- The paper introduces a multi-modal detection framework combining multi-encoder Vision Transformers with ensemble learning, achieving a state-of-the-art F1 score of 0.919.
- It employs advanced feature engineering with derived spectral indices and statistical descriptors to leverage complementary information from Sentinel-1 SAR and Sentinel-2 optical imagery.
- Ablation studies validate the benefits of modality-specific encoding and ensemble calibration, ensuring robust, patch-level landslide detection in diverse conditions.
Introduction
This study proposes a rigorously structured multi-modal pipeline for landslide detection, focusing on the integration of Sentinel-1 Synthetic Aperture Radar (SAR) and Sentinel-2 optical satellite data. The framework couples multi-encoder Vision Transformer (ViT) architectures with tree-based ensemble methods (LightGBM, XGBoost), leveraging the complementary nature of optical and radar features, augmented by derived spectral indices (e.g., NDVI). It is noteworthy that the methodology targets patch-level (not pixel-level) classification and dispenses with the requirement for pre-event optical imagery, accommodating non-classical change detection scenarios. The approach substantiates its robustness with a state-of-the-art F1 score of 0.919 on a challenging imbalanced dataset, highlighting operational transferability and competitive performance in an established ML competition.
Data Modalities and Feature Engineering
The dataset consists of 64×64 pixel patches (at 10m resolution), with 12 input channels: four from Sentinel-2 (RGB, NIR), and eight from Sentinel-1 (VV, VH, and their pre-post event differences from both orbits). The high-dimensional input is further extended via feature engineering: NDVI, NDWI, and four additional spectral ratio bands, yielding 18 input channels. For GBMs, spatial information is aggregated using seven statistical descriptors per channel (min, max, mean, median, std, skew, kurtosis), producing a compact, high-informative feature representation. Data normalization (percentile-based and standard), and augmentation strategies are systematically applied to maximize generalization.

Figure 1: Sentinel-2 RGB image and corresponding pseudo-RGB SAR composite illustrate visual distinctions leveraged by the framework.
The core architectural advancement is the modular multi-encoder ViT ensemble. Each data modality is processed by a dedicated, pretrained lightweight encoder (MaxViT, various ViT variants, CaFormer), implemented with the PyTorch/timm stack. Modalities are not simply concatenated, but instead encoded independently before feature fusion. The network concatenates latent modality representations, which are then processed by residual and normalization blocks, followed by a sigmoid classifier head. This separation was empirically shown to outperform single-encoder, all-band stacking (increase in OOF F1 from ≈0.85 to ≈0.90).
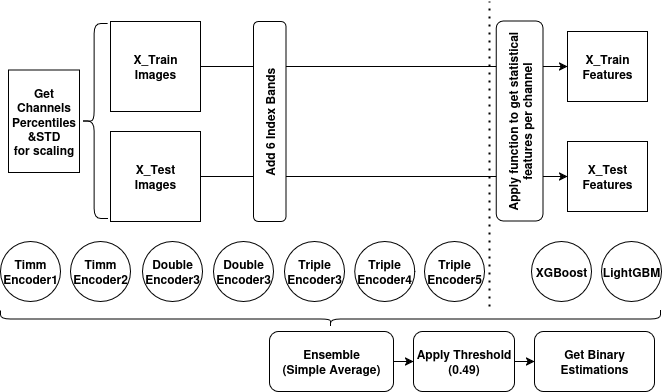
Figure 2: Flowchart of data processing and integration within the ensemble learning framework.
