- The paper introduces Adaptive Material Fingerprinting (AMF) for fast, interpretable discovery of polyconvex constitutive models in hyperelastic solids.
- It employs a combinatorial database of parametrized, physically-constrained feature functions and an iterative pattern recognition algorithm to build sparse models.
- Numerical experiments on isotropic rubber and anisotropic skin demonstrate high accuracy (R² up to 0.99) while preserving essential physical properties.
Adaptive Material Fingerprinting for Polyconvex Feature Discovery in Hyperelasticity
Overview
The paper "Adaptive Material Fingerprinting for the fast discovery of polyconvex feature combinations in isotropic and anisotropic hyperelasticity" (2604.05698) introduces an adaptive, combinatorial approach to material model discovery for hyperelastic solids. The method, termed Adaptive Material Fingerprinting (AMF), is an extension of previous lookup-table fingerprinting methodologies, designed to enable efficient and interpretable identification of complex, physically-admissible constitutive models without continuous optimization. Major advances include a feature-combinatorial search algorithm, a database of parametric physically-constrained features (admitting polyconvexity), and an iterative pattern recognition framework for model construction.
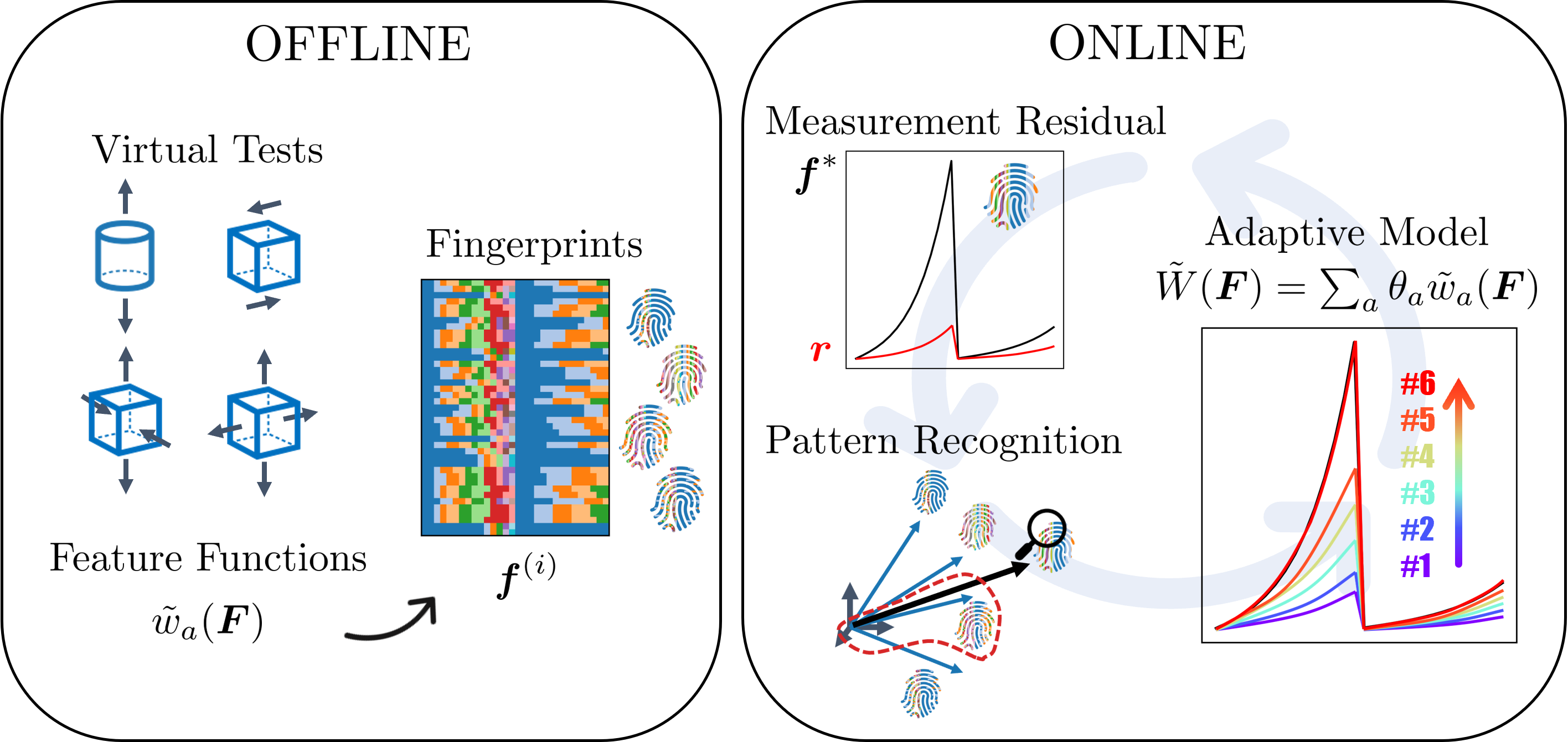
Figure 1: Workflow of adaptive Material Fingerprinting: an offline phase computes feature model responses and stores them, while an online phase iteratively constructs a sparse model to fit experimental fingerprints.
