- The paper introduces a novel integration of LLM-guided semantic extraction and topological graph reasoning to accurately segment pulmonary images.
- It employs cascaded zero-shot candidate generation and a graph transformer to refine segmentation, achieving improved Dice scores on challenging datasets.
- The selective asymmetric fine-tuning (SAFT) strategy reduces trainable parameters to under 1%, ensuring robust performance and stability in clinical deployment.
Semantic-Topological Graph Reasoning for Language-Guided Pulmonary Screening: An Expert Analysis
Introduction
The paper "Semantic-Topological Graph Reasoning for Language-Guided Pulmonary Screening" (2604.05620) addresses critical limitations of existing multimodal and foundation models in medical image segmentation, especially in the context of ambiguous, low-contrast pulmonary radiographs with complex anatomical overlaps. The authors present a new framework that leverages LLM-driven linguistic priors, vision foundation models, and structural graph reasoning to produce accurate, clinically-aligned segmentations under resource constraints. This essay provides a detailed summary and technical scrutiny of the methodology, empirical findings, and broader implications of the work.
Framework Overview
The proposed pipeline integrates three main components: (1) Text-to-Vision Intent Distillation (TVID) using LLaMA-3-V, (2) MedSAM-based candidate mask generation, and (3) collaborative graph-structured reasoning for mask selection.
Figure 1: The overall framework of the language-guided pulmonary segmentation model, comprising semantic generation by LLaMA-3-V, candidate mask generation from MedSAM, and final graph-based mask disambiguation.
This modular approach is motivated by the need for both precise language grounding (to parse nuanced clinical instructions) and topological reasoning (to resolve overlapping tissues), while enforcing computational and statistical efficiency suitable for clinical adaptation.
Methodology
Text-to-Vision Intent Distillation (TVID)
TVID extracts granular diagnostic semantics from clinical text using an adapted LLaMA-3-V, which parses instructions into multiple pathology-specific attribute vectors. Through a learnable non-linear projection, these semantic vectors are embedded into visual feature space, furnishing the downstream vision model with explicit task intent. This design addresses the gap between free-form, ambiguous clinical instruction and deterministic, pixel-level segmentation.
Lesion Candidate Generation
A cascaded zero-shot approach is applied, with bounding regions of interest first localized via a medical-tuned GroundingDINO, then translated into candidate segmentation masks using MedSAM. Each mask is encoded with DINOv2-based visual features, producing a comprehensive pool of candidate regions that may be redundant or noisy.
Semantic-Topological Graph Reasoning (STGR)
The core innovation is the formulation of mask selection as a dynamic graph reasoning task. Candidate masks serve as nodes, and graph edges are constructed using a learnable affinity that aggregates both spatial overlap (IoU) and semantic similarity (feature cosine). A multi-layer graph transformer first performs self-attention-based context aggregation, followed by cross-attention injection of the linguistic semantic guidance from TVID. This iterative process sharpens instance-level features by jointly considering anatomical topology and diagnosis intent, culminating in an MLP-based classification and selection of high-confidence regions.
Selective Asymmetric Fine-Tuning (SAFT)
To adapt massive vision and language backbones (LLaMA-3-V, MedSAM, DINOv2) on data-limited medical datasets, the authors introduce an ultra-efficient parameter-efficient fine-tuning regime. All model backbones are frozen; only low-rank adapters and projection heads are updated, constraining the number of trainable parameters to <1%. This acts as a strong regularizer, reducing overfitting and enabling stable multi-fold cross-validation outcomes.