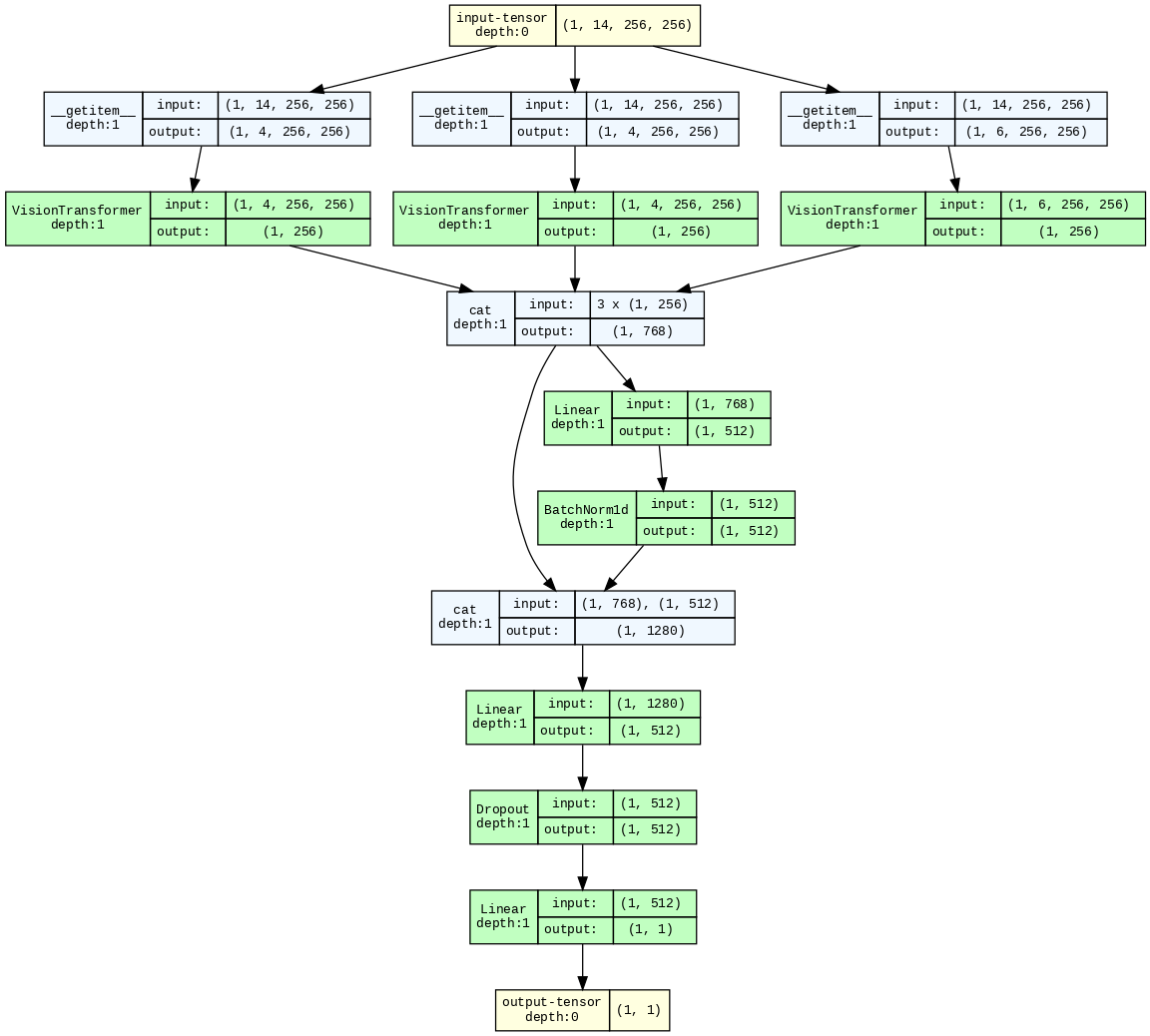
Figure 3: Network-level model with three independent modality-specific encoders, emphasizing explicit feature disentanglement prior to fusion.
Training and Ensemble Learning
Model optimization is guided directly by the F1 metric with a composite loss (BCEWithLogits + SmoothF1) and 5-fold cross-validation. Ensemble calibration employs out-of-fold predictions for threshold selection (optimal threshold at 0.49). The final ensemble comprises seven NNs (with diverse modality and scaling schemes) and two GBMs, with average probabilities binarized for final classification. Neural models benefit substantially from ImageNet pretraining, leading to improved convergence and mitigated overfitting, as evidenced by nearly matched training and inference performance metrics.
The multi-modal ensemble achieves an F1 score of 0.919, with AUC scores consistently >0.99 across all major components. On the private and public leaderboard splits of the test set (ML competition), the proposed solution consistently ranks at or near the top.