Motivation and Context
Traditional parameter identification in nonlinear elasticity relies on the selection of a constitutive model and a subsequent (potentially nonconvex and high-dimensional) optimization to fit experimental data. Recent advances in machine learning for constitutive modeling—such as neural network surrogates and symbolic regression—alleviate the need for a priori selection of model form, offering flexibility but often at the cost of interpretability, physical admissibility, and computational efficiency. These ML models typically require stress-strain data and expensive training processes.
The original Material Fingerprinting approach circumvented continuous optimization by working with a precomputed database of material response “fingerprints,” but was limited to fixed model sets. Adaptive Material Fingerprinting lifts this restriction by allowing linear combinations of database entries, thus enabling discovery of multi-feature, physically constrained models.
Methodology
Database Construction
Feature functions—forming the basis of candidate strain energies—are constructed using invariants of deformation, including principal stretches/areas for isotropy and fiber-directional quantities for anisotropy. The precomputed database stores the stress response ("fingerprint") of each feature function evaluated across a range of deformation protocols (uniaxial, shear, equibiaxial, etc.), with relevant parameter sweeps.

Figure 2: Standardized deformation protocols used for fingerprinting, parameterized by principal stretches under incompressibility constraints.
Specific forms for the isotropic and anisotropic features use well-known classes of functions (e.g., powers, exponential, softplus-type) that subsume classical models such as the Ogden and Holzapfel-Gasser-Ogden formulations, with parameter ranges chosen to ensure a flexible and rich basis. For polyconvexity, parameter constraints are enforced such that feature convexity in singular values is guaranteed.
Pattern Recognition and Model Building
Material discovery is treated as an adaptive, greedy feature selection problem. After experimental stress data is interpolated and normalized to match the database deformation grid, AMF iteratively constructs a model:
- Initialization: The strain energy density starts as zero.
- Residual Computation: At each step, the residual between the experimental response and the current model is computed.
- Feature Selection: The database entry whose fingerprint best matches the normalized residual is identified (maximal inner product).
- Model Update: The selected feature is added to the strain energy, weighted by a determined scaling parameter.
- Iteration: Steps 2–4 repeat for a user-prescribed number of features (na), controlling model sparsity.
A key hyperparameter s modulates the update strength at each step. The final model is a sum of up to na feature terms, yielding a sparse, interpretable constitutive law.
