- The paper demonstrates that model-based agents, using value shaping and decision biasing, can effectively align their value and belief functions with expert behavior without heavy computational inference.
- It employs agent-based grid world simulations to compare model-based and model-free learning under various social information conditions, revealing robust performance and adaptability in dynamic environments.
- The study highlights practical implications for multi-agent systems and cultural transmission, suggesting a low-cost mechanism for efficient social learning.
Emergent Social Transmission of Model-Based Representations Without Inference
Introduction
The paper "Emergent social transmission of model-based representations without inference" (2604.05777) interrogates a central question in cultural cognition and reinforcement learning (RL): Can agents acquire flexible, high-level knowledge from others without engaging in computationally intensive Theory of Mind (ToM) inference? This work tests the hypothesis that social learning, instantiated through direct observation of expert behavior rather than explicit mental state inference, is sufficient for the transmission of rich model-based representations. The methodology leverages agent-based simulations, detailed computational modeling, and experimental manipulations of environmental structure, aiming to characterize both the efficacy and mechanistic underpinnings of this minimal social transmission.
Computational Framework and Learning Strategies
The authors employ a multi-quadrant grid world, with agents searching for variable rewards under stochastic observation noise. Critically, during training, learners observe an expert agent—which itself is a highly-trained model-based RL agent—while in testing, the expert is removed and environmental contingencies are manipulated. Six learning conditions are compared, crossing model-based (MB) and model-free (MF) backbone architectures with three modes of integrating social information: pure asocial learning (AS), decision-biasing (DB; policy-level imitation), and value shaping (VS; direct value augmentation).
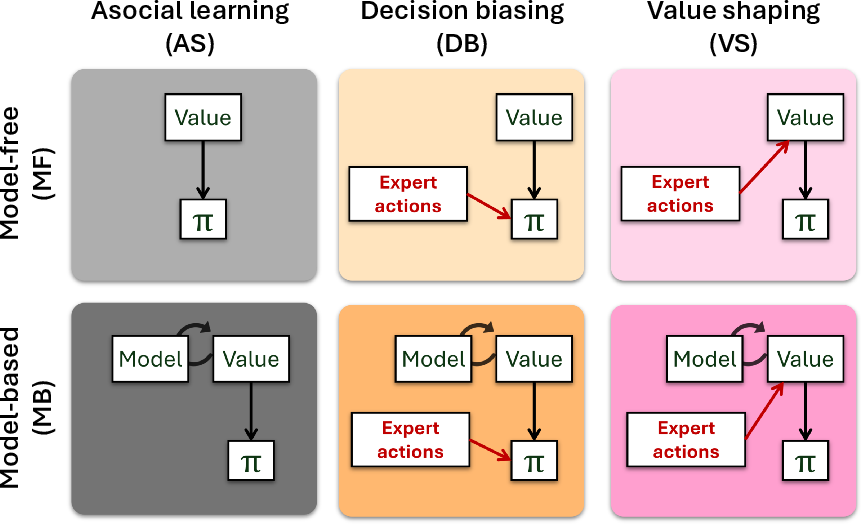
Figure 1: The six agent architectures comprise combinations of model-free/model-based learning with asocial, decision biasing, and value shaping integration.
Decision-biasing uses recent expert actions to tilt the agent's policy distribution, while value shaping imparts an explicit value bonus to directly observed expert state-action pairs. This distinction captures two main axes along which social learning can augment RL: shallow policy imitation versus deeper reward/value transfer.
Experimental Results
Baseline Social Transmission and Value/Belief Alignment
In the baseline, static environment (Exp. 1), social learners (both MB and MF, with DB or VS) consistently outperform asocial counterparts during training when the expert is present. Notably, VS agents—those which receive value-level augmentation—achieve superior overall reward accumulation compared both to DB and asocial agents. However, a crucial dissociation was observed in the test phase: while DB-MB and VS agents maintain their performance, DB-MF agents exhibit marked post-expert collapse, falling below even purely asocial MF agents.
Correlation analyses between agents’ value/belief functions and those of the expert substantiate the behavioral findings: VS and DB-MB agents acquire value and state transition representations closely resembling those of the expert, particularly in goal-relevant state spaces. In contrast, DB-MF agents’ representations diverge sharply after removal of the social signal.