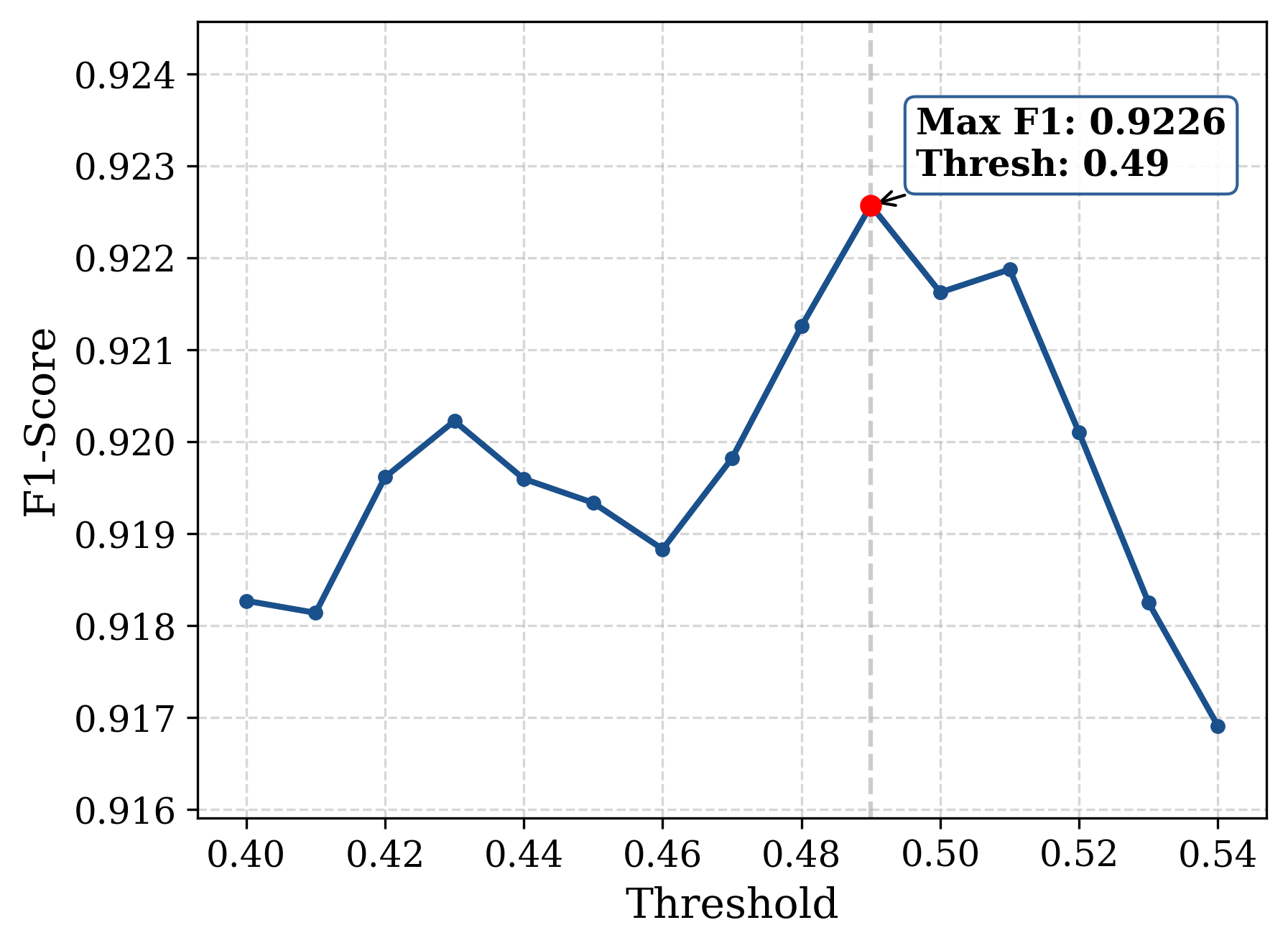
Figure 4: OOF F1-score as a function of classification threshold shows robustness and optimal binarization calibration.