Numerical and Experimental Results
Isotropic Rubber
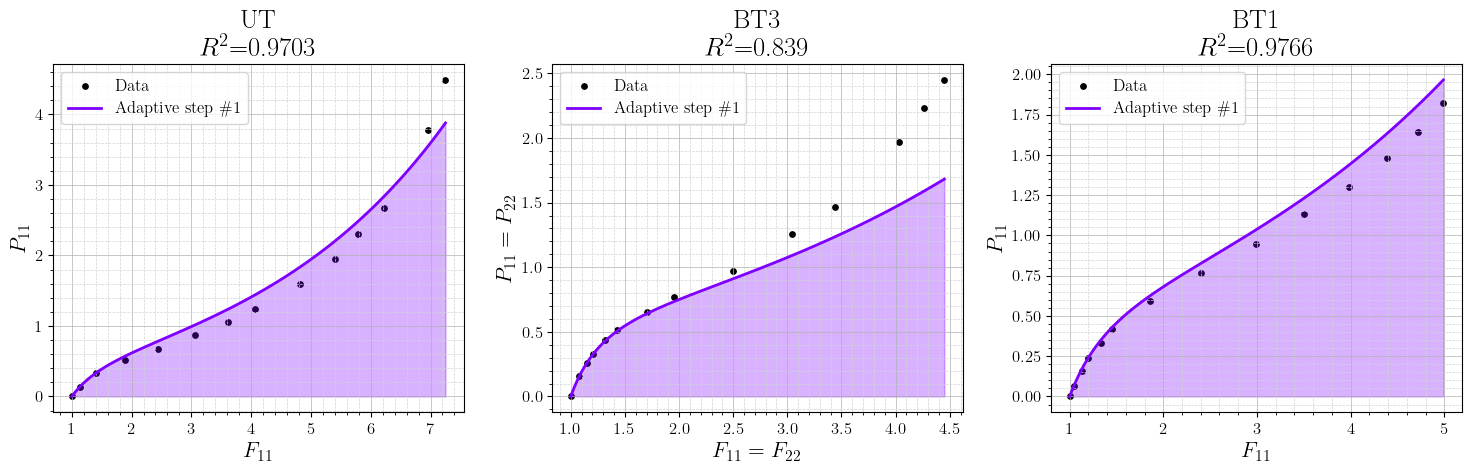
Experiments on Treloar rubber data at two temperatures showcase the progression of model fit as na increases:
- na=1:
- Single-feature (exponential stretch) model captures qualitative trends with R2=0.93.
- na=3 and above:
Anisotropic Skin
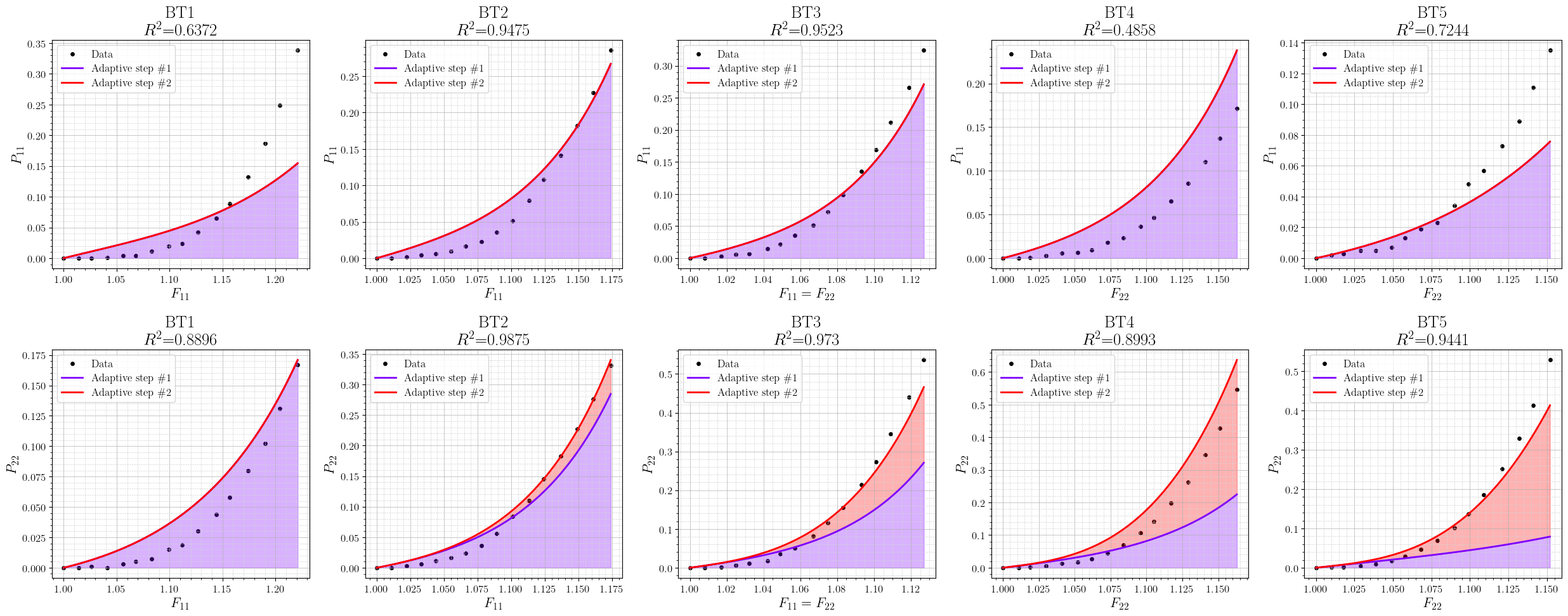
Application to porcine skin data demonstrates necessity of anisotropic features:
- na=1:
- Isotropic-only model yields poor fit (s0).
- s1:
- The addition of a single anisotropic term (fiber stretch-based feature) improves s2.
- s3 or more:
Hyperparameter Sensitivity and Polyconvexity
Systematic scanning reveals that moderate s7 and s8–s9 balances accuracy and sparsity. Enforcing polyconvexity yields no loss in fit for rubber data; for skin, a small decrease in na0 is observed when polyconvex features are enforced, supporting the practical utility of the approach for robust model discovery.
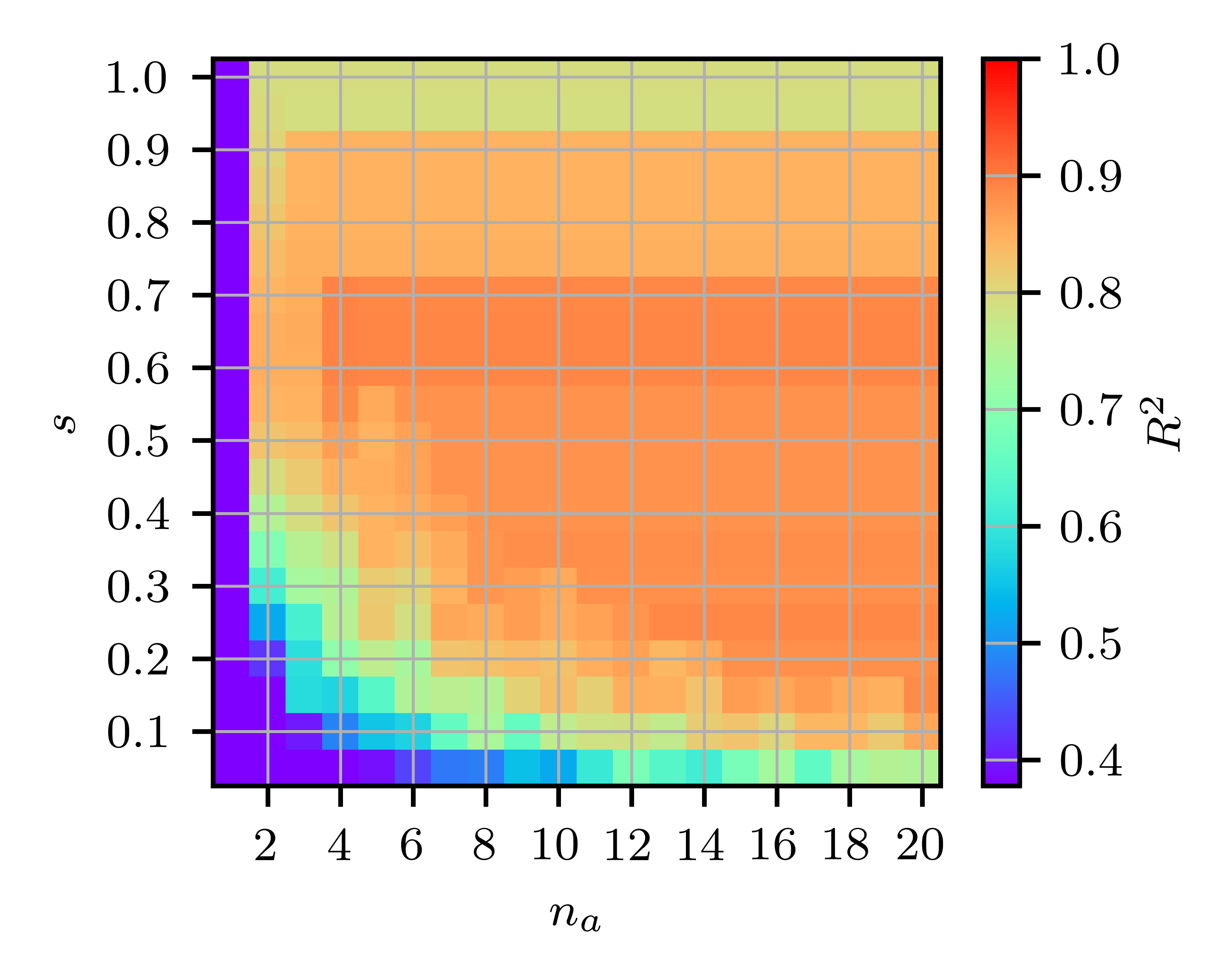
Figure 5: Hyperparameter heatmap for na1 and na2 showing their effect on goodness of fit for skin tissue data.
Theoretical and Practical Implications
Theoretical Advantages