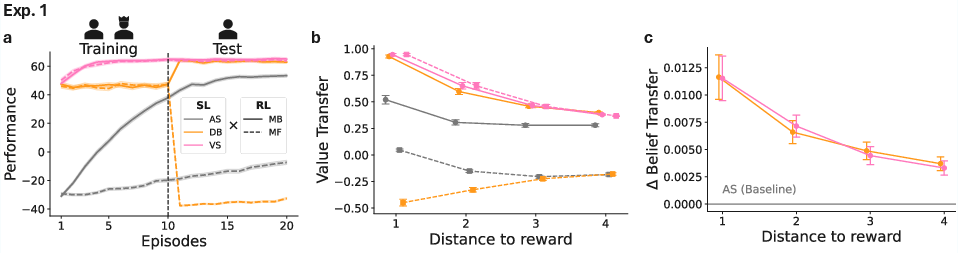
Figure 2: Cumulative reward trajectories and representational alignment metrics demonstrate robust transfer for model-based social learners and fragility for model-free policy-based learners.
Robustness to Environmental Changes
Further experiments stress test generalization: Exp. 2 swaps reward locations in the test phase, and Exp. 3 changes starting positions. Model-based social learners (VS-MB, DB-MB) adapt rapidly, re-synchronizing both value representations and cumulative reward to near-training levels. VS agents consistently demonstrate the highest value function correlation with post-change optima. Conversely, model-free DB agents (DB-MF) fail to generalize, with value representations that do not track optimality after the expert’s departure or reward repositioning.
Belief transfer analysis in Exp. 3 reveals that model-based social agents not only recover but preserve high-fidelity models of transition structure across such spatial perturbations, with residual variability in belief representation notably lower for VS-MB and DB-MB compared to asocial or DB-MF agents.
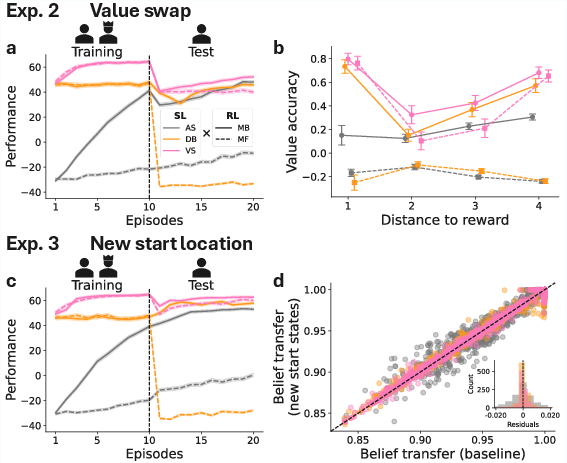
Figure 3: Performance and representational analyses under novel reward contingencies and start positions reveal the adaptive advantage and robustness of model-based social strategies, particularly value shaping.
Theoretical and Practical Implications
This research departs from conventional ToM/inverse RL narratives by formalizing conditions under which higher-level knowledge transmission does not require inference over others' goals or beliefs. Instead, straightforward value propagation or local policy biases, when coupled with model-based RL mechanisms, are sufficient for indirect acquisition of abstract knowledge—both in value space and environmental structure.
This finding has several implications:
- Efficiency of Social Learning: Direct inference of others’ mental models is computationally expensive; the demonstrated minimal social learning mechanisms offer a biologically and algorithmically parsimonious alternative.
- Cultural Transmission: These mechanisms support a computational basis for the emergence and accumulation of culture—potentially explaining interspecies differences in imitation, as seen in the literature on over-imitation in humans versus emulation in non-human primates.
- Engineering Applications: In multi-agent AI/robotics, model-based value shaping could provide a template for scalable demonstration learning without the need for full expert reward inference, simplifying social pre-training in physically or informationally complex domains.
Future Directions
Outstanding open questions include the role of non-mentalizing transmission in even less stable environments (e.g., with manipulated wall/transition dynamics), the impact of pedagogically optimized demonstrations, and systematic experimental validation with human subjects. Additionally, theoretically, the trade-off structure between various social learning strategies across different RL architectures merits detailed analysis, especially in relation to the statistical complexity of the underlying environment.
Conclusion
The paper demonstrates that model-based RL agents can achieve robust, flexible social transmission of high-level value and belief representations through minimal social heuristics, avoiding costly explicit inference of others' mental states. These findings formalize a potent, low-cost mechanism supporting cultural learning and highlight the interaction between the representational substrate of RL and the mode of social informational integration. The research suggests that the adaptive advantage of human over-imitation may lie less with cognitive sophistication and more with the ability to leverage internal world models in the presence of simple observational cues.

