- The paper introduces MARL-GPT, a unified transformer-based model that learns general policies from multi-agent expert trajectories across diverse environments.
- The model uses a universal observation encoding with structured positional embeddings to process heterogeneous, multimodal MARL inputs, ensuring robust coordination.
- Empirical results demonstrate competitive performance on SMACv2, GRF, and POGEMA with strong generalization and efficient online fine-tuning.
MARL-GPT: Towards a Foundation Model for Multi-Agent Reinforcement Learning
Motivation and Problem Setting
While recent advances in multi-agent reinforcement learning (MARL) have enabled competitive results in high-dimensional domains, such as StarCraft and multi-agent navigation, contemporary solutions depend on bespoke models and task-specific training regimens, resulting in poor cross-domain generalization and substantial engineering overhead. The pursuit of a unified, transformer-based foundation model for MARL—analogous to the impact of GPT architectures in NLP—remains a central challenge in the field.
This work proposes MARL-GPT, a single architecture trained offline from expert multi-agent trajectories to achieve strong, general policies across diverse environments (SMACv2, Google Research Football (GRF), and POGEMA) without architectural modifications or separate policies.
Model Pipeline and Encoding Approach
MARL-GPT’s pipeline begins with collecting extensive expert policy rollouts across heterogeneous multi-agent domains, utilizing high-performing RL policies and/or centralized solvers to obtain diverse observation-action-reward triplets. This process enables task-agnostic skill aggregation and the construction of a large-scale, multi-task demonstration dataset.
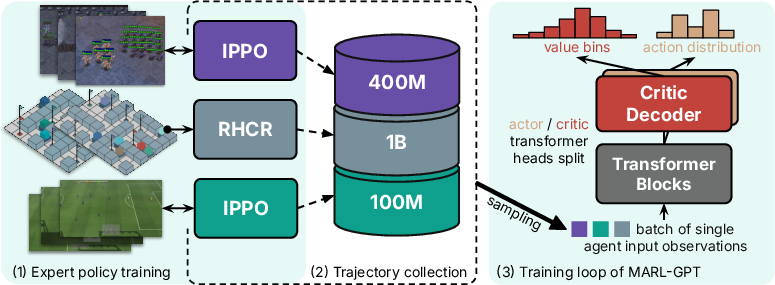
Figure 1: The training pipeline aggregates expert trajectories across environments, trains MARL-GPT on cross-entropy losses for actions and Q-values, and yields a model that generalizes over multiple domains and coordination types.
A critical innovation is the universal observation encoding scheme enabling the transformer backbone to process multimodal MARL inputs. Observations for each agent include not only raw features (such as local state, positions, and health) but are enriched with four positional embeddings: agent identity, team affiliation (group index), attribute type, and temporal timestep. These embeddings are summed with the raw tokens (learned projections of the feature vectors), producing a structured, permutation-invariant yet contextually aware embedding compatible with variable agent populations and environment layouts.
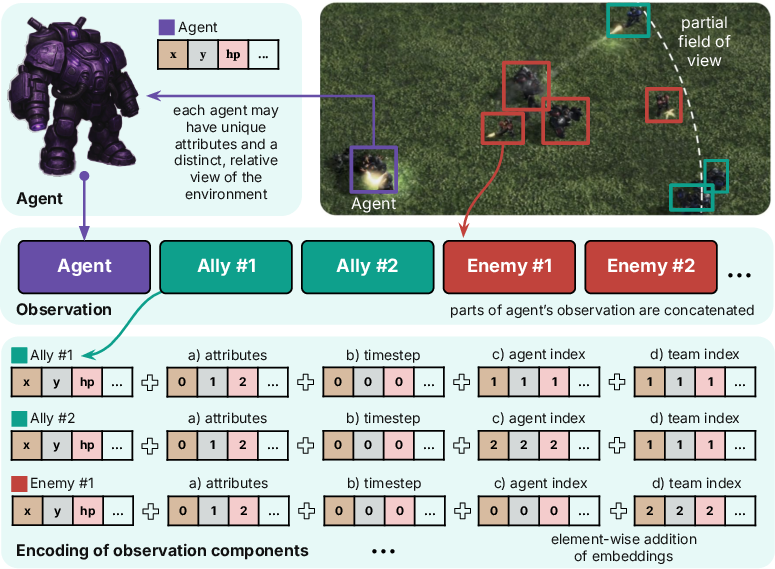
Figure 2: The encoding framework augments vectorized agent and environment features with structured positional embeddings, supporting role differentiation, variable populations, and group membership.