The AMF framework retains physical admissibility—objectivity, stress-free reference, symmetry, and polyconvexity—by feature construction and database constraint. The pattern recognition-based selection obviates the need for nonlinear, potentially ill-posed optimization, and always yields a valid model from the candidate set.
By mimicking forward stepwise regression but leveraging a database of physically-constrained, parametrized features, AMF avoids overfitting and provides transparent trade-offs between sparsity and fit. The explicit, interpretable functional forms discovered are distinct from typical “black-box” ML surrogates and aid mechanism identification.
Comparison to Machine Learning Methods
Direct comparison to ANN-based constitutive modeling [martonova_generalized_2025], [linka_automated_2023-1] shows that AMF achieves similar na3 values without the overhead of training or the interpretability problems of neural networks. Unlike CANNs or other surrogate models, AMF does not require stress labels and is compatible with “physics-only” fingerprints.
Practical Utility
AMF is suitable for rapid experimental model identification, especially in contexts where interpretability, thermodynamic consistency, or computational efficiency are required (e.g., automated characterization in biomedical or soft robotics, digital twin applications). The separation into offline/online stages makes the approach scalable and reusable.
Future Outlook
Further extensions include enlarging the fingerprint database to cover a richer set of features (e.g., incorporating strain-gradient or viscoelastic terms), automated hyperparameter tuning for unsupervised model complexity selection, and end-to-end integration with digital image correlation or full-field experimental data (potentially extending beyond homogeneous deformations).
Integration with symbolic regression and Bayesian uncertainty estimation for model selection may enable further interpretability and robustness advances, enhancing predictive capabilities in material informatics workflows.
Conclusion
Adaptive Material Fingerprinting (2604.05698) provides a robust, interpretable, and physically-constrained framework for data-driven constitutive model discovery. Its iterative, combinatorial, and database-driven architecture enables discovery of sparse, accurate models efficiently, sidestepping the nonconvex optimization bottleneck of traditional and machine learning approaches. Applications to complex, anisotropic, and polyconvex materials underline its versatility and potential as a reliable tool in automated material characterization and computational mechanistic modeling.