Experimental Results
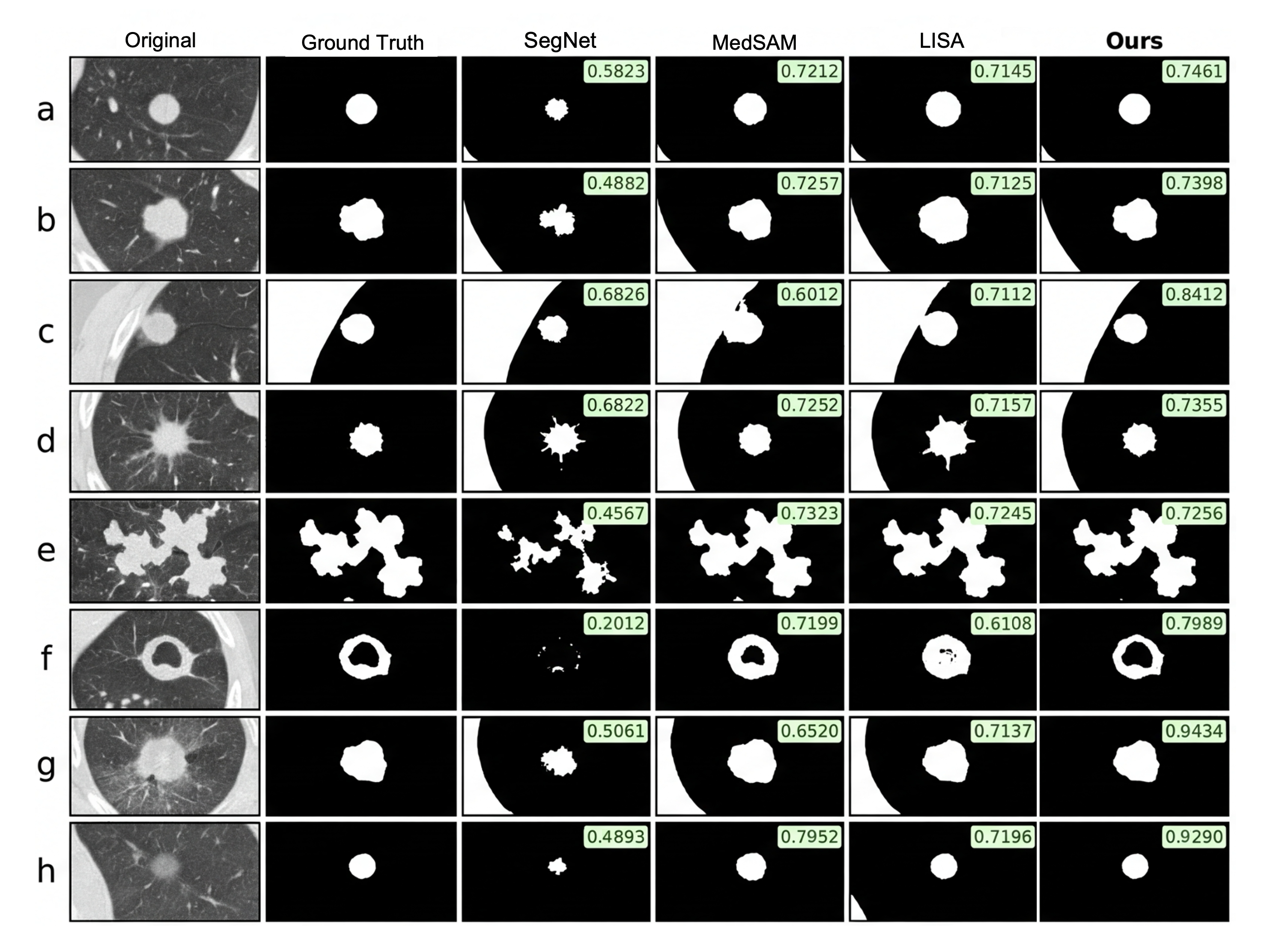
Rigorous 5-fold cross-validation was conducted on two challenging datasets: LIDC-IDRI (nodule and opacity segmentation) and LNDb (varied pathology). The primary metrics are IoU and Dice Similarity Coefficient (DSC).
The proposed full framework with SAFT achieves an 81.5% DSC on LIDC-IDRI, outperforming LISA by 5.3% and MedSAM by 11.2%; for LNDb, a 74.6% DSC is reported. Notably, the model exhibits strong fold-wise stability, with a standard deviation of only ±0.6% in DSC, highlighting its robustness compared to models prone to high variance from overfitting.
Ablation studies underscore the aggregate contribution of each module:
Qualitative analysis further demonstrates improved boundary delineation in complex cases, especially when compared to U-Net, SegNet, or conventional foundation models, which often underperform on irregular or highly overlapping lesions.
Theoretical and Practical Implications
This work advances the state of language-guided medical segmentation by explicitly modeling semantic intent alignment and topological regularity. The integration of graph reasoning addresses a critical mode of failure—namely, the misclassification of spatially ambiguous or texturally similar anatomical regions, which are inadequately handled by conventional convolutional or vision-language transformers alone. The parameter-efficient adaptation route is especially pertinent for clinical deployment, where large-scale retraining is often infeasible due to annotation and compute bottlenecks.
From a theoretical perspective, the multi-level fusion of modality-specific representations and dynamic graph attention offers a blueprint for other context-sensitive, multimodal medical workflows that must resolve both semantic and structural ambiguity.
Limitations and Future Directions
While the presented framework demonstrates substantial improvements, its reliance on high-fidelity, human-authored text prompts constrains end-to-end automation. As acknowledged by the authors, future work should focus on robust integration with automated clinical report generation and extend the STGR model to volumetric (3D) segmentation for full CT-scale topological reasoning. Exploration of even more scalable parameter-efficient fine-tuning strategies could further democratize deployment in settings with diverse scanner protocols and patient populations.
Conclusion
"Semantic-Topological Graph Reasoning for Language-Guided Pulmonary Screening" establishes a robust paradigm for free-text prompted, context-aware medical segmentation. By fusing LLM-guided intent, foundation vision models, and structural graph attention—all under a highly efficient optimization regime—the framework demonstrates both state-of-the-art performance and exceptional deployment stability on challenging pulmonary datasets. The technical innovations and empirical findings of this work will likely inform subsequent research in multimodal, instruction-tuned CAD systems and graph-based medical AI.