This encoding is critical for the model’s ability to seamlessly generalize over scenarios with varying numbers of agents, roles, team compositions, and temporal dependencies, and it circumvents the need for environment-specific architectures or feature engineering.
Training Objective and Offline-RL Framework
MARL-GPT is trained end-to-end using offline behavioral cloning and actor-critic RL objectives. The shared transformer encoder produces a latent representation for each agent's local observation. This latent is decoded into both policy logits and Q-values via dual output heads. The critic is trained discretely (using Q-value bins and cross-entropy loss) for greater numerical stability over standard regression, and incorporates conservative regularization to avoid overestimation on out-of-distribution actions. The actor combines advantage-weighted cross-entropy (policy gradient) loss and direct behavior cloning, ensuring imitation of expert behavior as well as value-driven optimization.
Action space heterogeneity is addressed using a universal transformer policy head and environment-specific masking, maintaining a unified parameterization.
Empirical Evaluation
Multi-Domain and Cross-Task Performance
Experiments are conducted on three fundamentally different multi-agent environments:
- SMACv2: Adversarial combat with variable numbers/types of units and coordination requirements;
- GRF: Temporal, high-dimensional soccer task with stochastic policies and specialized tactics;
- POGEMA: Cooperative multi-agent pathfinding, emphasizing scalable, conflict-free navigation.
Performance is evaluated against both specialized single-task baselines (including Behavior Cloning, Decision Transformer, CQL, LSTM-based variants) and environment-specific expert policies. MARL-GPT achieves win rates and throughput comparable to or surpassing custom models in most cases, including strong generalization to test scenarios differing from those observed during training. The spider plot below synthesizes performance across all settings:
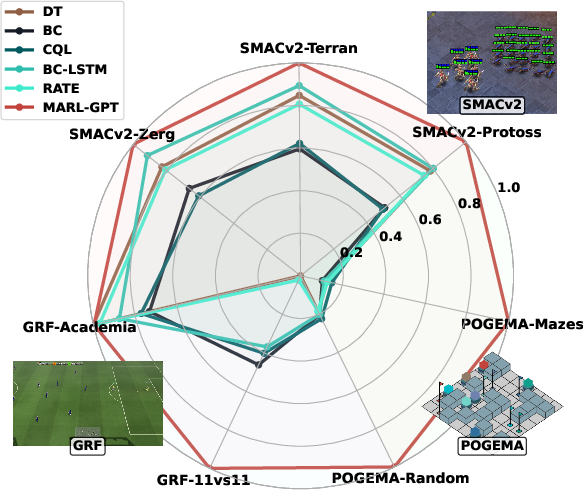
Figure 3: MARL-GPT achieves uniformly high performance across three heterogeneous MARL environments, matching or outperforming dedicated baselines.
Notably, the model can be fine-tuned online (with critic pretraining and PPO-style policy updates) for rapid adaptation to new tasks, yielding faster convergence and superior data efficiency compared to training from scratch.
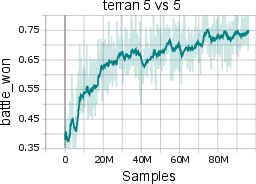
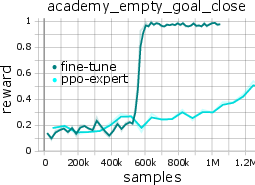
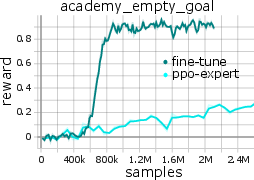
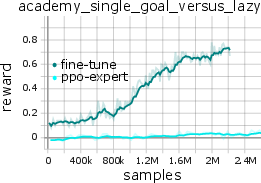
Figure 4: Online fine-tuning accelerates adaptation of MARL-GPT to unseen tasks, outperforming models retrained from scratch.