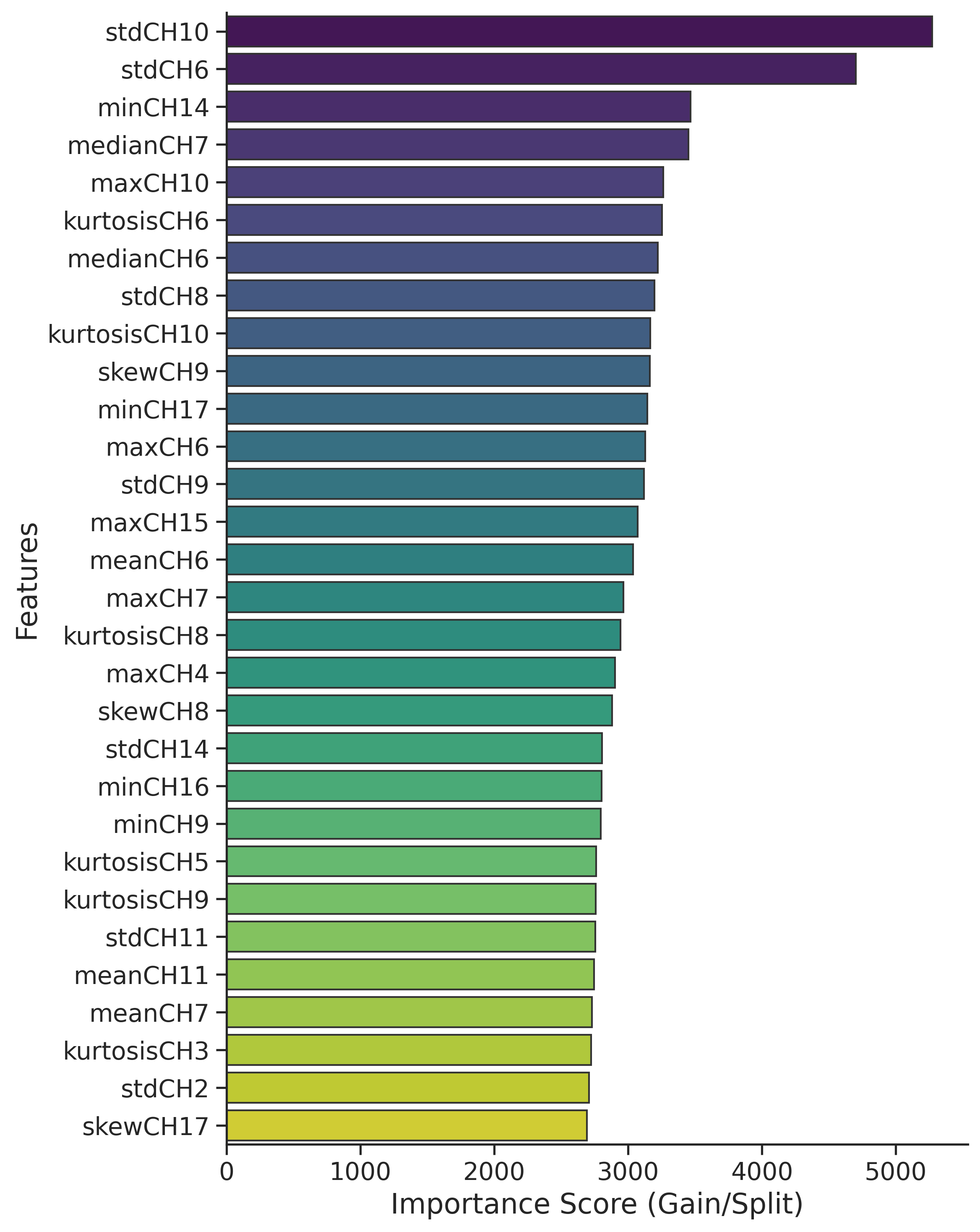
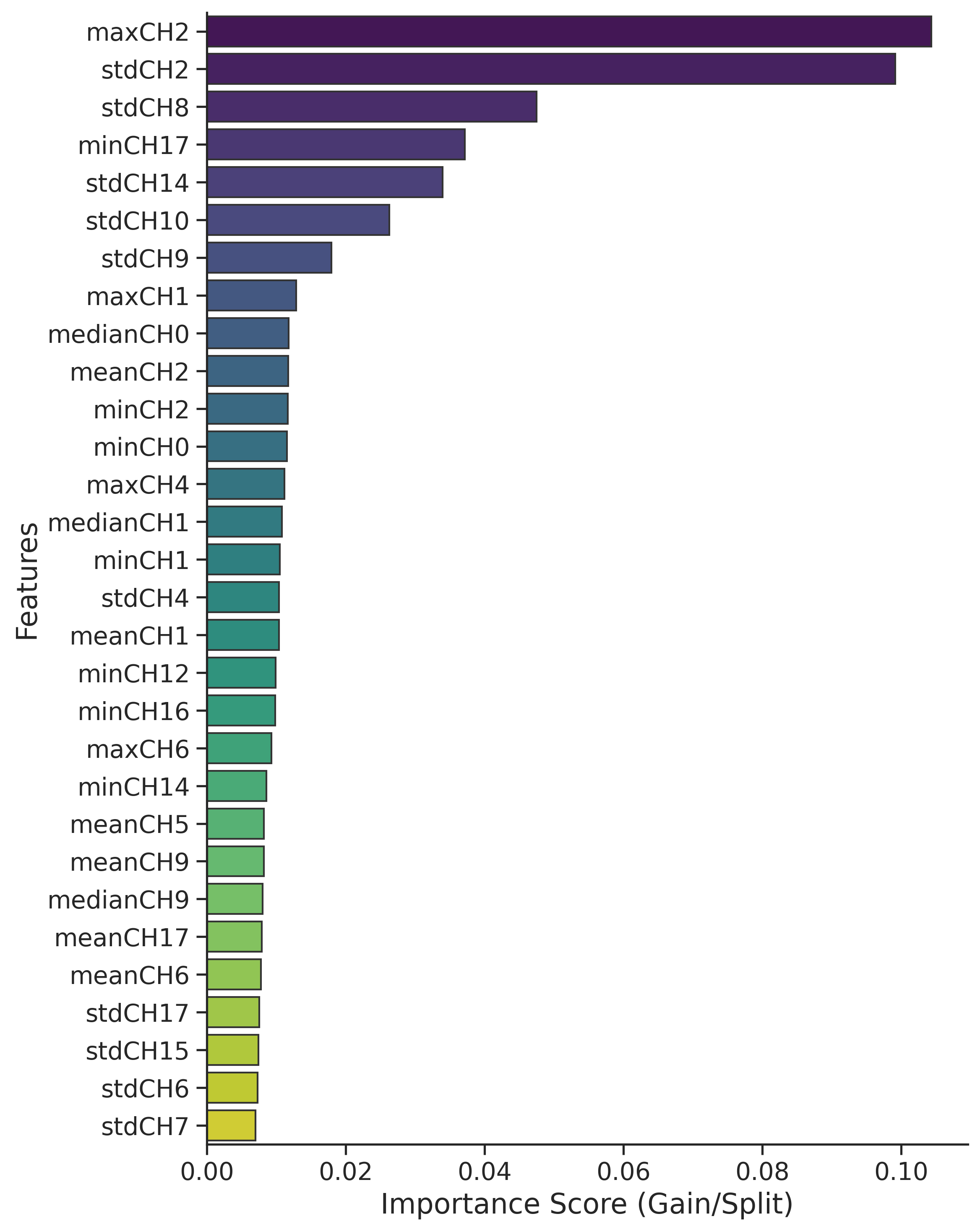
Figure 5: Feature importance plot from GBMs reveals dominance of standard deviation on engineered SAR and optical features; NDVI and SAR-difference bands are highly ranked.
Ablation studies provide several critical insights:
- Removing any source degrades GBM performance, with Sentinel-2 derived indices providing more discriminative power compared to raw optical or SAR bands alone.
- Standard deviation features are most predictive among statistical moments, aligning with the physico-geometric nature of landslide disturbance.
- Multi-encoder ViT architectures robustly outperform both single-encoder ViTs and traditional CNNs (EfficientNet, ConvNeXt, EdgeNeXt)—a finding congruent with recent literature on the advantages of global self-attention in geospatial vision tasks.
- SAR-only modalities underperform relative to optical or fused models, but still contribute to ensemble resilience, particularly under adverse weather/cloud cover.
ROC and Interpretability
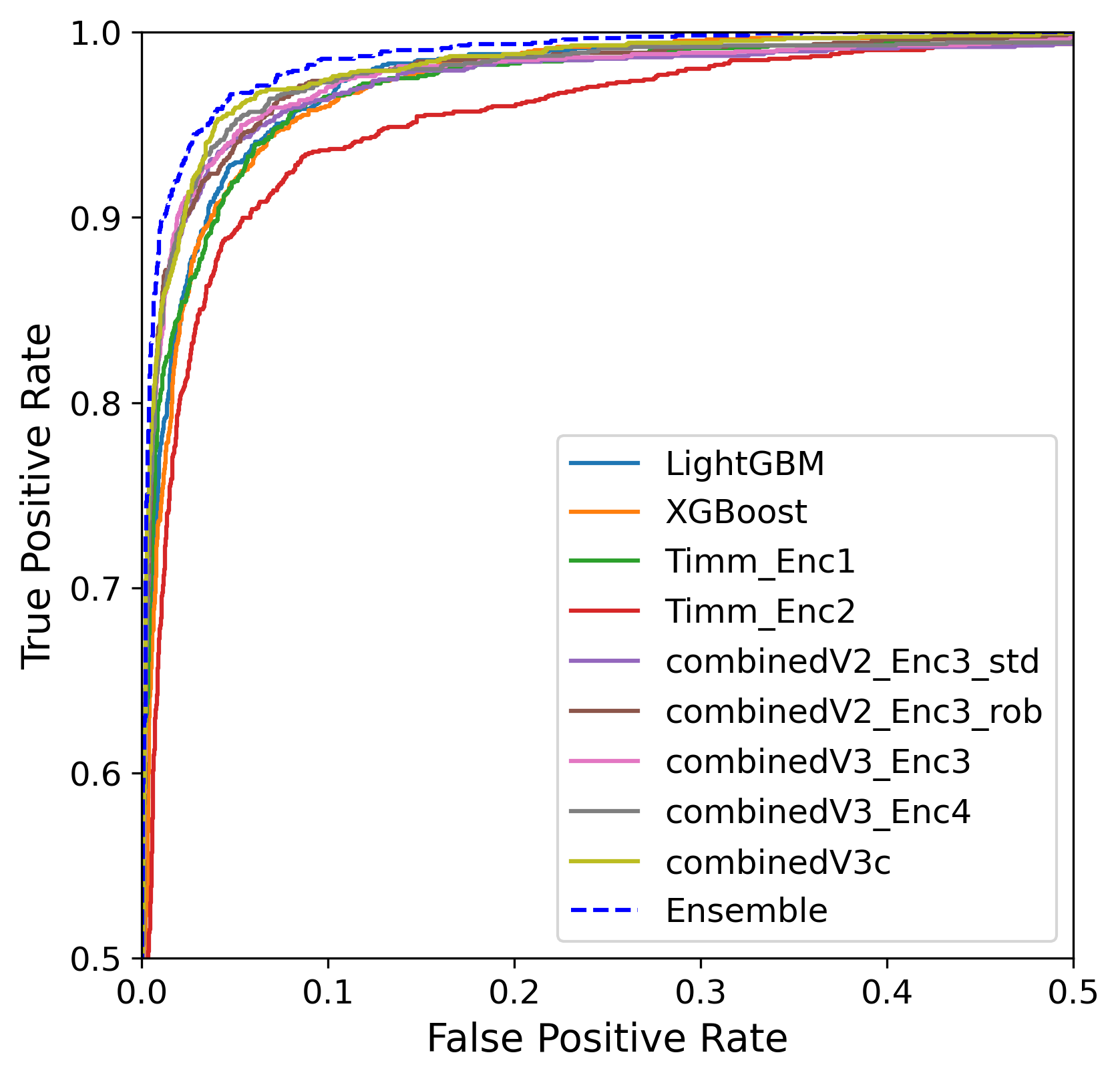
Figure 6: ROC curves demonstrate near-perfect discrimination for both NN and GBM ensemble variants.
