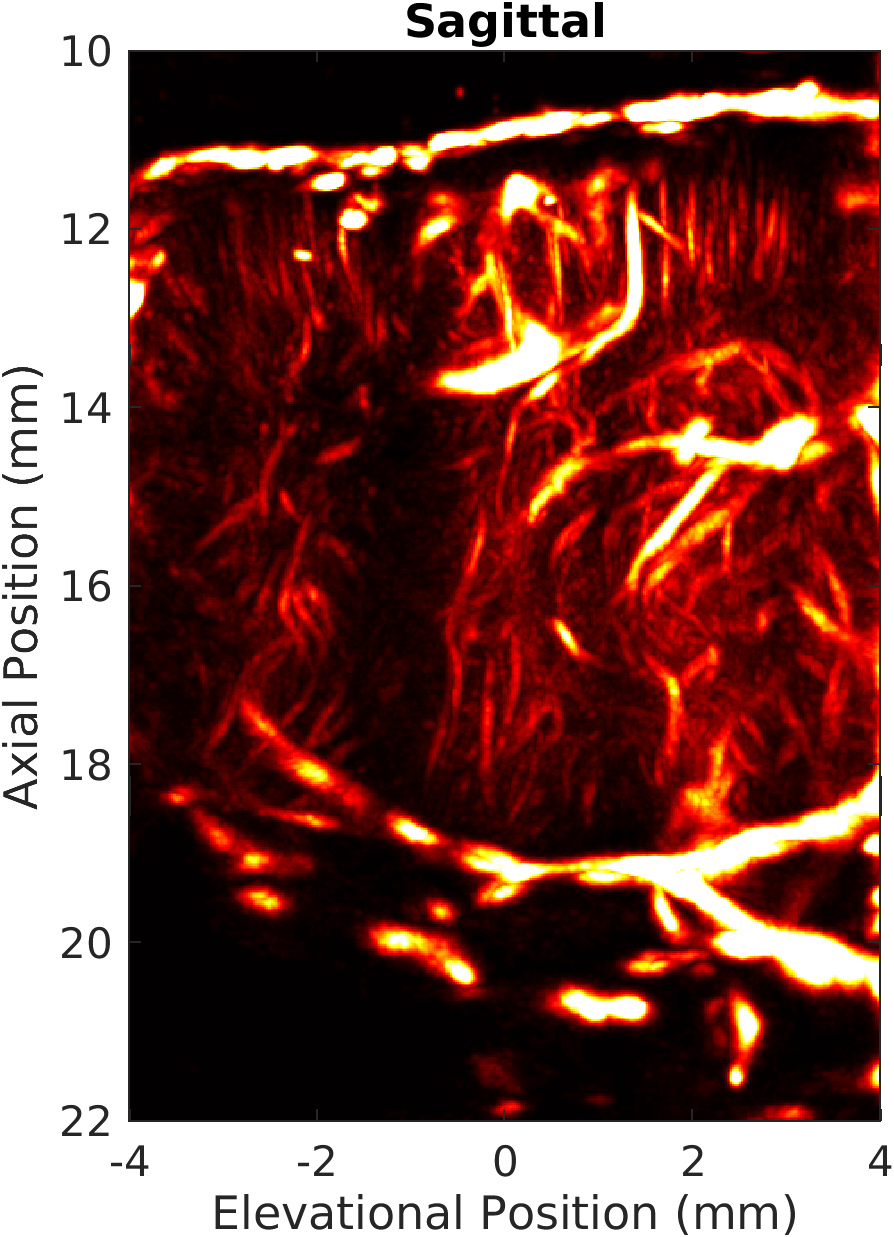
Figure 8: Maximum-intensity projections of 3D rat brain microvasculature; mach enables super-resolved whole-brain imaging with high temporal and spatial resolution.
The delay-and-sum kernel consistently maintains ∼1.0 Tpoints/s throughput in this large-scale scenario, illustrating practical scalability for high-volume experimental modalities.
Implications and Future Directions
mach removes beamforming as the bottleneck in high-throughput ultrasound imaging pipelines, opening prospects for real-time 3D imaging applications that require immediate volumetric feedback—functional neuroimaging, intraoperative navigation, super-resolution microscopy, and elastography. By targeting consumer-grade GPUs, mach lowers the entry barrier for laboratories and clinical units lacking access to large-scale clusters. The integration with array programming standards paves the way for seamless combination with scientific ML pipelines, enabling end-to-end, data-driven ultrasound imaging systems.
The presented hybrid delay computation model and memory layout suggest a framework for future development toward differentiable, trainable beamforming and adaptive model-based or ML-based reconstruction techniques. Furthermore, mach offers a reproducible and open platform for benchmarking further algorithmic advances, both in hardware-targeted optimization and algorithmic innovation.
Conclusion
mach delivers a 10×–290× performance advantage over leading open-source beamformers, attaining 1.1 Tpoints/s throughput with bit-for-bit numerical equivalence. It eliminates the computational bottleneck formerly inherent to advanced 3D+t ultrasound imaging, enabling real-time volumetric functional and microvascular imaging on commodity hardware. The extensible, Pythonic interface and open licensing foster broad adoption and further research, marking a pivotal step toward ubiquitous real-time ultrafast ultrasound applications.