Robustness and Generalization
Ablation studies systematically examine the impact of model capacity, positional encoding, dataset scale, and history length. Notably, removal of the positional encoding or reduction in context length incurs significant drops in generalization and coordination. Training size and capacity are found to be non-saturating up to the largest configuration tested (7M parameters).
For POGEMA (multi-agent navigation), performance is close to centralized solvers and prior foundation models (MAPF-GPT), and the learned decentralized policy is successfully deployed on real JetBot robots in modular maze environments.

Figure 5: Modular real-world maze for multi-robot navigation constructed for physical deployment of MARL-GPT-trained policies.
Figure 6: Waveshare JetBot robots used for evaluation in physical settings.
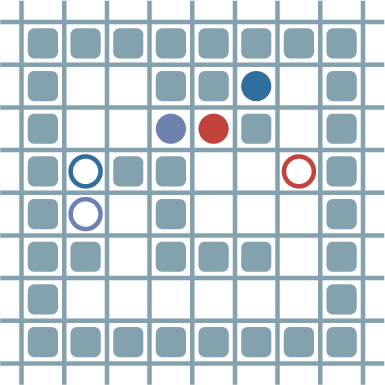
Figure 7: Side-by-side visualization of a POGEMA simulation and the corresponding real-world robot scenario.
Limitations and Failure Modes
MARL-GPT’s zero-shot transfer is presently restricted by explicit environment dependence of observation and action encoding schemes. For effective cross-domain transfer (for example, across completely different observation layouts or unaligned action semantics), further research on shared, systematic representations for features and actions is required. Additionally, high-quality expert trajectories remain a critical precondition; reward-based RL objectives lose effectiveness when demonstrations are near-optimal.
Theoretical and Practical Implications
MARL-GPT empirically validates the feasibility of generalist architectures for MARL, shifting away from narrowly specialized policy networks. The method demonstrates that with appropriate tokenization and architectural design, transformer models are capable of learning transferable agent–agent interaction priors, overcoming many-to-many mapping issues between agents, tasks, and team structures.
Practically, this reduces the engineering cost for scaling MARL to new domains, eliminates the necessity for separate policies, and provides a pathway toward a “multi-task foundation model” for complex agent systems. The offline RL formulation is well-aligned with industrial scenarios where expert demonstrations are available but continual online interaction is expensive or infeasible.
On the theoretical side, the strong results suggest that with sufficiently structured representations, permutation-invariant transformer-based architectures can interpolate over wide variations in state, action, and coordination requirements—a finding that will inform future work on the structure of policy and value representations in complex, heterogeneous multi-agent environments.
Speculation on Future Research
Immediate directions are the application of MARL-GPT-style architectures to input modalities beyond vector observations (e.g., vision and language), more systematic feature and action space alignment for rapid domain adaptation, and the combination of offline and online RL data streams for continual learning. Transfer to unseen, open-ended environments—without bespoke encoding—remains a central open problem.
Endowing models with architectural priors for explicit compositional reasoning over agent roles, communication, and team strategies is likely necessary for robust zero-shot deployment. The emergence of large, community-driven datasets and further progress in transformer throughput (e.g., via FlashAttention variants) will likely accelerate the scaling of MARL foundation models.
Conclusion
MARL-GPT constitutes a concrete advance toward generalist, task-agnostic policy models for MARL. Leveraging transformer architectures and universal observation encoding, it achieves competitive results across competitive, cooperative, and mixed-domain MARL tasks, and demonstrates effective transfer and adaptation through online fine-tuning. The open-sourced codebase and datasets establish a baseline for continued development of multi-agent foundation models, bridging the gap towards large-scale, robust, and generalizable agent learning systems.
Reference:
"MARL-GPT: Foundation Model for Multi-Agent Reinforcement Learning" (2604.05943)