The ensemble classifier maintains high precision (~95%) and recall (~90%), balancing omission and commission errors, essential under positive class rarity.
Operational and Computational Considerations
All NNs utilize lightweight transformers; GBMs run efficiently on CPU-class hardware, suitable for both resource-constrained and GPU-enabled settings. Inference times are sub-minute per thousand images (on T4 GPU/Colab), and end-to-end modularity enables deployment with any subset of available modalities (optical or SAR only).
Limitations
Several practical limitations are recognized:
- Methodology increases complexity and inference time over single-model baselines—temporal scalability should be evaluated on very large-scale deployments.
- Lack of acquisition metadata restricts the interpretation of domain shifts and real-time adaptability.
- Exclusively patch-level (not segmentation) labeling may limit applicability for fine-resolution hazard mapping without additional post-processing.
Theoretical and Practical Implications
This work robustly demonstrates the efficacy of modular multi-modal fusion for disaster geointelligence, with:
- Multi-encoder ViT architectures establishing a new standard in remote sensing change/hazard classification.
- Ensemble learning mitigating single-model brittleness and improving operational trustworthiness.
- Explicit ablations clarifying the roles of different physics-based features and machine learning paradigms.
The framework's modularity supports adaptation to other environmental monitoring contexts (flood, burn scar, earthquake), admitting extensions to time-series fusion (multi-temporal Sentinel-2), inclusion of SWIR bands for improved moisture sensitivity, and InSAR feature augmentation.
Conclusion
The proposed ensemble framework, combining multi-encoder vision transformers and gradient boosting machines with extensive feature engineering, delivers state-of-the-art performance for landslide detection from Sentinel-1 and Sentinel-2 satellite data (2604.05959). This methodology validates the theoretical advantage of modality-specific encoding and ensemble inference, and—supported by comprehensive empirical ablation—provides a clear, reproducible pathway for robust multi-sensor geohazard mapping at operational scales. Future developments will likely extend this paradigm to broader hazard categories and leverage further increases in sensor diversity and temporal richness.